 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-CoT: Enhancing Granularity and Generalization in Image Editing
Apr 27, 2026Unified multi-modal understanding/generative models have shown improved image editing performance by incorporating fine-grained understanding into their Chain-of-Thought (CoT) process. However, a critical question remains underexplored: what forms of CoT and training strategy can jointly enhance both the understanding granularity and generalization? To address this, we propose Meta-CoT, a paradigm that performs a two-level decomposition of any single-image editing operation with two key properties: (1) Decomposability. We observe that any editing intention can be represented as a triplet - (task, target, required understanding ability). Inspired by this, Meta-CoT decomposes both the editing task and the target, generating task-specific CoT and traversing editing operations on all targets. This decomposition enhances the model's understanding granularity of editing operations and guides it to learn each element of the triplet during training, substantially improving the editing capability. (2) Generalizability. In the second decomposition level, we further break down editing tasks into five fundamental meta-tasks. We find that training on these five meta-tasks, together with the other two elements of the triplet, is sufficient to achieve strong generalization across diverse, unseen editing tasks. To further align the model's editing behavior with its CoT reasoning, we introduce the CoT-Editing Consistency Reward, which encourages more accurate and effective utilization of CoT information during editing. Experiments demonstrate that our method achieves an overall 15.8% improvement across 21 editing tasks, and generalizes effectively to unseen editing tasks when trained on only a small set of meta-tasks. Our code, benchmark, and model are released at https://shiyi-zh0408.github.io/projectpages/Meta-CoT/
Hierarchical SVG Tokenization: Learning Compact Visual Programs for Scalable Vector Graphics Modeling
Apr 06, 2026Recent large language models have shifted SVG generation from differentiable rendering optimization to autoregressive program synthesis. However, existing approaches still rely on generic byte-level tokenization inherited from natural language processing, which poorly reflects the geometric structure of vector graphics. Numerical coordinates are fragmented into discrete symbols, destroying spatial relationships and introducing severe token redundancy, often leading to coordinate hallucination and inefficient long-sequence generation. To address these challenges, we propose HiVG, a hierarchical SVG tokenization framework tailored for autoregressive vector graphics generation. HiVG decomposes raw SVG strings into structured \textit{atomic tokens} and further compresses executable command--parameter groups into geometry-constrained \textit{segment tokens}, substantially improving sequence efficiency while preserving syntactic validity. To further mitigate spatial mismatch, we introduce a Hierarchical Mean--Noise (HMN) initialization strategy that injects numerical ordering signals and semantic priors into new token embeddings. Combined with a curriculum training paradigm that progressively increases program complexity, HiVG enables more stable learning of executable SVG programs. Extensive experiments on both text-to-SVG and image-to-SVG tasks demonstrate improved generation fidelity, spatial consistency, and sequence efficiency compared with conventional tokenization schemes.
Generative Visual Chain-of-Thought for Image Editing
Mar 02, 2026Existing image editing methods struggle to perceive where to edit, especially under complex scenes and nuanced spatial instructions. To address this issue, we propose Generative Visual Chain-of-Thought (GVCoT), a unified framework that performs native visual reasoning by first generating spatial cues to localize the target region and then executing the edit. Unlike prior text-only CoT or tool-dependent visual CoT paradigms, GVCoT jointly optimizes visual tokens generated during the reasoning and editing phases in an end-to-end manner. This way fosters the emergence of innate spatial reasoning ability and enables more effective utilization of visual-domain cues. The main challenge of training GCVoT lies in the scarcity of large-scale editing data with precise edit region annotations; to this end, we construct GVCoT-Edit-Instruct, a dataset of 1.8M high-quality samples spanning 19 tasks. We adopt a progressive training strategy: supervised fine-tuning to build foundational localization ability in reasoning trace before final editing, followed by reinforcement learning to further improve reasoning and editing quality. Finally, we introduce SREdit-Bench, a new benchmark designed to comprehensively stress-test models under sophisticated scenes and fine-grained referring expressions. Experiments demonstrate that GVCoT consistently outperforms state-of-the-art models on SREdit-Bench and ImgEdit. We hope our GVCoT will inspire future research toward interpretable and precise image editing.
Benchmarking Semantic Segmentation Models via Appearance and Geometry Attribute Editing
Mar 02, 2026Semantic segmentation takes pivotal roles in various applications such as autonomous driving and medical image analysis. When deploying segmentation models in practice, it is critical to test their behaviors in varied and complex scenes in advance. In this paper, we construct an automatic data generation pipeline Gen4Seg to stress-test semantic segmentation models by generating various challenging samples with different attribute changes. Beyond previous evaluation paradigms focusing solely on global weather and style transfer, we investigate variations in both appearance and geometry attributes at the object and image level. These include object color, material, size, position, as well as image-level variations such as weather and style. To achieve this, we propose to edit visual attributes of existing real images with precise control of structural information, empowered by diffusion models. In this way, the existing segmentation labels can be reused for the edited images, which greatly reduces the labor costs. Using our pipeline, we construct two new benchmarks, Pascal-EA and COCO-EA. We benchmark a wide variety of semantic segmentation models, spanning from closed-set models to open-vocabulary large models. We have several key findings: 1) advanced open-vocabulary models do not exhibit greater robustness compared to closed-set methods under geometric variations; 2) data augmentation techniques, such as CutOut and CutMix, are limited in enhancing robustness against appearance variations; 3) our pipeline can also be employed as a data augmentation tool and improve both in-distribution and out-of-distribution performances. Our work suggests the potential of generative models as effective tools for automatically analyzing segmentation models, and we hope our findings will assist practitioners and researchers in developing more robust and reliable segmentation models.
