 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObserving Trends in Automated Multilingual Media Analysis
Mar 08, 2016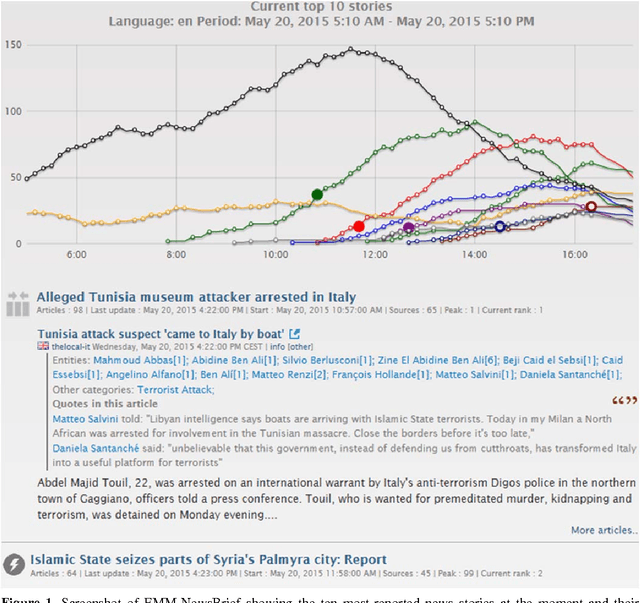
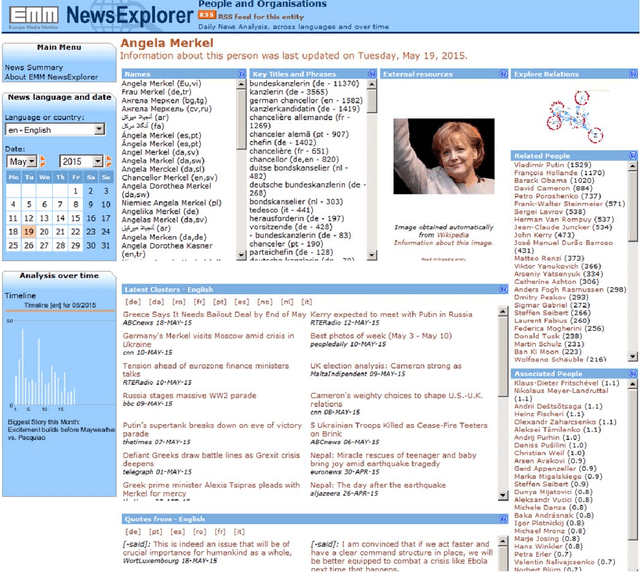
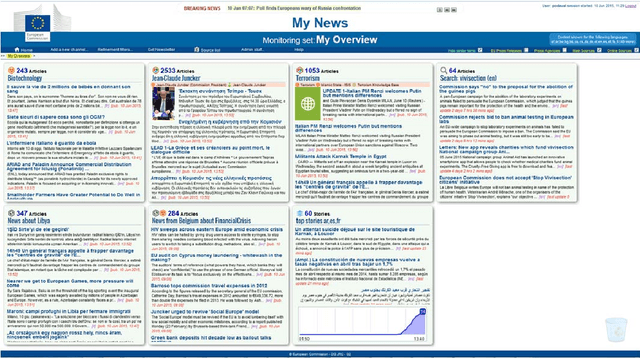
Any large organisation, be it public or private, monitors the media for information to keep abreast of developments in their field of interest, and usually also to become aware of positive or negative opinions expressed towards them. At least for the written media, computer programs have become very efficient at helping the human analysts significantly in their monitoring task by gathering media reports, analysing them, detecting trends and - in some cases - even to issue early warnings or to make predictions of likely future developments. We present here trend recognition-related functionality of the Europe Media Monitor (EMM) system, which was developed by the European Commission's Joint Research Centre (JRC) for public administrations in the European Union (EU) and beyond. EMM performs large-scale media analysis in up to seventy languages and recognises various types of trends, some of them combining information from news articles written in different languages and from social media posts. EMM also lets users explore the huge amount of multilingual media data through interactive maps and graphs, allowing them to examine the data from various view points and according to multiple criteria. A lot of EMM's functionality is accessibly freely over the internet or via apps for hand-held devices.
