 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe JRC-Acquis: A multilingual aligned parallel corpus with 20+ languages
Sep 12, 2006

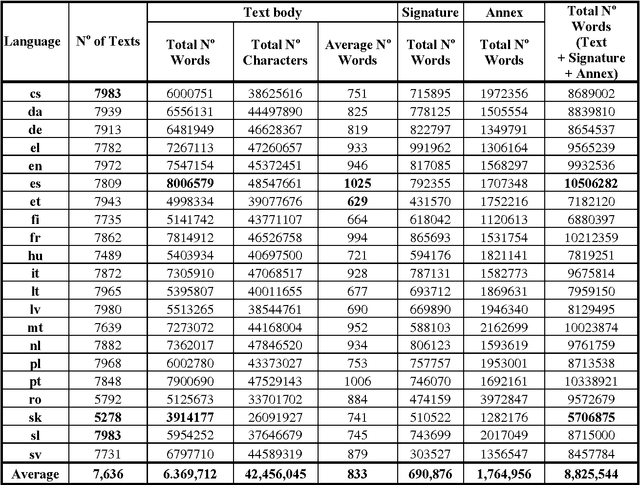

We present a new, unique and freely available parallel corpus containing European Union (EU) documents of mostly legal nature. It is available in all 20 official EUanguages, with additional documents being available in the languages of the EU candidate countries. The corpus consists of almost 8,000 documents per language, with an average size of nearly 9 million words per language. Pair-wise paragraph alignment information produced by two different aligners (Vanilla and HunAlign) is available for all 190+ language pair combinations. Most texts have been manually classified according to the EUROVOC subject domains so that the collection can also be used to train and test multi-label classification algorithms and keyword-assignment software. The corpus is encoded in XML, according to the Text Encoding Initiative Guidelines. Due to the large number of parallel texts in many languages, the JRC-Acquis is particularly suitable to carry out all types of cross-language research, as well as to test and benchmark text analysis software across different languages (for instance for alignment, sentence splitting and term extraction).
* A multilingual textual resource with meta-data freely available for download at http://langtech.jrc.it/JRC-Acquis.html