 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Fatigued Movements for Virtual Character Animation
Oct 12, 2023Virtual character animation and movement synthesis have advanced rapidly during recent years, especially through a combination of extensive motion capture datasets and machine learning. A remaining challenge is interactively simulating characters that fatigue when performing extended motions, which is indispensable for the realism of generated animations. However, capturing such movements is problematic, as performing movements like backflips with fatigued variations up to exhaustion raises capture cost and risk of injury. Surprisingly, little research has been done on faithful fatigue modeling. To address this, we propose a deep reinforcement learning-based approach, which -- for the first time in literature -- generates control policies for full-body physically simulated agents aware of cumulative fatigue. For this, we first leverage Generative Adversarial Imitation Learning (GAIL) to learn an expert policy for the skill; Second, we learn a fatigue policy by limiting the generated constant torque bounds based on endurance time to non-linear, state- and time-dependent limits in the joint-actuation space using a Three-Compartment Controller (3CC) model. Our results demonstrate that agents can adapt to different fatigue and rest rates interactively, and discover realistic recovery strategies without the need for any captured data of fatigued movement.
* 16 pages, 22 figures. To be published in ACM SIGGRAPH Asia Conference Papers 2023. ACM ISBN 979-8-4007-0315-7/23/12
"An Adapt-or-Die Type of Situation": Perception, Adoption, and Use of Text-To-Image-Generation AI by Game Industry Professionals
Feb 27, 2023

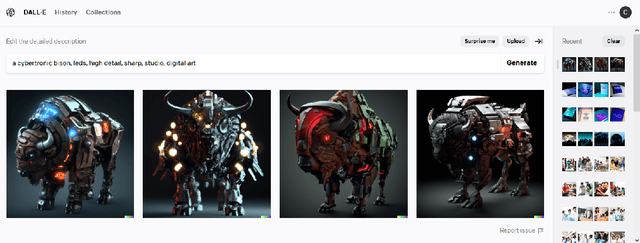
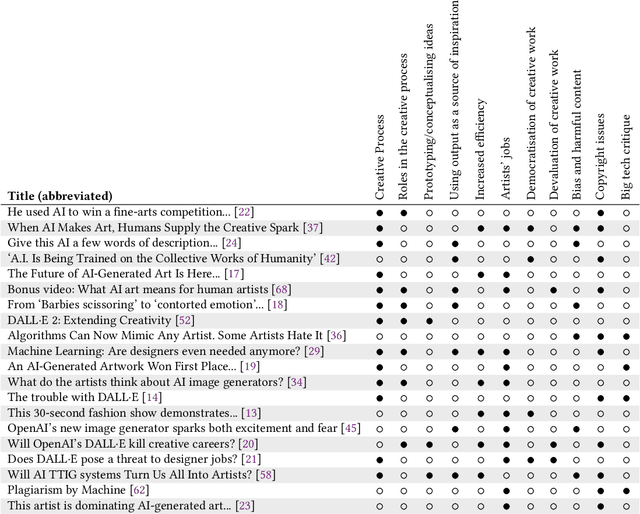
Text-to-image generation (TTIG) models, a recent addition to creative AI, can generate images based on a text description. These models have begun to rival the work of professional creatives, and sparked discussions on the future of creative work, loss of jobs, and copyright issues, amongst other important implications. To support the sustainable adoption of TTIG, we must provide rich, reliable and transparent insights into how professionals perceive, adopt and use TTIG. Crucially though, the public debate is shallow, narrow and lacking transparency, while academic work has focused on studying the use of TTIG in a general artist population, but not on the perceptions and attitudes of professionals in a specific industry. In this paper, we contribute a qualitative, exploratory interview study on TTIG in the Finnish videogame industry. Through a Template Analysis on semi-structured interviews with 14 game professionals, we reveal 12 overarching themes, structured into 49 sub-themes on professionals' perception, adoption and use of TTIG systems in games industry practice. Experiencing (yet another) change of roles and creative processes, our participants' reflections can inform discussions within the industry, be used by policymakers to inform urgently needed legislation, and support researchers in games, HCI and AI to support the sustainable, professional use of TTIG to benefit people and games as cultural artefacts.