Sentiment Analysis in the News
Sep 24, 2013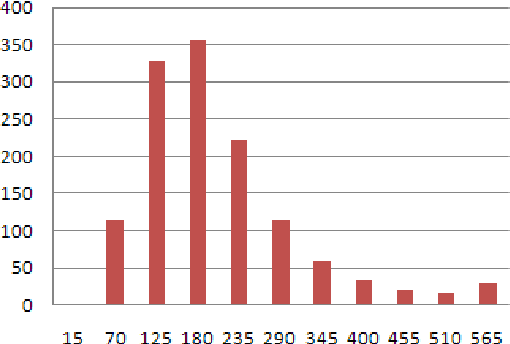
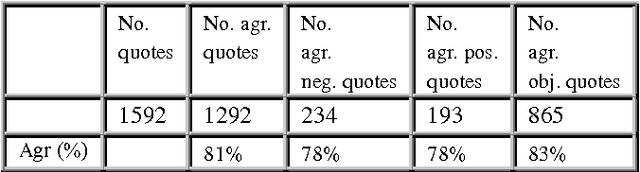
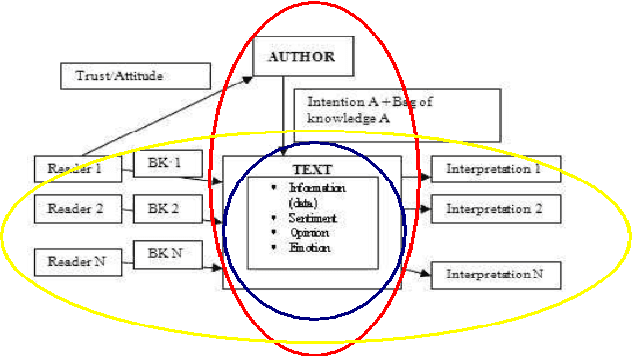
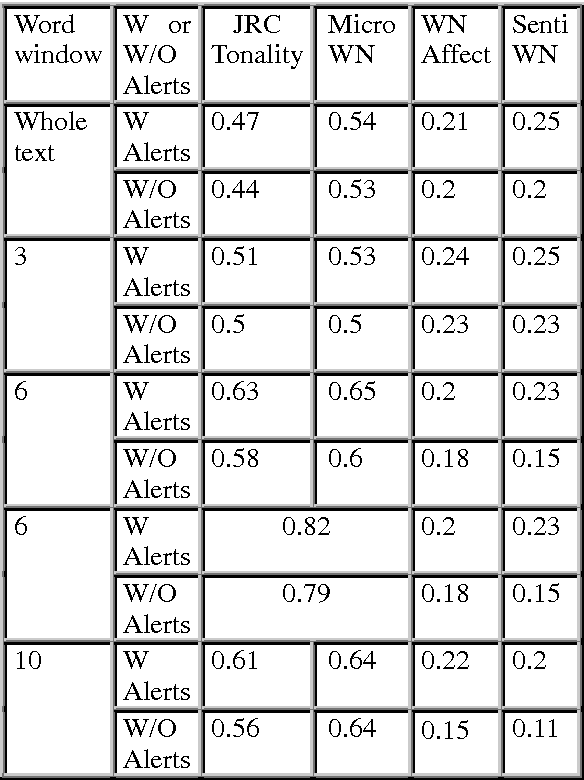
Recent years have brought a significant growth in the volume of research in sentiment analysis, mostly on highly subjective text types (movie or product reviews). The main difference these texts have with news articles is that their target is clearly defined and unique across the text. Following different annotation efforts and the analysis of the issues encountered, we realised that news opinion mining is different from that of other text types. We identified three subtasks that need to be addressed: definition of the target; separation of the good and bad news content from the good and bad sentiment expressed on the target; and analysis of clearly marked opinion that is expressed explicitly, not needing interpretation or the use of world knowledge. Furthermore, we distinguish three different possible views on newspaper articles - author, reader and text, which have to be addressed differently at the time of analysing sentiment. Given these definitions, we present work on mining opinions about entities in English language news, in which (a) we test the relative suitability of various sentiment dictionaries and (b) we attempt to separate positive or negative opinion from good or bad news. In the experiments described here, we tested whether or not subject domain-defining vocabulary should be ignored. Results showed that this idea is more appropriate in the context of news opinion mining and that the approaches taking this into consideration produce a better performance.
