 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
Jan 27, 2026Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
A Simple HMM with Self-Supervised Representations for Phone Segmentation
Sep 15, 2024



Despite the recent advance in self-supervised representations, unsupervised phonetic segmentation remains challenging. Most approaches focus on improving phonetic representations with self-supervised learning, with the hope that the improvement can transfer to phonetic segmentation. In this paper, contrary to recent approaches, we show that peak detection on Mel spectrograms is a strong baseline, better than many self-supervised approaches. Based on this finding, we propose a simple hidden Markov model that uses self-supervised representations and features at the boundaries for phone segmentation. Our results demonstrate consistent improvements over previous approaches, with a generalized formulation allowing versatile design adaptations.
Towards Matching Phones and Speech Representations
Oct 26, 2023



Learning phone types from phone instances has been a long-standing problem, while still being open. In this work, we revisit this problem in the context of self-supervised learning, and pose it as the problem of matching cluster centroids to phone embeddings. We study two key properties that enable matching, namely, whether cluster centroids of self-supervised representations reduce the variability of phone instances and respect the relationship among phones. We then use the matching result to produce pseudo-labels and introduce a new loss function for improving self-supervised representations. Our experiments show that the matching result captures the relationship among phones. Training the new loss function jointly with the regular self-supervised losses, such as APC and CPC, significantly improves the downstream phone classification.
On-Device Constrained Self-Supervised Speech Representation Learning for Keyword Spotting via Knowledge Distillation
Jul 06, 2023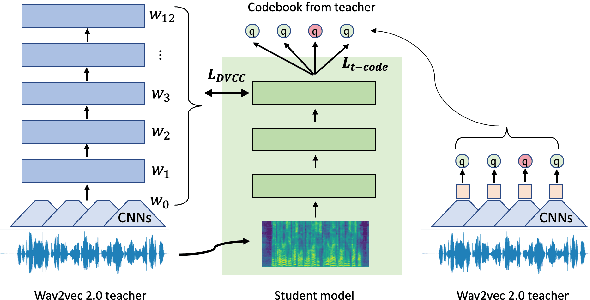

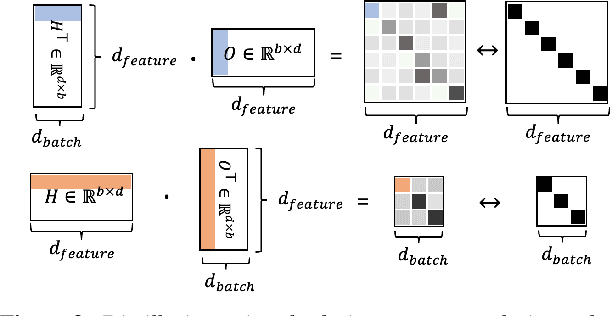
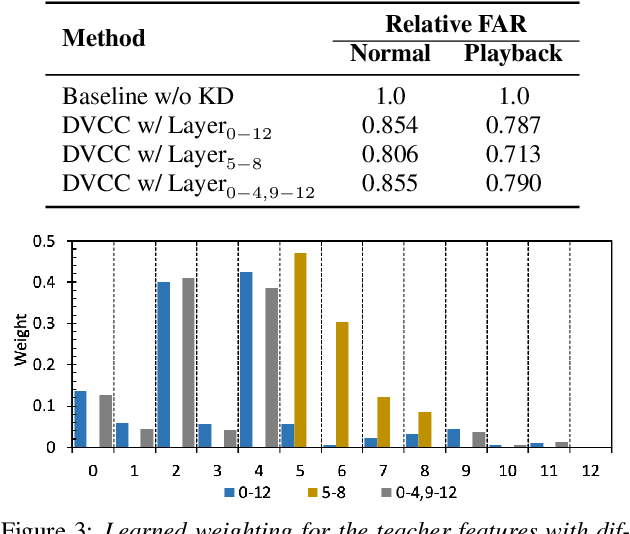
Large self-supervised models are effective feature extractors, but their application is challenging under on-device budget constraints and biased dataset collection, especially in keyword spotting. To address this, we proposed a knowledge distillation-based self-supervised speech representation learning (S3RL) architecture for on-device keyword spotting. Our approach used a teacher-student framework to transfer knowledge from a larger, more complex model to a smaller, light-weight model using dual-view cross-correlation distillation and the teacher's codebook as learning objectives. We evaluated our model's performance on an Alexa keyword spotting detection task using a 16.6k-hour in-house dataset. Our technique showed exceptional performance in normal and noisy conditions, demonstrating the efficacy of knowledge distillation methods in constructing self-supervised models for keyword spotting tasks while working within on-device resource constraints.