Cine-AI: Generating Video Game Cutscenes in the Style of Human Directors
Aug 11, 2022
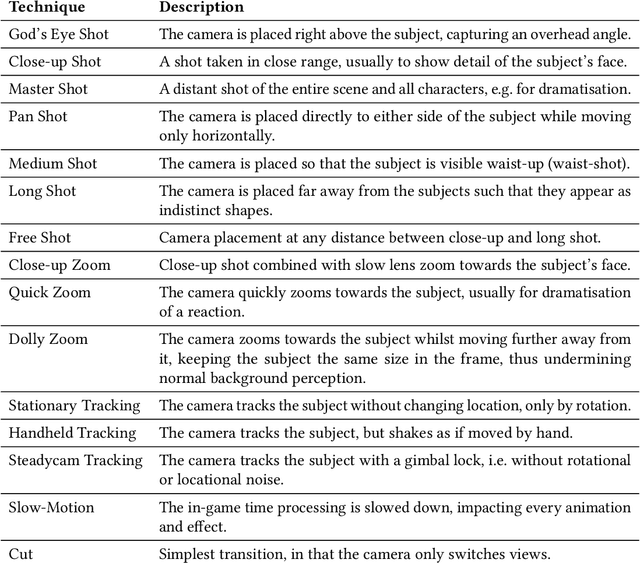
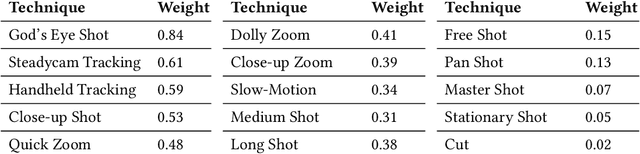
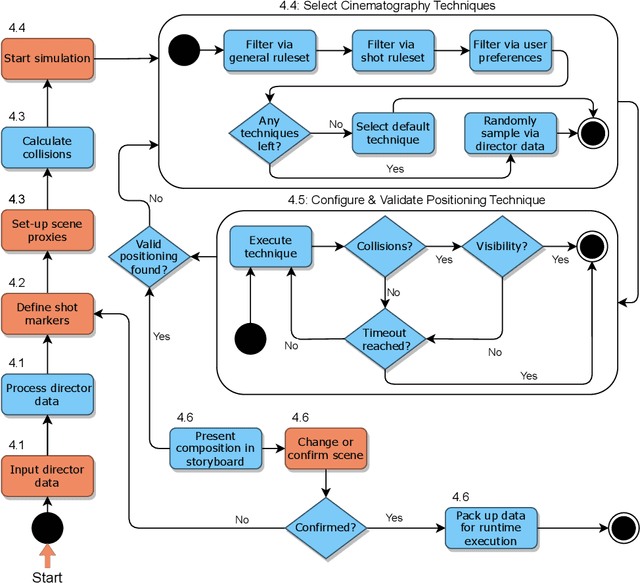
Cutscenes form an integral part of many video games, but their creation is costly, time-consuming, and requires skills that many game developers lack. While AI has been leveraged to semi-automate cutscene production, the results typically lack the internal consistency and uniformity in style that is characteristic of professional human directors. We overcome this shortcoming with Cine-AI, an open-source procedural cinematography toolset capable of generating in-game cutscenes in the style of eminent human directors. Implemented in the popular game engine Unity, Cine-AI features a novel timeline and storyboard interface for design-time manipulation, combined with runtime cinematography automation. Via two user studies, each employing quantitative and qualitative measures, we demonstrate that Cine-AI generates cutscenes that people correctly associate with a target director, while providing above-average usability. Our director imitation dataset is publicly available, and can be extended by users and film enthusiasts.
