 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgejina-embeddings-v3: Multilingual Embeddings With Task LoRA
Paper and Code
Sep 17, 2024


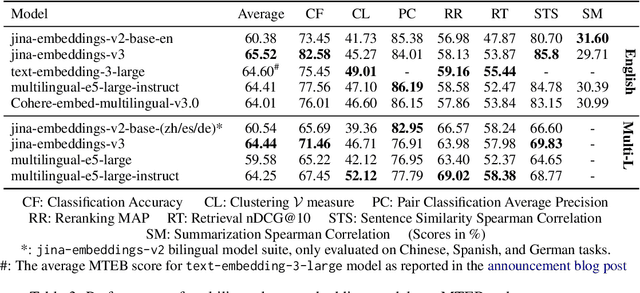
We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens. The model includes a set of task-specific Low-Rank Adaptation (LoRA) adapters to generate high-quality embeddings for query-document retrieval, clustering, classification, and text matching. Additionally, Matryoshka Representation Learning is integrated into the training process, allowing flexible truncation of embedding dimensions without compromising performance. Evaluation on the MTEB benchmark shows that jina-embeddings-v3 outperforms the latest proprietary embeddings from OpenAI and Cohere on English tasks, while achieving superior performance compared to multilingual-e5-large-instruct across all multilingual tasks.