Supervised Attention in Sequence-to-Sequence Models for Speech Recognition
Apr 25, 2022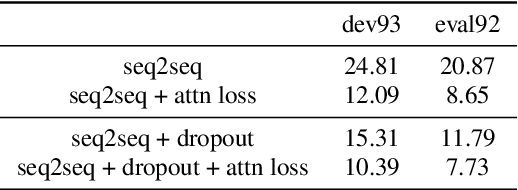
Attention mechanism in sequence-to-sequence models is designed to model the alignments between acoustic features and output tokens in speech recognition. However, attention weights produced by models trained end to end do not always correspond well with actual alignments, and several studies have further argued that attention weights might not even correspond well with the relevance attribution of frames. Regardless, visual similarity between attention weights and alignments is widely used during training as an indicator of the models quality. In this paper, we treat the correspondence between attention weights and alignments as a learning problem by imposing a supervised attention loss. Experiments have shown significant improved performance, suggesting that learning the alignments well during training critically determines the performance of sequence-to-sequence models.
Self-supervised Pre-training Reduces Label Permutation Instability of Speech Separation
Oct 29, 2020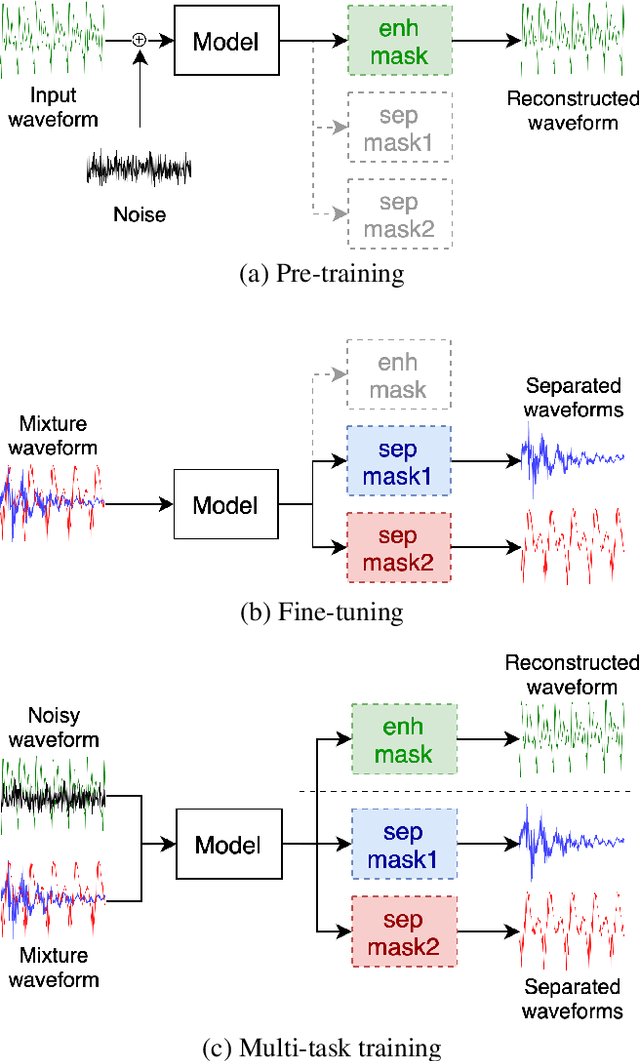
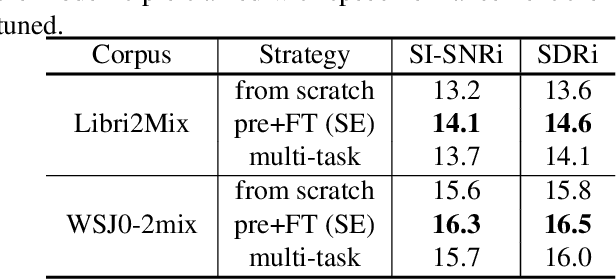
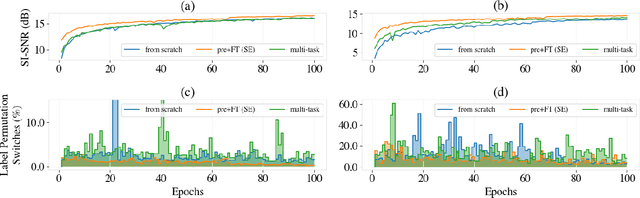
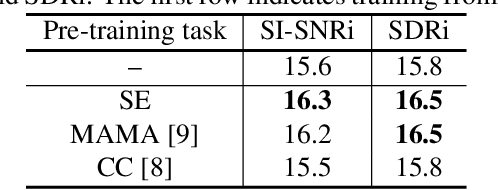
Speech separation has been well-developed while there are still problems waiting to be solved. The main problem we focus on in this paper is the frequent label permutation switching of permutation invariant training (PIT). For N-speaker separation, there would be N! possible label permutations. How to stably select correct label permutations is a long-standing problem. In this paper, we utilize self-supervised pre-training to stabilize the label permutations. Among several types of self-supervised tasks, speech enhancement based pre-training tasks show significant effectiveness in our experiments. When using off-the-shelf pre-trained models, training duration could be shortened to one-third to two-thirds. Furthermore, even taking pre-training time into account, the entire training process could still be shorter without a performance drop when using a larger batch size.
