 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Attention in Sequence-to-Sequence Models for Speech Recognition
Paper and Code
Apr 25, 2022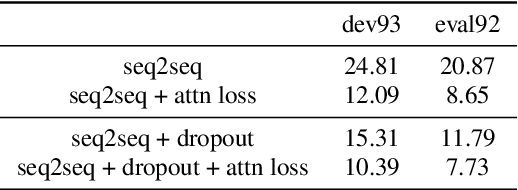
Attention mechanism in sequence-to-sequence models is designed to model the alignments between acoustic features and output tokens in speech recognition. However, attention weights produced by models trained end to end do not always correspond well with actual alignments, and several studies have further argued that attention weights might not even correspond well with the relevance attribution of frames. Regardless, visual similarity between attention weights and alignments is widely used during training as an indicator of the models quality. In this paper, we treat the correspondence between attention weights and alignments as a learning problem by imposing a supervised attention loss. Experiments have shown significant improved performance, suggesting that learning the alignments well during training critically determines the performance of sequence-to-sequence models.