 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting multilingual nomenclatures and language-independent text features as an interlingua for cross-lingual text analysis applications
Paper and Code
Sep 12, 2006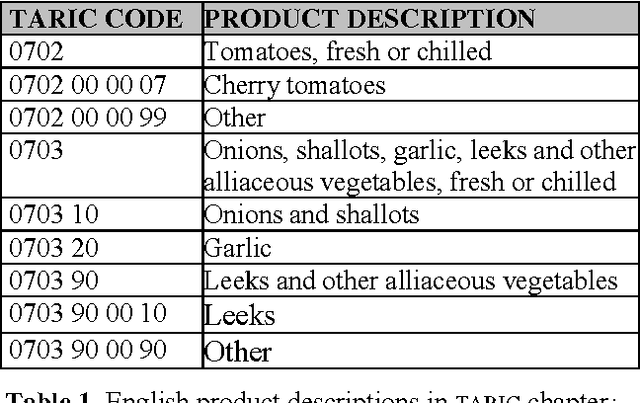
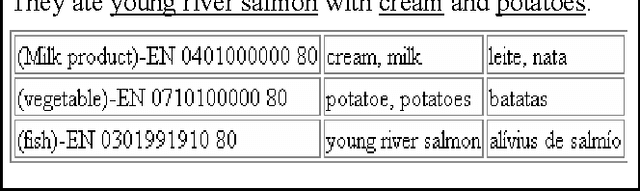
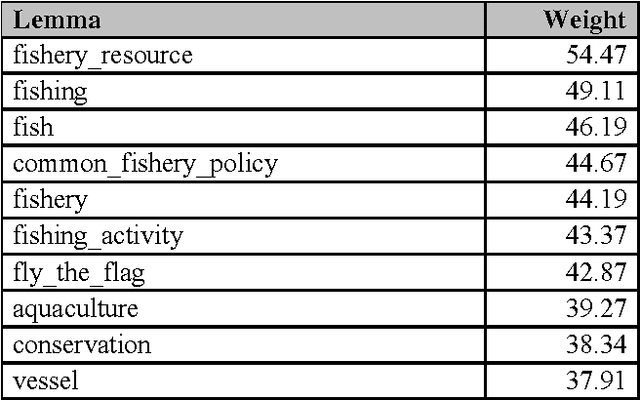

We are proposing a simple, but efficient basic approach for a number of multilingual and cross-lingual language technology applications that are not limited to the usual two or three languages, but that can be applied with relatively little effort to larger sets of languages. The approach consists of using existing multilingual linguistic resources such as thesauri, nomenclatures and gazetteers, as well as exploiting the existence of additional more or less language-independent text items such as dates, currency expressions, numbers, names and cognates. Mapping texts onto the multilingual resources and identifying word token links between texts in different languages are basic ingredients for applications such as cross-lingual document similarity calculation, multilingual clustering and categorisation, cross-lingual document retrieval, and tools to provide cross-lingual information access.