 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Multi-Agent Navigation guided by Goal-Conditioned Safe Reinforcement Learning
Feb 25, 2025Safe navigation is essential for autonomous systems operating in hazardous environments. Traditional planning methods excel at long-horizon tasks but rely on a predefined graph with fixed distance metrics. In contrast, safe Reinforcement Learning (RL) can learn complex behaviors without relying on manual heuristics but fails to solve long-horizon tasks, particularly in goal-conditioned and multi-agent scenarios. In this paper, we introduce a novel method that integrates the strengths of both planning and safe RL. Our method leverages goal-conditioned RL and safe RL to learn a goal-conditioned policy for navigation while concurrently estimating cumulative distance and safety levels using learned value functions via an automated self-training algorithm. By constructing a graph with states from the replay buffer, our method prunes unsafe edges and generates a waypoint-based plan that the agent follows until reaching its goal, effectively balancing faster and safer routes over extended distances. Utilizing this unified high-level graph and a shared low-level goal-conditioned safe RL policy, we extend this approach to address the multi-agent safe navigation problem. In particular, we leverage Conflict-Based Search (CBS) to create waypoint-based plans for multiple agents allowing for their safe navigation over extended horizons. This integration enhances the scalability of goal-conditioned safe RL in multi-agent scenarios, enabling efficient coordination among agents. Extensive benchmarking against state-of-the-art baselines demonstrates the effectiveness of our method in achieving distance goals safely for multiple agents in complex and hazardous environments. Our code will be released to support future research.
Federated Self-Supervised Learning for Acoustic Event Classification
Mar 22, 2022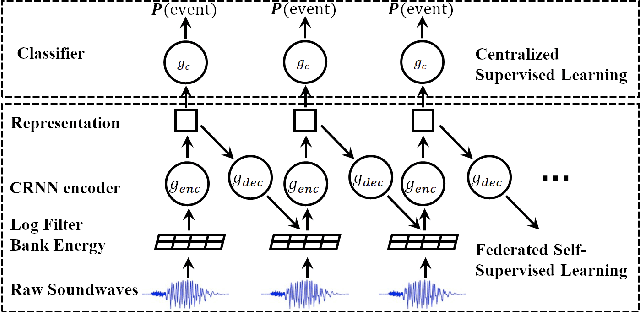

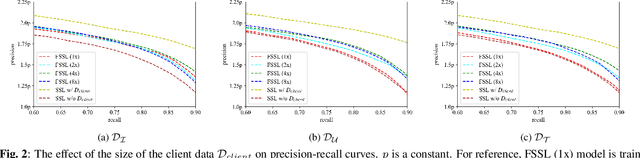
Standard acoustic event classification (AEC) solutions require large-scale collection of data from client devices for model optimization. Federated learning (FL) is a compelling framework that decouples data collection and model training to enhance customer privacy. In this work, we investigate the feasibility of applying FL to improve AEC performance while no customer data can be directly uploaded to the server. We assume no pseudo labels can be inferred from on-device user inputs, aligning with the typical use cases of AEC. We adapt self-supervised learning to the FL framework for on-device continual learning of representations, and it results in improved performance of the downstream AEC classifiers without labeled/pseudo-labeled data available. Compared to the baseline w/o FL, the proposed method improves precision up to 20.3\% relatively while maintaining the recall. Our work differs from prior work in FL in that our approach does not require user-generated learning targets, and the data we use is collected from our Beta program and is de-identified, to maximally simulate the production settings.
Risk Conditioned Neural Motion Planning
Aug 04, 2021

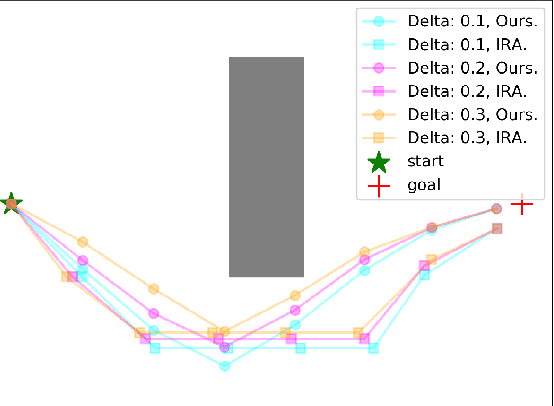
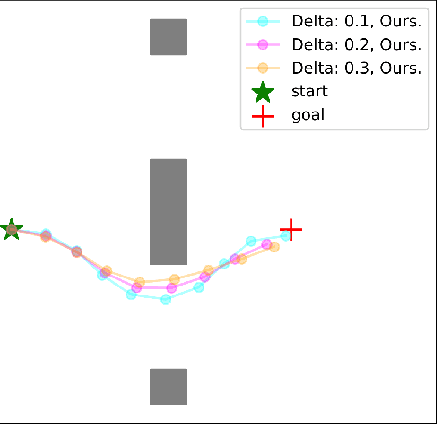
Risk-bounded motion planning is an important yet difficult problem for safety-critical tasks. While existing mathematical programming methods offer theoretical guarantees in the context of constrained Markov decision processes, they either lack scalability in solving larger problems or produce conservative plans. Recent advances in deep reinforcement learning improve scalability by learning policy networks as function approximators. In this paper, we propose an extension of soft actor critic model to estimate the execution risk of a plan through a risk critic and produce risk-bounded policies efficiently by adding an extra risk term in the loss function of the policy network. We define the execution risk in an accurate form, as opposed to approximating it through a summation of immediate risks at each time step that leads to conservative plans. Our proposed model is conditioned on a continuous spectrum of risk bounds, allowing the user to adjust the risk-averse level of the agent on the fly. Through a set of experiments, we show the advantage of our model in terms of both computational time and plan quality, compared to a state-of-the-art mathematical programming baseline, and validate its performance in more complicated scenarios, including nonlinear dynamics and larger state space.