Predicting Game Engagement and Difficulty Using AI Players
Jul 26, 2021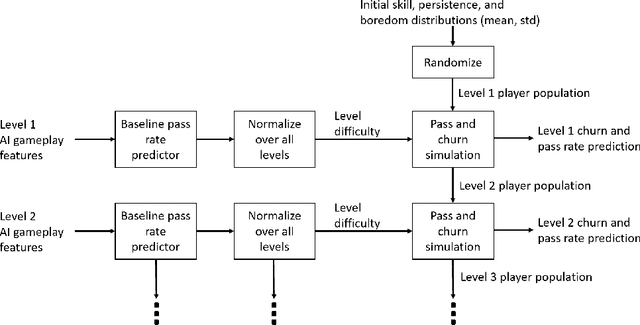


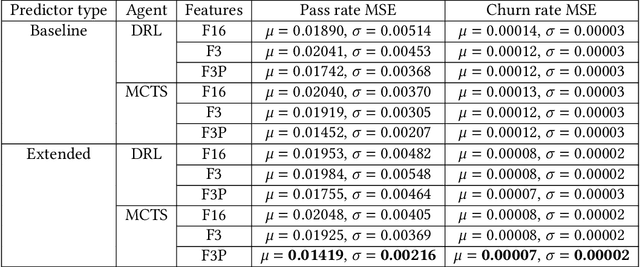
This paper presents a novel approach to automated playtesting for the prediction of human player behavior and experience. It has previously been demonstrated that Deep Reinforcement Learning (DRL) game-playing agents can predict both game difficulty and player engagement, operationalized as average pass and churn rates. We improve this approach by enhancing DRL with Monte Carlo Tree Search (MCTS). We also motivate an enhanced selection strategy for predictor features, based on the observation that an AI agent's best-case performance can yield stronger correlations with human data than the agent's average performance. Both additions consistently improve the prediction accuracy, and the DRL-enhanced MCTS outperforms both DRL and vanilla MCTS in the hardest levels. We conclude that player modelling via automated playtesting can benefit from combining DRL and MCTS. Moreover, it can be worthwhile to investigate a subset of repeated best AI agent runs, if AI gameplay does not yield good predictions on average.
Learning Task-Agnostic Action Spaces for Movement Optimization
Sep 22, 2020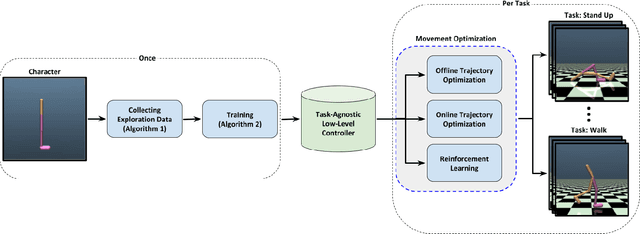
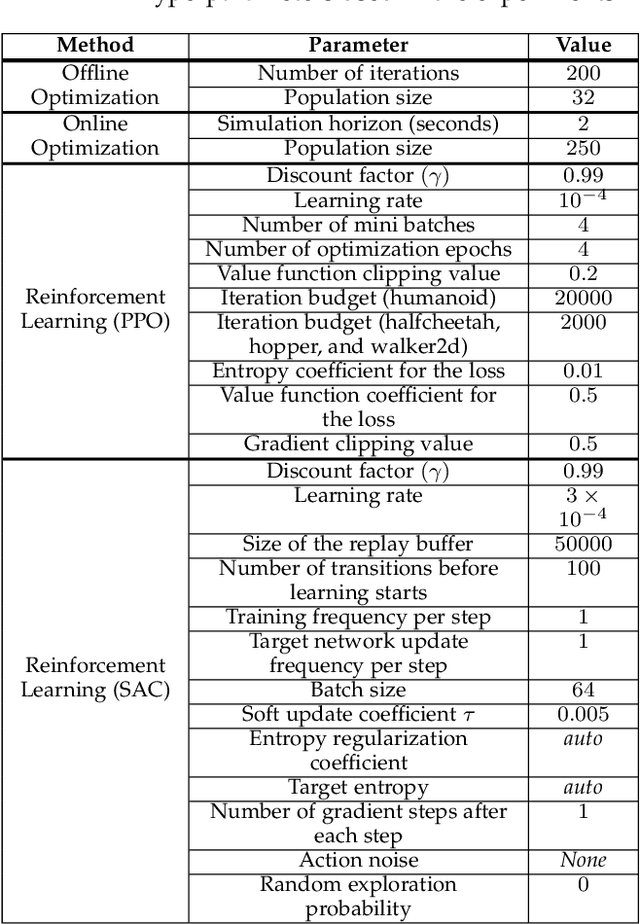
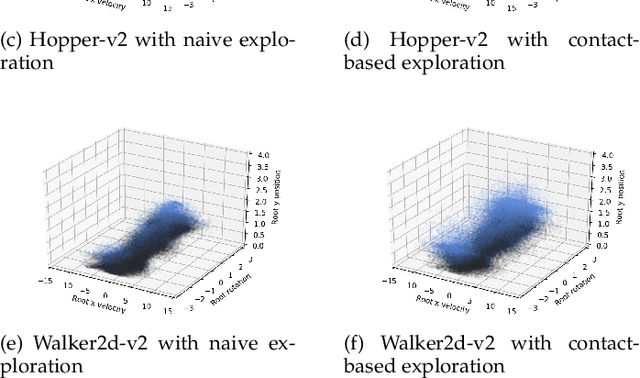

We propose a novel method for exploring the dynamics of physically based animated characters, and learning a task-agnostic action space that makes movement optimization easier. Like several previous papers, we parameterize actions as target states, and learn a short-horizon goal-conditioned low-level control policy that drives the agent's state towards the targets. Our novel contribution is that with our exploration