 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Constrained Self-Supervised Speech Representation Learning for Keyword Spotting via Knowledge Distillation
Paper and Code
Jul 06, 2023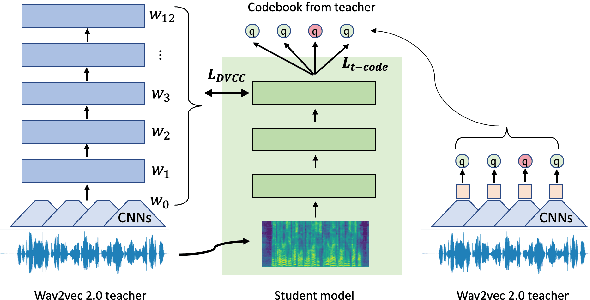

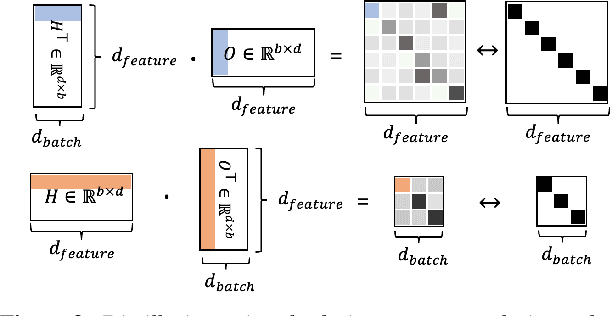
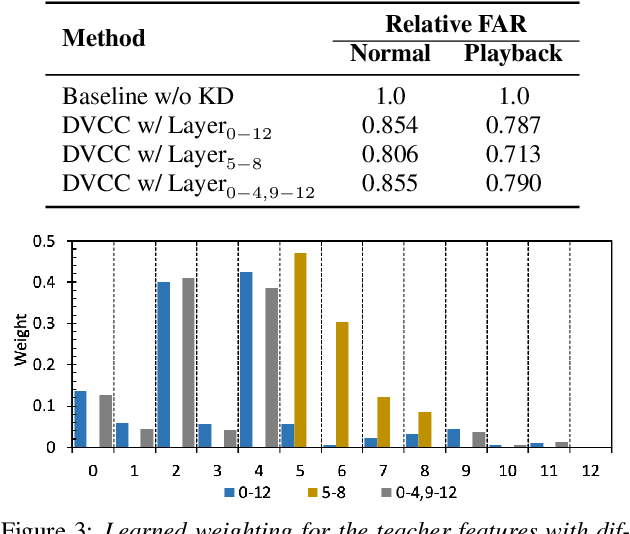
Large self-supervised models are effective feature extractors, but their application is challenging under on-device budget constraints and biased dataset collection, especially in keyword spotting. To address this, we proposed a knowledge distillation-based self-supervised speech representation learning (S3RL) architecture for on-device keyword spotting. Our approach used a teacher-student framework to transfer knowledge from a larger, more complex model to a smaller, light-weight model using dual-view cross-correlation distillation and the teacher's codebook as learning objectives. We evaluated our model's performance on an Alexa keyword spotting detection task using a 16.6k-hour in-house dataset. Our technique showed exceptional performance in normal and noisy conditions, demonstrating the efficacy of knowledge distillation methods in constructing self-supervised models for keyword spotting tasks while working within on-device resource constraints.