 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic annotation of multilingual text collections with a conceptual thesaurus
Paper and Code
Sep 12, 2006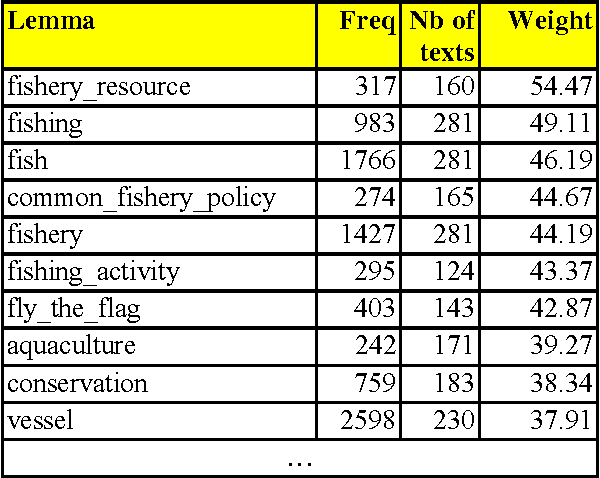
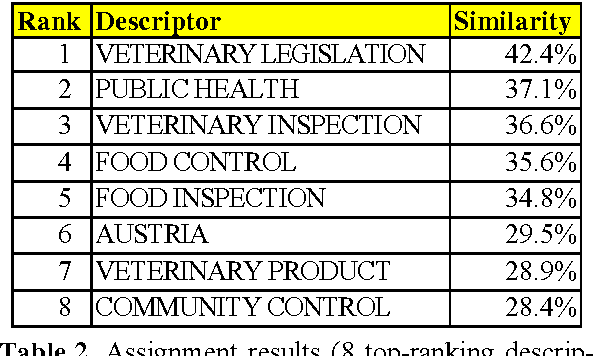
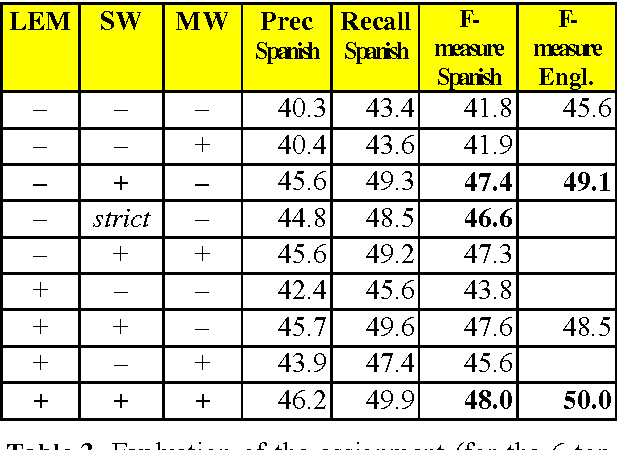
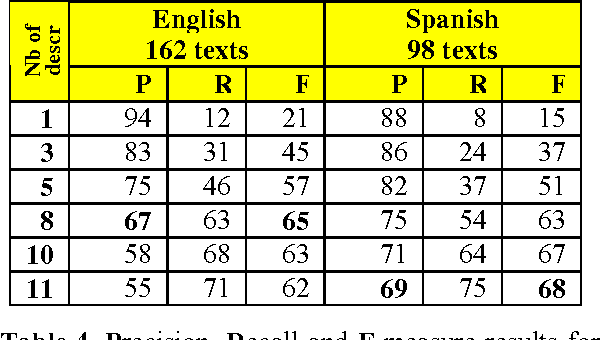
Automatic annotation of documents with controlled vocabulary terms (descriptors) from a conceptual thesaurus is not only useful for document indexing and retrieval. The mapping of texts onto the same thesaurus furthermore allows to establish links between similar documents. This is also a substantial requirement of the Semantic Web. This paper presents an almost language-independent system that maps documents written in different languages onto the same multilingual conceptual thesaurus, EUROVOC. Conceptual thesauri differ from Natural Language Thesauri in that they consist of relatively small controlled lists of words or phrases with a rather abstract meaning. To automatically identify which thesaurus descriptors describe the contents of a document best, we developed a statistical, associative system that is trained on texts that have previously been indexed manually. In addition to describing the large number of empirically optimised parameters of the fully functional application, we present the performance of the software according to a human evaluation by professional indexers.