 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIESR: Nuisance Invariant End-to-end Speech Recognition
Paper and Code
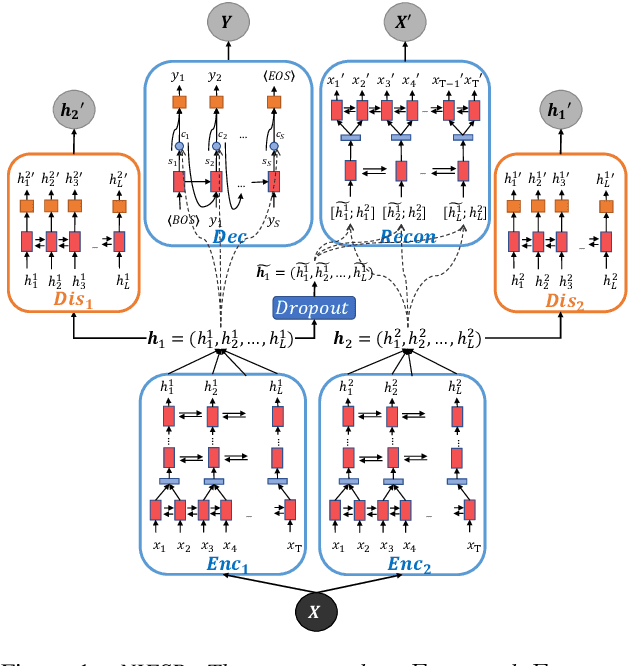

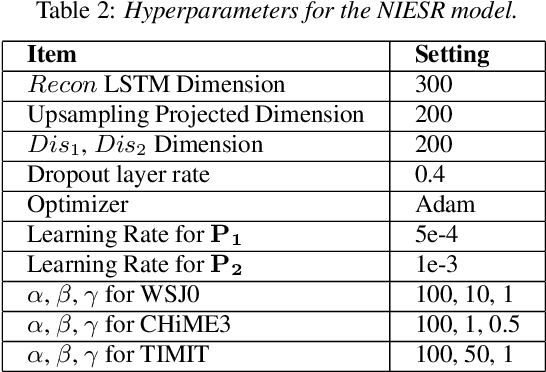
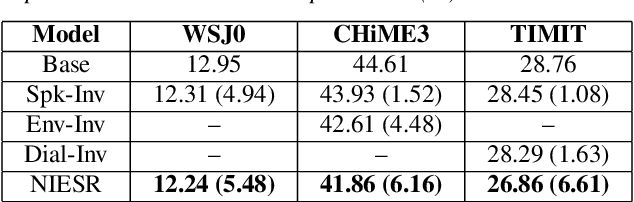
Deep neural network models for speech recognition have achieved great success recently, but they can learn incorrect associations between the target and nuisance factors of speech (e.g., speaker identities, background noise, etc.), which can lead to overfitting. While several methods have been proposed to tackle this problem, existing methods incorporate additional information about nuisance factors during training to develop invariant models. However, enumeration of all possible nuisance factors in speech data and the collection of their annotations is difficult and expensive. We present a robust training scheme for end-to-end speech recognition that adopts an unsupervised adversarial invariance induction framework to separate out essential factors for speech-recognition from nuisances without using any supplementary labels besides the transcriptions. Experiments show that the speech recognition model trained with the proposed training scheme achieves relative improvements of 5.48% on WSJ0, 6.16% on CHiME3, and 6.61% on TIMIT dataset over the base model. Additionally, the proposed method achieves a relative improvement of 14.44% on the combined WSJ0+CHiME3 dataset.