TAG-MoE: Task-Aware Gating for Unified Generative Mixture-of-Experts
Jan 12, 2026Unified image generation and editing models suffer from severe task interference in dense diffusion transformers architectures, where a shared parameter space must compromise between conflicting objectives (e.g., local editing v.s. subject-driven generation). While the sparse Mixture-of-Experts (MoE) paradigm is a promising solution, its gating networks remain task-agnostic, operating based on local features, unaware of global task intent. This task-agnostic nature prevents meaningful specialization and fails to resolve the underlying task interference. In this paper, we propose a novel framework to inject semantic intent into MoE routing. We introduce a Hierarchical Task Semantic Annotation scheme to create structured task descriptors (e.g., scope, type, preservation). We then design Predictive Alignment Regularization to align internal routing decisions with the task's high-level semantics. This regularization evolves the gating network from a task-agnostic executor to a dispatch center. Our model effectively mitigates task interference, outperforming dense baselines in fidelity and quality, and our analysis shows that experts naturally develop clear and semantically correlated specializations.
Re-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
Jan 08, 2026In-context image generation and editing (ICGE) enables users to specify visual concepts through interleaved image-text prompts, demanding precise understanding and faithful execution of user intent. Although recent unified multimodal models exhibit promising understanding capabilities, these strengths often fail to transfer effectively to image generation. We introduce Re-Align, a unified framework that bridges the gap between understanding and generation through structured reasoning-guided alignment. At its core lies the In-Context Chain-of-Thought (IC-CoT), a structured reasoning paradigm that decouples semantic guidance and reference association, providing clear textual target and mitigating confusion among reference images. Furthermore, Re-Align introduces an effective RL training scheme that leverages a surrogate reward to measure the alignment between structured reasoning text and the generated image, thereby improving the model's overall performance on ICGE tasks. Extensive experiments verify that Re-Align outperforms competitive methods of comparable model scale and resources on both in-context image generation and editing tasks.
ConMo: Controllable Motion Disentanglement and Recomposition for Zero-Shot Motion Transfer
Apr 03, 2025



The development of Text-to-Video (T2V) generation has made motion transfer possible, enabling the control of video motion based on existing footage. However, current methods have two limitations: 1) struggle to handle multi-subjects videos, failing to transfer specific subject motion; 2) struggle to preserve the diversity and accuracy of motion as transferring to subjects with varying shapes. To overcome these, we introduce \textbf{ConMo}, a zero-shot framework that disentangle and recompose the motions of subjects and camera movements. ConMo isolates individual subject and background motion cues from complex trajectories in source videos using only subject masks, and reassembles them for target video generation. This approach enables more accurate motion control across diverse subjects and improves performance in multi-subject scenarios. Additionally, we propose soft guidance in the recomposition stage which controls the retention of original motion to adjust shape constraints, aiding subject shape adaptation and semantic transformation. Unlike previous methods, ConMo unlocks a wide range of applications, including subject size and position editing, subject removal, semantic modifications, and camera motion simulation. Extensive experiments demonstrate that ConMo significantly outperforms state-of-the-art methods in motion fidelity and semantic consistency. The code is available at https://github.com/Andyplus1/ConMo.
PGP-SAM: Prototype-Guided Prompt Learning for Efficient Few-Shot Medical Image Segmentation
Jan 12, 2025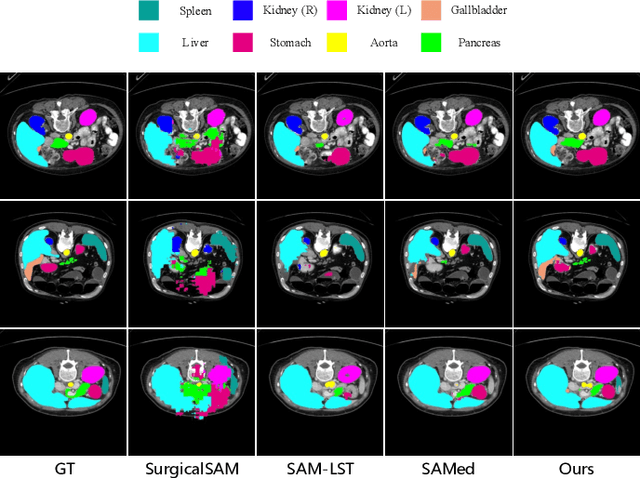



The Segment Anything Model (SAM) has demonstrated strong and versatile segmentation capabilities, along with intuitive prompt-based interactions. However, customizing SAM for medical image segmentation requires massive amounts of pixel-level annotations and precise point- or box-based prompt designs. To address these challenges, we introduce PGP-SAM, a novel prototype-based few-shot tuning approach that uses limited samples to replace tedious manual prompts. Our key idea is to leverage inter- and intra-class prototypes to capture class-specific knowledge and relationships. We propose two main components: (1) a plug-and-play contextual modulation module that integrates multi-scale information, and (2) a class-guided cross-attention mechanism that fuses prototypes and features for automatic prompt generation. Experiments on a public multi-organ dataset and a private ventricle dataset demonstrate that PGP-SAM achieves superior mean Dice scores compared with existing prompt-free SAM variants, while using only 10\% of the 2D slices.
