 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Speech Separation with Time-and-Frequency Cross-domain Joint Embedding and Clustering
Paper and Code
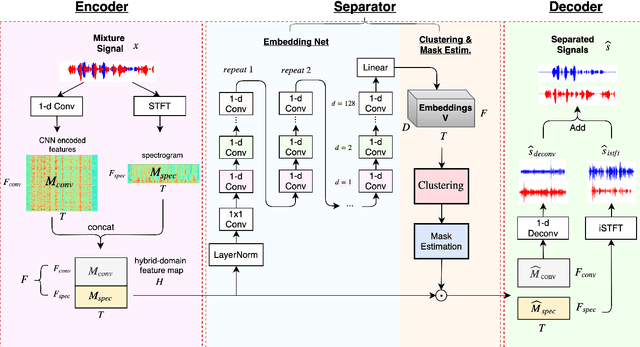
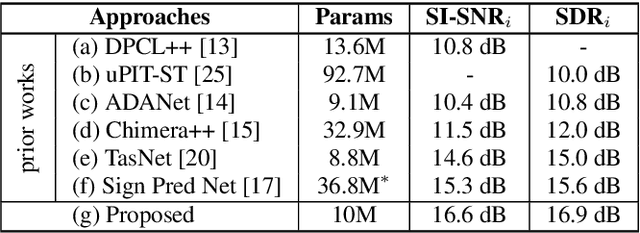
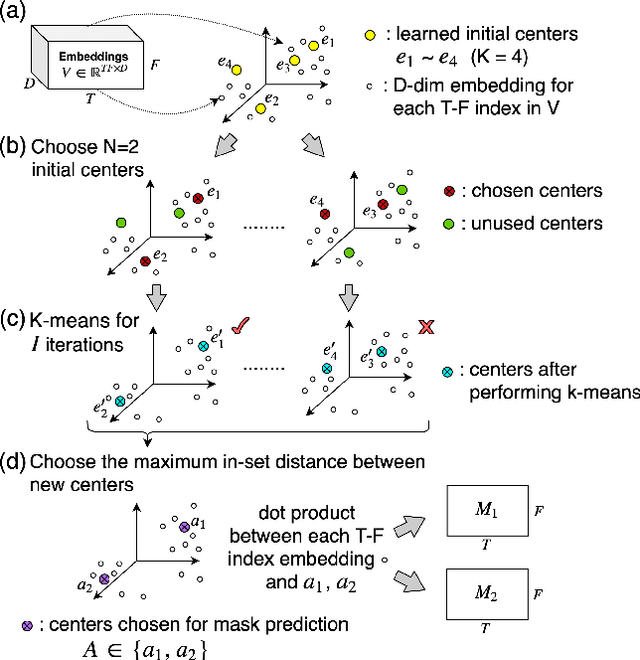
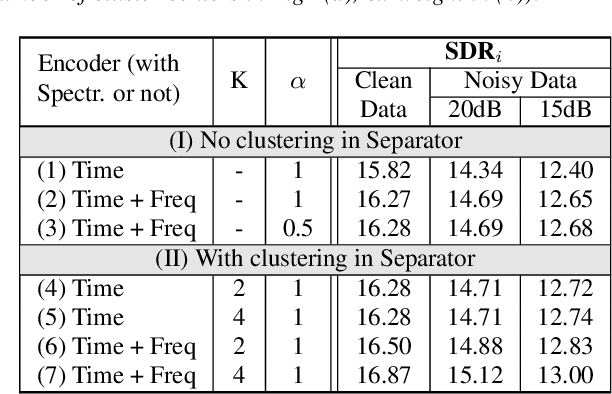
Speech separation has been very successful with deep learning techniques. Substantial effort has been reported based on approaches over spectrogram, which is well known as the standard time-and-frequency cross-domain representation for speech signals. It is highly correlated to the phonetic structure of speech, or "how the speech sounds" when perceived by human, but primarily frequency domain features carrying temporal behaviour. Very impressive work achieving speech separation over time domain was reported recently, probably because waveforms in time domain may describe the different realizations of speech in a more precise way than spectrogram. In this paper, we propose a framework properly integrating the above two directions, hoping to achieve both purposes. We construct a time-and-frequency feature map by concatenating the 1-dim convolution encoded feature map (for time domain) and the spectrogram (for frequency domain), which was then processed by an embedding network and clustering approaches very similar to those used in time and frequency domain prior works. In this way, the information in the time and frequency domains, as well as the interactions between them, can be jointly considered during embedding and clustering. Very encouraging results (state-of-the-art to our knowledge) were obtained with WSJ0-2mix dataset in preliminary experiments.