 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuicidal Pedestrian: Generation of Safety-Critical Scenarios for Autonomous Vehicles
Sep 01, 2023



Developing reliable autonomous driving algorithms poses challenges in testing, particularly when it comes to safety-critical traffic scenarios involving pedestrians. An open question is how to simulate rare events, not necessarily found in autonomous driving datasets or scripted simulations, but which can occur in testing, and, in the end may lead to severe pedestrian related accidents. This paper presents a method for designing a suicidal pedestrian agent within the CARLA simulator, enabling the automatic generation of traffic scenarios for testing safety of autonomous vehicles (AVs) in dangerous situations with pedestrians. The pedestrian is modeled as a reinforcement learning (RL) agent with two custom reward functions that allow the agent to either arbitrarily or with high velocity to collide with the AV. Instead of significantly constraining the initial locations and the pedestrian behavior, we allow the pedestrian and autonomous car to be placed anywhere in the environment and the pedestrian to roam freely to generate diverse scenarios. To assess the performance of the suicidal pedestrian and the target vehicle during testing, we propose three collision-oriented evaluation metrics. Experimental results involving two state-of-the-art autonomous driving algorithms trained end-to-end with imitation learning from sensor data demonstrate the effectiveness of the suicidal pedestrian in identifying decision errors made by autonomous vehicles controlled by the algorithms.
Continuous Monte Carlo Graph Search
Oct 04, 2022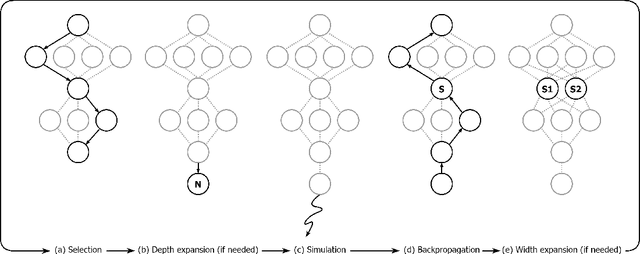