Polyp-E: Benchmarking the Robustness of Deep Segmentation Models via Polyp Editing
Oct 22, 2024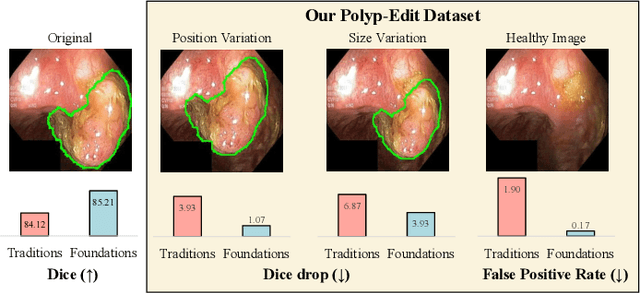
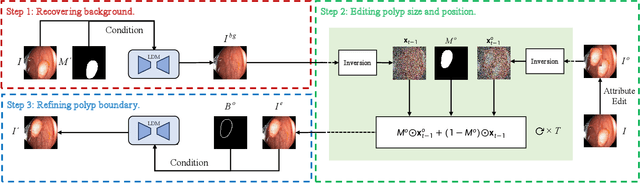
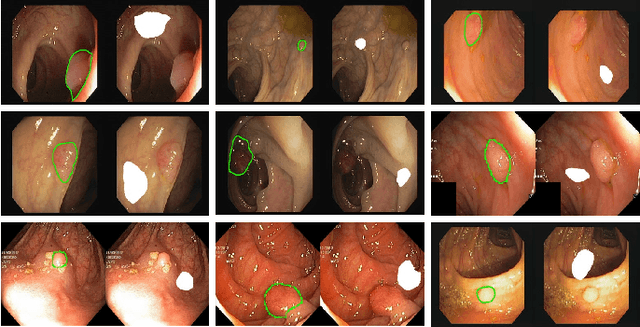
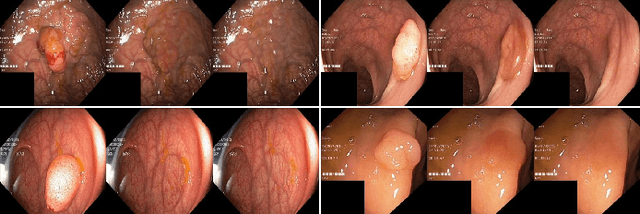
Automatic polyp segmentation is helpful to assist clinical diagnosis and treatment. In daily clinical practice, clinicians exhibit robustness in identifying polyps with both location and size variations. It is uncertain if deep segmentation models can achieve comparable robustness in automated colonoscopic analysis. To benchmark the model robustness, we focus on evaluating the robustness of segmentation models on the polyps with various attributes (e.g. location and size) and healthy samples. Based on the Latent Diffusion Model, we perform attribute editing on real polyps and build a new dataset named Polyp-E. Our synthetic dataset boasts exceptional realism, to the extent that clinical experts find it challenging to discern them from real data. We evaluate several existing polyp segmentation models on the proposed benchmark. The results reveal most of the models are highly sensitive to attribute variations. As a novel data augmentation technique, the proposed editing pipeline can improve both in-distribution and out-of-distribution generalization ability. The code and datasets will be released.
Benchmarking Segmentation Models with Mask-Preserved Attribute Editing
Mar 10, 2024



When deploying segmentation models in practice, it is critical to evaluate their behaviors in varied and complex scenes. Different from the previous evaluation paradigms only in consideration of global attribute variations (e.g. adverse weather), we investigate both local and global attribute variations for robustness evaluation. To achieve this, we construct a mask-preserved attribute editing pipeline to edit visual attributes of real images with precise control of structural information. Therefore, the original segmentation labels can be reused for the edited images. Using our pipeline, we construct a benchmark covering both object and image attributes (e.g. color, material, pattern, style). We evaluate a broad variety of semantic segmentation models, spanning from conventional close-set models to recent open-vocabulary large models on their robustness to different types of variations. We find that both local and global attribute variations affect segmentation performances, and the sensitivity of models diverges across different variation types. We argue that local attributes have the same importance as global attributes, and should be considered in the robustness evaluation of segmentation models. Code: https://github.com/PRIS-CV/Pascal-EA.