 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Disentangled Representations for Human Retargeting by Multi-view Learning
Paper and Code
Dec 12, 2019
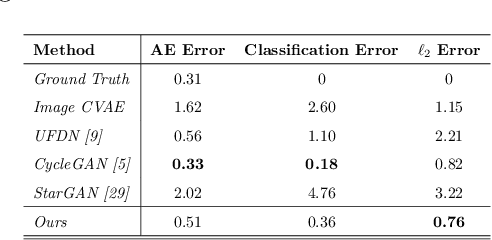
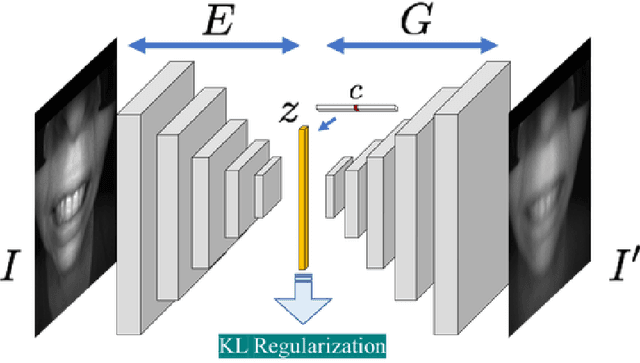

We study the problem of learning disentangled representations for data across multiple domains and its applications in human retargeting. Our goal is to map an input image to an identity-invariant latent representation that captures intrinsic factors such as expressions and poses. To this end, we present a novel multi-view learning approach that leverages various data sources such as images, keypoints, and poses. Our model consists of multiple id-conditioned VAEs for different views of the data. During training, we encourage the latent embeddings to be consistent across these views. Our observation is that auxiliary data like keypoints and poses contain critical, id-agnostic semantic information, and it is easier to train a disentangling CVAE on these simpler views to separate such semantics from other id-specific attributes. We show that training multi-view CVAEs and encourage latent-consistency guides the image encoding to preserve the semantics of expressions and poses, leading to improved disentangled representations and better human retargeting results.