 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Explicit Object-Centric Representations with Vision Transformers
Paper and Code
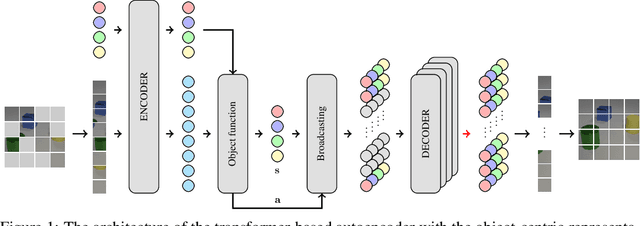
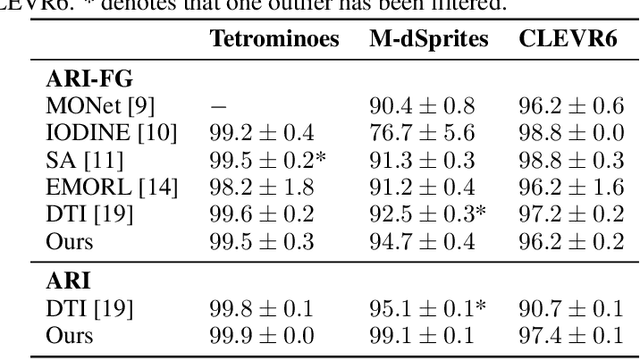
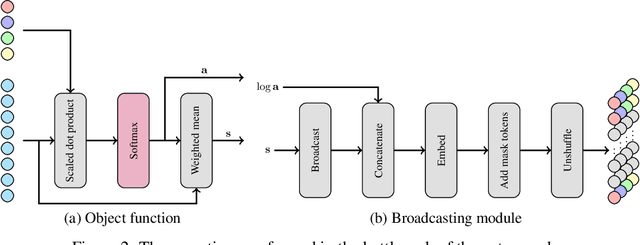
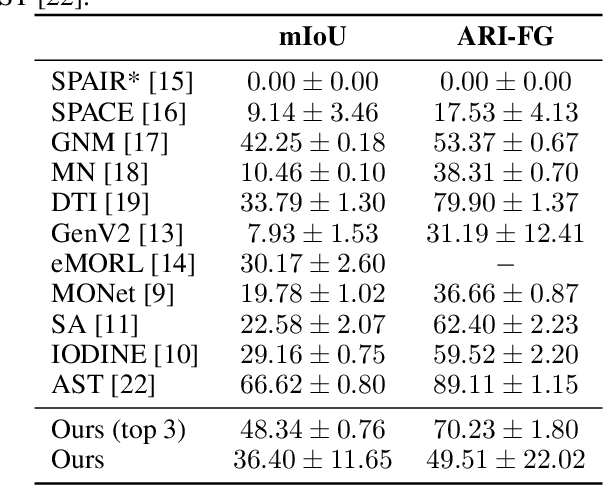
With the recent successful adaptation of transformers to the vision domain, particularly when trained in a self-supervised fashion, it has been shown that vision transformers can learn impressive object-reasoning-like behaviour and features expressive for the task of object segmentation in images. In this paper, we build on the self-supervision task of masked autoencoding and explore its effectiveness for explicitly learning object-centric representations with transformers. To this end, we design an object-centric autoencoder using transformers only and train it end-to-end to reconstruct full images from unmasked patches. We show that the model efficiently learns to decompose simple scenes as measured by segmentation metrics on several multi-object benchmarks.