 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn efficient scheme based on graph centrality to select nodes for training for effective learning
May 19, 2021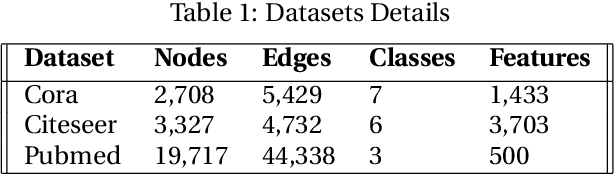
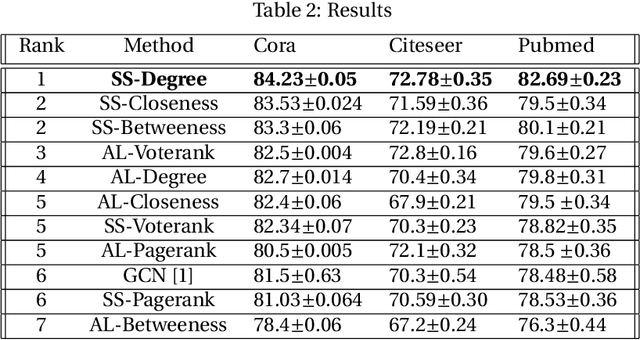
The process of selecting points for training a machine learning model is often a challenging task. Many times, we will have a lot of data, but for training, we require the labels and labeling is often costly. So we need to select the points for training in an efficient manner so that the model trained on the points selected will be better than the ones trained on any other training set. We propose a novel method to select the nodes in graph datasets using the concept of graph centrality. Two methods are proposed - one using a smart selection strategy, where the model is required to be trained only once and another using active learning method. We have tested this idea on three popular graph datasets - Cora, Citeseer and Pubmed- and the results are found to be encouraging.