data, we are able to learn the low-level policy in a generic manner and without any reference movement data. Trained once for each agent or simulation environment, the policy improves the efficiency of optimizing both trajectories and high-level policies across multiple tasks and optimization algorithms. We also contribute novel visualizations that show how using target states as actions makes optimized trajectories more robust to disturbances; this manifests as wider optima that are easy to find. Due to its simplicity and generality, our proposed approach should provide a building block that can improve a large variety of movement optimization methods and applications.
Predicting Game Difficulty and Churn Without Players
Aug 29, 2020

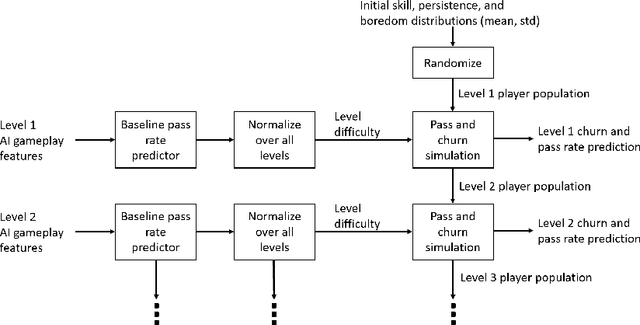
We propose a novel simulation model that is able to predict the per-level churn and pass rates of Angry Birds Dream Blast, a popular mobile free-to-play game. Our primary contribution is to combine AI gameplay using Deep Reinforcement Learning (DRL) with a simulation of how the player population evolves over the levels. The AI players predict level difficulty, which is used to drive a player population model with simulated skill, persistence, and boredom. This allows us to model, e.g., how less persistent and skilled players are more sensitive to high difficulty, and how such players churn early, which makes the player population and the relation between difficulty and churn evolve level by level. Our work demonstrates that player behavior predictions produced by DRL gameplay can be significantly improved by even a very simple population-level simulation of individual player differences, without requiring costly retraining of agents or collecting new DRL gameplay data for each simulated player.