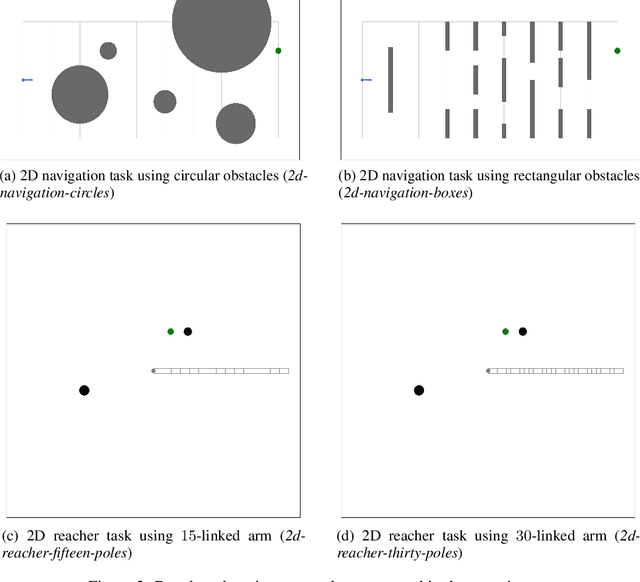

In many complex sequential decision making tasks, online planning is crucial for high-performance. For efficient online planning, Monte Carlo Tree Search (MCTS) employs a principled mechanism for trading off between exploration and exploitation. MCTS outperforms comparison methods in various discrete decision making domains such as Go, Chess, and Shogi. Following, extensions of MCTS to continuous domains have been proposed. However, the inherent high branching factor and the resulting explosion of search tree size is limiting existing methods. To solve this problem, this paper proposes Continuous Monte Carlo Graph Search (CMCGS), a novel extension of MCTS to online planning in environments with continuous state and action spaces. CMCGS takes advantage of the insight that, during planning, sharing the same action policy between several states can yield high performance. To implement this idea, at each time step CMCGS clusters similar states into a limited number of stochastic action bandit nodes, which produce a layered graph instead of an MCTS search tree. Experimental evaluation with limited sample budgets shows that CMCGS outperforms comparison methods in several complex continuous DeepMind Control Suite benchmarks and a 2D navigation task.
Learning Task-Agnostic Action Spaces for Movement Optimization
Sep 22, 2020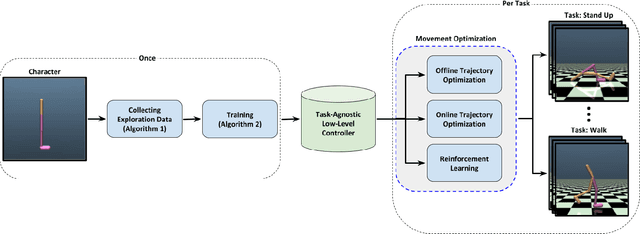
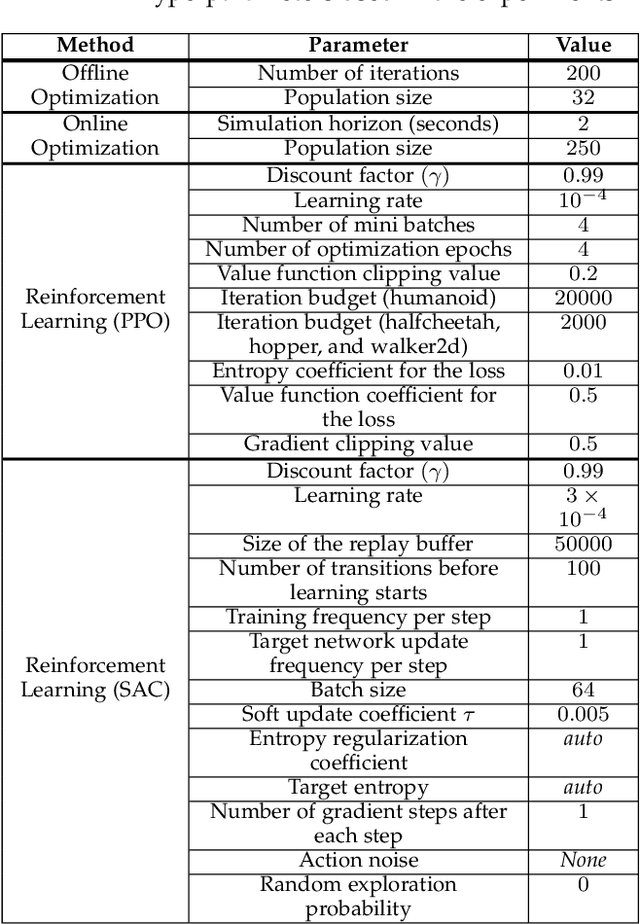
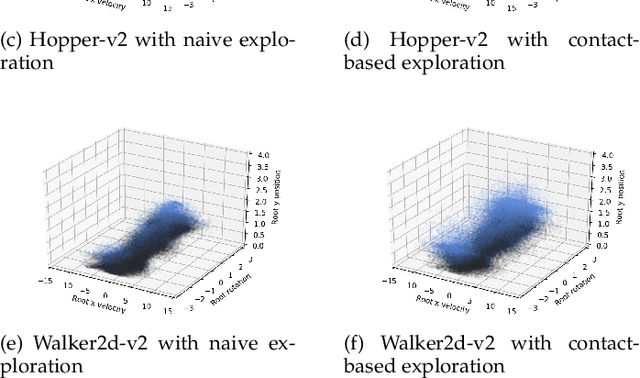

We propose a novel method for exploring the dynamics of physically based animated characters, and learning a task-agnostic action space that makes movement optimization easier. Like several previous papers, we parameterize actions as target states, and learn a short-horizon goal-conditioned low-level control policy that drives the agent's state towards the targets. Our novel contribution is that with our exploration data, we are able to learn the low-level policy in a generic manner and without any reference movement data. Trained once for each agent or simulation environment, the policy improves the efficiency of optimizing both trajectories and high-level policies across multiple tasks and optimization algorithms. We also contribute novel visualizations that show how using target states as actions makes optimized trajectories more robust to disturbances; this manifests as wider optima that are easy to find. Due to its simplicity and generality, our proposed approach should provide a building block that can improve a large variety of movement optimization methods and applications.
Self-Imitation Learning of Locomotion Movements through Termination Curriculum
Jul 27, 2019


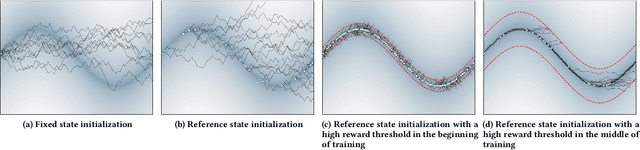
Animation and machine learning research have shown great advancements in the past decade, leading to robust and powerful methods for learning complex physically-based animations. However, learning can take hours or days, especially if no reference movement data is available. In this paper, we propose and evaluate a novel combination of techniques for accelerating the learning of stable locomotion movements through self-imitation learning of synthetic animations. First, we produce synthetic and cyclic reference movement using a recent online tree search approach that can discover stable walking gaits in a few minutes. This allows us to use reinforcement learning with Reference State Initialization (RSI) to find a neural network controller for imitating the synthesized reference motion. We further accelerate the learning using a novel curriculum learning approach called Termination Curriculum (TC), that adapts the episode termination threshold over time. The combination of the RSI and TC ensures that simulation budget is not wasted in regions of the state space not visited by the final policy. As a result, our agents can learn locomotion skills in just a few hours on a modest 4-core computer. We demonstrate this by producing locomotion movements for a variety of characters.