Interrupted and cascaded permutation invariant training for speech separation
Oct 28, 2019
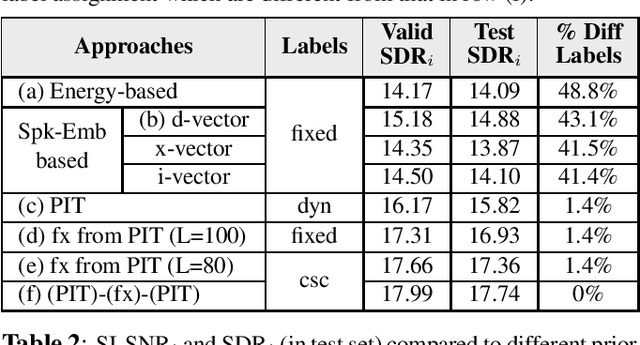
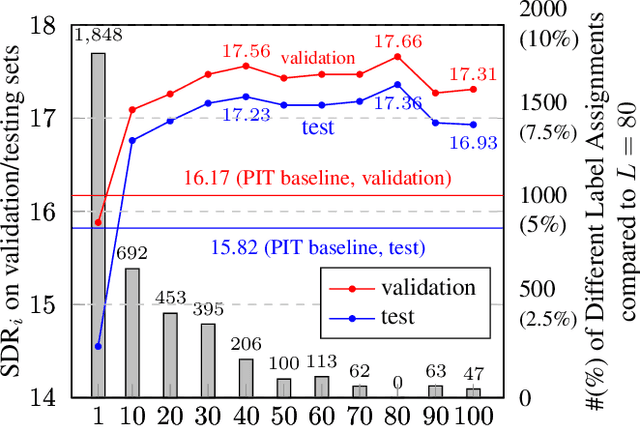
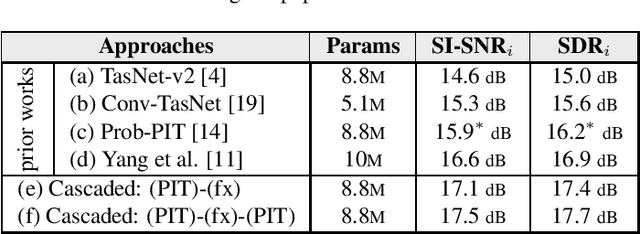
Permutation Invariant Training (PIT) has long been a stepping stone method for training speech separation model in handling the label ambiguity problem. With PIT selecting the minimum cost label assignments dynamically, very few studies considered the separation problem to be optimizing both the model parameters and the label assignments, but focused on searching for good model architecture and parameters. In this paper, we investigate instead for a given model architecture the various flexible label assignment strategies for training the model, rather than directly using PIT. Surprisingly, we discover a significant performance boost compared to PIT is possible if the model is trained with fixed label assignments and a good set of labels is chosen. With fixed label training cascaded between two sections of PIT, we achieved the state-of-the-art performance on WSJ0-2mix without changing the model architecture at all.
