 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Movement Control Optimization Landscapes
Paper and Code
Sep 18, 2019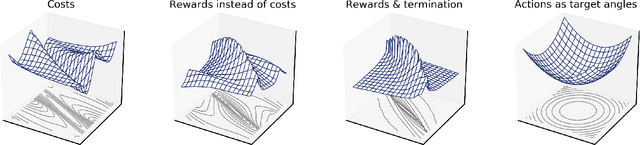
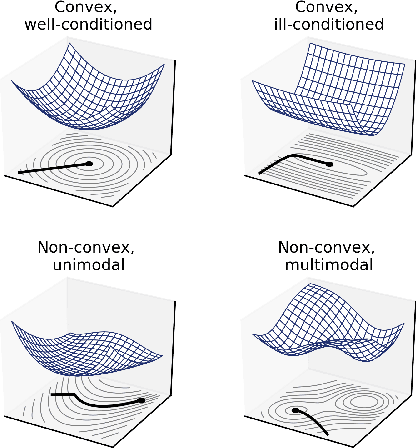

A large body of animation research focuses on optimization of movement control, either as action sequences or policy parameters. However, as closed-form expressions of the objective functions are often not available, our understanding of the optimization problems is limited. Building on recent work on analyzing neural network training, we contribute novel visualizations of high-dimensional control optimization landscapes; this yields insights into why control optimization is hard and why common practices like early termination and spline-based action parameterizations make optimization easier. For example, our experiments show how trajectory optimization can become increasingly ill-conditioned with longer trajectories, but parameterizing control as partial target states - e.g., target angles converted to torques using a PD-controller - can act as an efficient preconditioner. Both our visualizations and quantitative empirical data also indicate that neural network policy optimization scales better than trajectory optimization for long planning horizons. Our work advances the understanding of movement optimization and our visualizations should also provide value in educational use.