Deep Residual Mixture Models
Jun 22, 2020
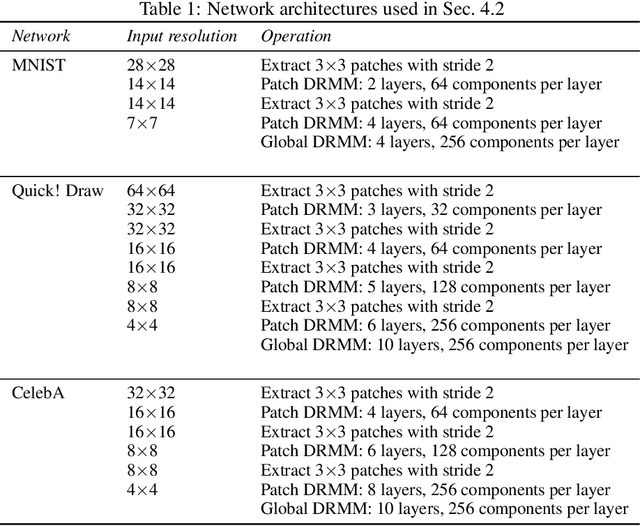


We propose Deep Residual Mixture Models (DRMMs) which share the many desirable properties of Gaussian Mixture Models (GMMs), but with a crucial benefit: The modeling capacity of a DRMM can grow exponentially with depth, while the number of model parameters only grows quadratically. DRMMs allow for extremely flexible conditional sampling, as the conditioning variables can be freely selected without re-training the model, and it is easy to combine the sampling with priors and (in)equality constraints. DRMMs should be applicable where GMMs are traditionally used, but as demonstrated in our experiments, DRMMs scale better to complex, high-dimensional data. We demonstrate the approach in constrained multi-limb inverse kinematics and image completion.
Visualizing Movement Control Optimization Landscapes
Sep 18, 2019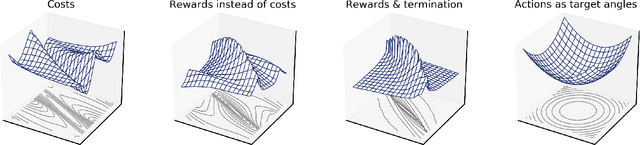
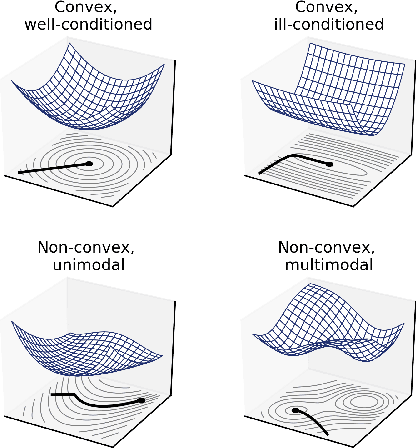

A large body of animation research focuses on optimization of movement control, either as action sequences or policy parameters. However, as closed-form expressions of the objective functions are often not available, our understanding of the optimization problems is limited. Building on recent work on analyzing neural network training, we contribute novel visualizations of high-dimensional control optimization landscapes; this yields insights into why control optimization is hard and why common practices like early termination and spline-based action parameterizations make optimization easier. For example, our experiments show how trajectory optimization can become increasingly ill-conditioned with longer trajectories, but parameterizing control as partial target states - e.g., target angles converted to torques using a PD-controller - can act as an efficient preconditioner. Both our visualizations and quantitative empirical data also indicate that neural network policy optimization scales better than trajectory optimization for long planning horizons. Our work advances the understanding of movement optimization and our visualizations should also provide value in educational use.
