 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Invariant Feature Learning with Marginalization for Person Re-Identification
Paper and Code
Nov 30, 2015
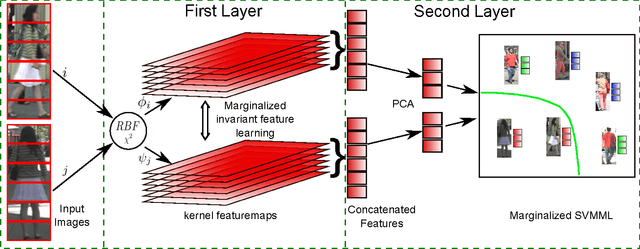


This paper addresses the problem of matching pedestrians across multiple camera views, known as person re-identification. Variations in lighting conditions, environment and pose changes across camera views make re-identification a challenging problem. Previous methods address these challenges by designing specific features or by learning a distance function. We propose a hierarchical feature learning framework that learns invariant representations from labeled image pairs. A mapping is learned such that the extracted features are invariant for images belonging to same individual across views. To learn robust representations and to achieve better generalization to unseen data, the system has to be trained with a large amount of data. Critically, most of the person re-identification datasets are small. Manually augmenting the dataset by partial corruption of input data introduces additional computational burden as it requires several training epochs to converge. We propose a hierarchical network which incorporates a marginalization technique that can reap the benefits of training on large datasets without explicit augmentation. We compare our approach with several baseline algorithms as well as popular linear and non-linear metric learning algorithms and demonstrate improved performance on challenging publicly available datasets, VIPeR, CUHK01, CAVIAR4REID and iLIDS. Our approach also achieves the stateof-the-art results on these datasets.