Improved Speech Separation with Time-and-Frequency Cross-domain Joint Embedding and Clustering
Apr 16, 2019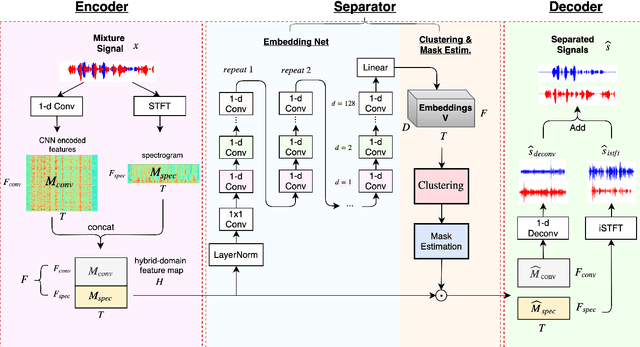
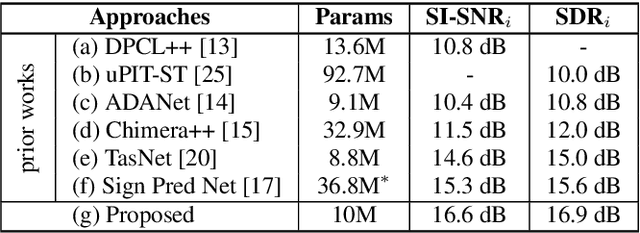
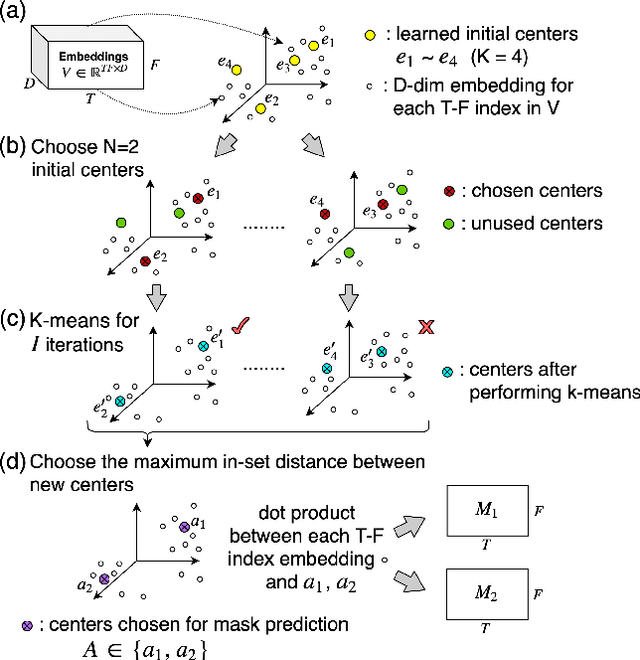
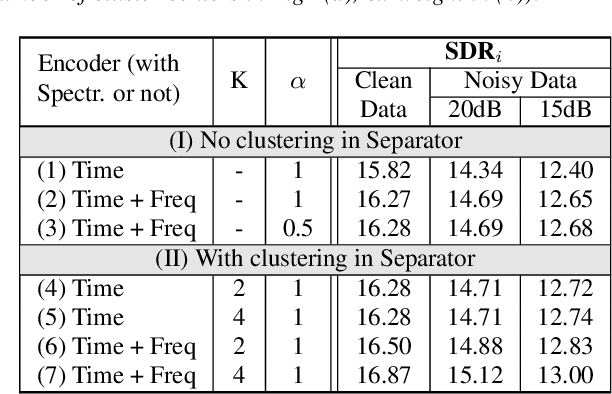
Speech separation has been very successful with deep learning techniques. Substantial effort has been reported based on approaches over spectrogram, which is well known as the standard time-and-frequency cross-domain representation for speech signals. It is highly correlated to the phonetic structure of speech, or "how the speech sounds" when perceived by human, but primarily frequency domain features carrying temporal behaviour. Very impressive work achieving speech separation over time domain was reported recently, probably because waveforms in time domain may describe the different realizations of speech in a more precise way than spectrogram. In this paper, we propose a framework properly integrating the above two directions, hoping to achieve both purposes. We construct a time-and-frequency feature map by concatenating the 1-dim convolution encoded feature map (for time domain) and the spectrogram (for frequency domain), which was then processed by an embedding network and clustering approaches very similar to those used in time and frequency domain prior works. In this way, the information in the time and frequency domains, as well as the interactions between them, can be jointly considered during embedding and clustering. Very encouraging results (state-of-the-art to our knowledge) were obtained with WSJ0-2mix dataset in preliminary experiments.