 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Fatigued Movements for Virtual Character Animation
Oct 12, 2023Virtual character animation and movement synthesis have advanced rapidly during recent years, especially through a combination of extensive motion capture datasets and machine learning. A remaining challenge is interactively simulating characters that fatigue when performing extended motions, which is indispensable for the realism of generated animations. However, capturing such movements is problematic, as performing movements like backflips with fatigued variations up to exhaustion raises capture cost and risk of injury. Surprisingly, little research has been done on faithful fatigue modeling. To address this, we propose a deep reinforcement learning-based approach, which -- for the first time in literature -- generates control policies for full-body physically simulated agents aware of cumulative fatigue. For this, we first leverage Generative Adversarial Imitation Learning (GAIL) to learn an expert policy for the skill; Second, we learn a fatigue policy by limiting the generated constant torque bounds based on endurance time to non-linear, state- and time-dependent limits in the joint-actuation space using a Three-Compartment Controller (3CC) model. Our results demonstrate that agents can adapt to different fatigue and rest rates interactively, and discover realistic recovery strategies without the need for any captured data of fatigued movement.
* 16 pages, 22 figures. To be published in ACM SIGGRAPH Asia Conference Papers 2023. ACM ISBN 979-8-4007-0315-7/23/12
Understanding the Evolution of Linear Regions in Deep Reinforcement Learning
Oct 24, 2022



Policies produced by deep reinforcement learning are typically characterised by their learning curves, but they remain poorly understood in many other respects. ReLU-based policies result in a partitioning of the input space into piecewise linear regions. We seek to understand how observed region counts and their densities evolve during deep reinforcement learning using empirical results that span a range of continuous control tasks and policy network dimensions. Intuitively, we may expect that during training, the region density increases in the areas that are frequently visited by the policy, thereby affording fine-grained control. We use recent theoretical and empirical results for the linear regions induced by neural networks in supervised learning settings for grounding and comparison of our results. Empirically, we find that the region density increases only moderately throughout training, as measured along fixed trajectories coming from the final policy. However, the trajectories themselves also increase in length during training, and thus the region densities decrease as seen from the perspective of the current trajectory. Our findings suggest that the complexity of deep reinforcement learning policies does not principally emerge from a significant growth in the complexity of functions observed on-and-around trajectories of the policy.
ALLSTEPS: Curriculum-driven Learning of Stepping Stone Skills
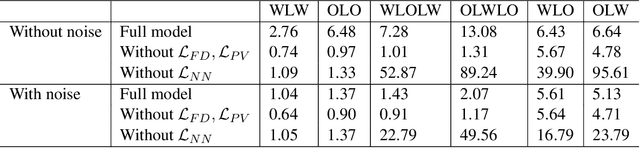
May 09, 2020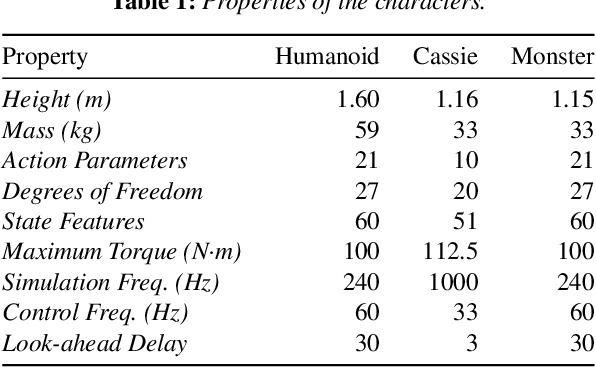
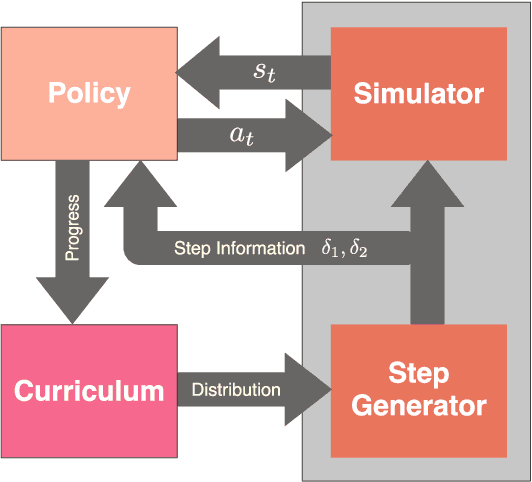

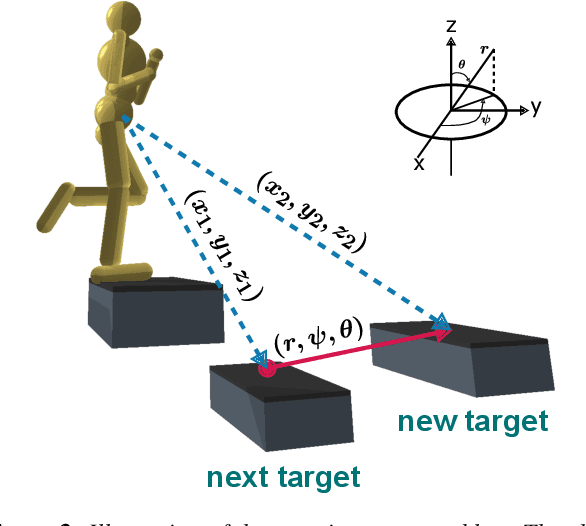
Humans are highly adept at walking in environments with foot placement constraints, including stepping-stone scenarios where the footstep locations are fully constrained. Finding good solutions to stepping-stone locomotion is a longstanding and fundamental challenge for animation and robotics. We present fully learned solutions to this difficult problem using reinforcement learning. We demonstrate the importance of a curriculum for efficient learning and evaluate four possible curriculum choices compared to a non-curriculum baseline. Results are presented for a simulated human character, a realistic bipedal robot simulation and a monster character, in each case producing robust, plausible motions for challenging stepping stone sequences and terrains.
Learning to Correspond Dynamical Systems
Dec 23, 2019
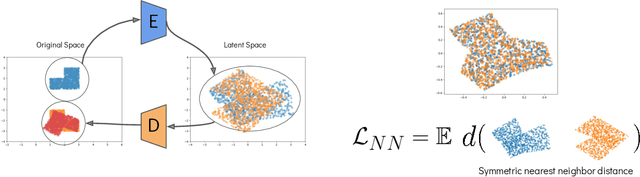
Many dynamical systems exhibit similar structure, as often captured by hand-designed simplified models that can be used for analysis and control. We develop a method for learning to correspond pairs of dynamical systems via a learned latent dynamical system. Given trajectory data from two dynamical systems, we learn a shared latent state space and a shared latent dynamics model, along with an encoder-decoder pair for each of the original systems. With the learned correspondences in place, we can use a simulation of one system to produce an imagined motion of its counterpart. We can also simulate in the learned latent dynamics and synthesize the motions of both corresponding systems, as a form of bisimulation. We demonstrate the approach using pairs of controlled bipedal walkers, as well as by pairing a walker with a controlled pendulum.