Self-Imitation Learning of Locomotion Movements through Termination Curriculum
Jul 27, 2019


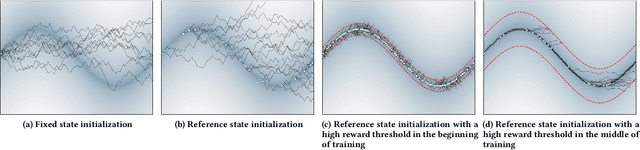
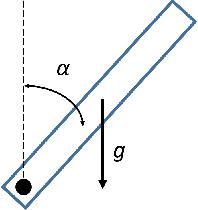
Animation and machine learning research have shown great advancements in the past decade, leading to robust and powerful methods for learning complex physically-based animations. However, learning can take hours or days, especially if no reference movement data is available. In this paper, we propose and evaluate a novel combination of techniques for accelerating the learning of stable locomotion movements through self-imitation learning of synthetic animations. First, we produce synthetic and cyclic reference movement using a recent online tree search approach that can discover stable walking gaits in a few minutes. This allows us to use reinforcement learning with Reference State Initialization (RSI) to find a neural network controller for imitating the synthesized reference motion. We further accelerate the learning using a novel curriculum learning approach called Termination Curriculum (TC), that adapts the episode termination threshold over time. The combination of the RSI and TC ensures that simulation budget is not wasted in regions of the state space not visited by the final policy. As a result, our agents can learn locomotion skills in just a few hours on a modest 4-core computer. We demonstrate this by producing locomotion movements for a variety of characters.
An Iterative Closest Points Approach to Neural Generative Models
Jul 02, 2018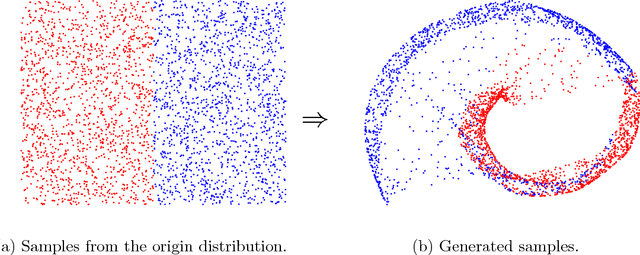
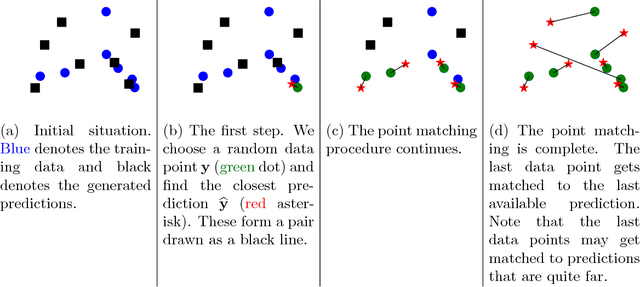
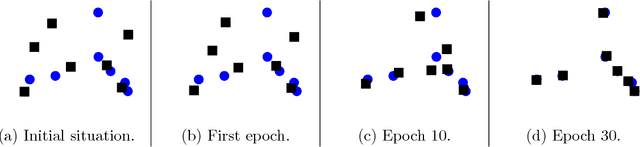
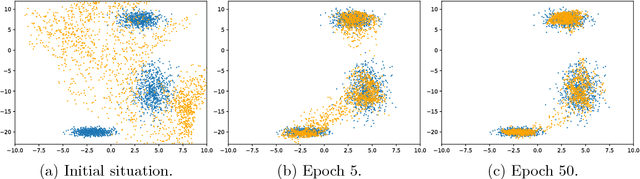
We present a simple way to learn a transformation that maps samples of one distribution to the samples of another distribution. Our algorithm comprises an iteration of 1) drawing samples from some simple distribution and transforming them using a neural network, 2) determining pairwise correspondences between the transformed samples and training data (or a minibatch), and 3) optimizing the weights of the neural network being trained to minimize the distances between the corresponding vectors. This can be considered as a variant of the Iterative Closest Points (ICP) algorithm, common in geometric computer vision, although ICP typically operates on sensor point clouds and linear transforms instead of random sample sets and neural nonlinear transforms. We demonstrate the algorithm on simple synthetic data and MNIST data. We furthermore demonstrate that the algorithm is capable of handling distributions with both continuous and discrete variables.