 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Siamese Long Short-Term Memory Architecture for Human Re-Identification
Paper and Code
Jul 28, 2016

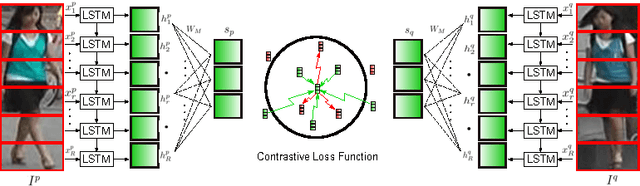
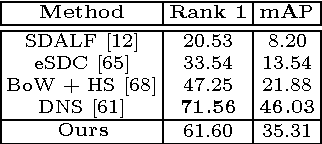
Matching pedestrians across multiple camera views known as human re-identification (re-identification) is a challenging problem in visual surveillance. In the existing works concentrating on feature extraction, representations are formed locally and independent of other regions. We present a novel siamese Long Short-Term Memory (LSTM) architecture that can process image regions sequentially and enhance the discriminative capability of local feature representation by leveraging contextual information. The feedback connections and internal gating mechanism of the LSTM cells enable our model to memorize the spatial dependencies and selectively propagate relevant contextual information through the network. We demonstrate improved performance compared to the baseline algorithm with no LSTM units and promising results compared to state-of-the-art methods on Market-1501, CUHK03 and VIPeR datasets. Visualization of the internal mechanism of LSTM cells shows meaningful patterns can be learned by our method.