JRC-Names: A freely available, highly multilingual named entity resource
Sep 24, 2013
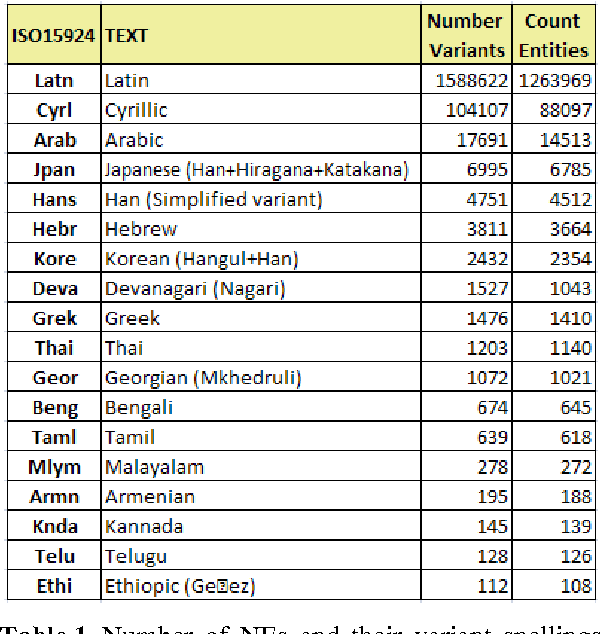

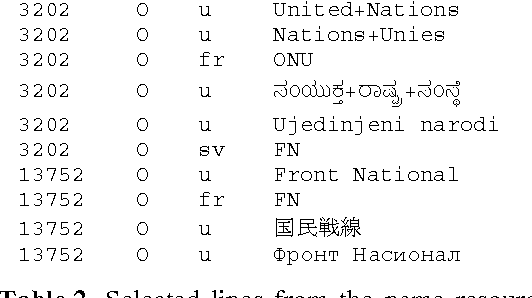
This paper describes a new, freely available, highly multilingual named entity resource for person and organisation names that has been compiled over seven years of large-scale multilingual news analysis combined with Wikipedia mining, resulting in 205,000 per-son and organisation names plus about the same number of spelling variants written in over 20 different scripts and in many more languages. This resource, produced as part of the Europe Media Monitor activity (EMM, http://emm.newsbrief.eu/overview.html), can be used for a number of purposes. These include improving name search in databases or on the internet, seeding machine learning systems to learn named entity recognition rules, improve machine translation results, and more. We describe here how this resource was created; we give statistics on its current size; we address the issue of morphological inflection; and we give details regarding its functionality. Updates to this resource will be made available daily.
An introduction to the Europe Media Monitor family of applications
Sep 20, 2013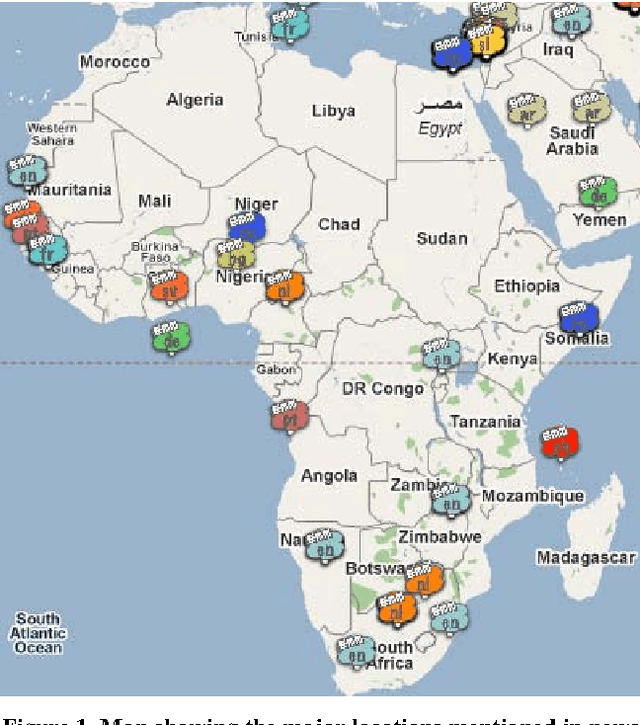
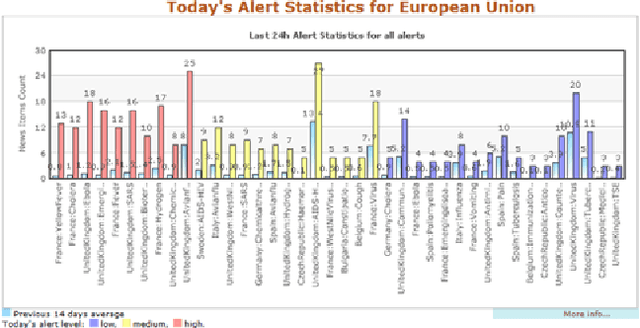

Most large organizations have dedicated departments that monitor the media to keep up-to-date with relevant developments and to keep an eye on how they are represented in the news. Part of this media monitoring work can be automated. In the European Union with its 23 official languages, it is particularly important to cover media reports in many languages in order to capture the complementary news content published in the different countries. It is also important to be able to access the news content across languages and to merge the extracted information. We present here the four publicly accessible systems of the Europe Media Monitor (EMM) family of applications, which cover between 19 and 50 languages (see http://press.jrc.it/overview.html). We give an overview of their functionality and discuss some of the implications of the fact that they cover quite so many languages. We discuss design issues necessary to be able to achieve this high multilinguality, as well as the benefits of this multilinguality.