 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPS: Information Elicitation with Reinforcement Prompt Selection
Apr 15, 2026Large language models (LLMs) have shown remarkable capabilities in dialogue generation and reasoning, yet their effectiveness in eliciting user-known but concealed information in open-ended conversations remains limited. In many interactive AI applications, such as personal assistants, tutoring systems, and legal or clinical support, users often withhold sensitive or uncertain information due to privacy concerns, ambiguity, or social hesitation. This makes it challenging for LLMs to gather complete and contextually relevant inputs. In this work, we define the problem of information elicitation in open-ended dialogue settings and propose Reinforcement Prompt Selection (RPS), a lightweight reinforcement learning framework that formulates prompt selection as a sequential decision-making problem. To analyze this problem in a controlled setting, we design a synthetic experiment, where a reinforcement learning agent outperforms a random query baseline, illustrating the potential of policy-based approaches for adaptive information elicitation. Building on this insight, RPS learns a policy over a pool of prompts to adaptively elicit concealed or incompletely expressed information from users through dialogue. We also introduce IELegal, a new benchmark dataset constructed from real legal case documents, which simulates dialogue-based information elicitation tasks aimed at uncovering case-relevant facts. In this setting, RPS outperforms static prompt baselines, demonstrating the effectiveness of adaptive prompt selection for eliciting critical information in LLM-driven dialogue systems.
Towards grounded autonomous research: an end-to-end LLM mini research loop on published computational physics
Apr 14, 2026Recent autonomous LLM agents have demonstrated end-to-end automation of machine-learning research. Real-world physical science is intrinsically harder, requiring deep reasoning bounded by physical truth and, because real systems are too complex to study in isolation, almost always built on existing literature. We focus on the smallest meaningful unit of such research, a mini research loop in which an agent reads a paper, reproduces it, critiques it, and extends it. We test this loop in two complementary regimes: scale and depth. At scale, across 111 open-access computational physics papers, an agent autonomously runs the read-plan-compute-compare loop and, without being asked to critique, raises substantive concerns on ~42% of papers - 97.7% of which require execution to surface. In depth, for one Nature Communications paper on multiscale simulation of a 2D-material MOSFET, the agent runs new calculations missing from the original and produces, unsupervised, a publishable Comment -- composed, figured, typeset, and PDF-iterated -- that revises the paper's headline conclusion.
From Experiments to Expertise: Scientific Knowledge Consolidation for AI-Driven Computational Research
Mar 13, 2026While large language models (LLMs) have transformed AI agents into proficient executors of computational materials science, performing a hundred simulations does not make a researcher. What distinguishes research from routine execution is the progressive accumulation of knowledge -- learning which approaches fail, recognizing patterns across systems, and applying understanding to new problems. However, the prevailing paradigm in AI-driven computational science treats each execution in isolation, largely discarding hard-won insights between runs. Here we present QMatSuite, an open-source platform closing this gap. Agents record findings with full provenance, retrieve knowledge before new calculations, and in dedicated reflection sessions correct erroneous findings and synthesize observations into cross-compound patterns. In benchmarks on a six-step quantum-mechanical simulation workflow, accumulated knowledge reduces reasoning overhead by 67% and improves accuracy from 47% to 3% deviation from literature -- and when transferred to an unfamiliar material, achieves 1% deviation with zero pipeline failures.
Polyp-E: Benchmarking the Robustness of Deep Segmentation Models via Polyp Editing
Oct 22, 2024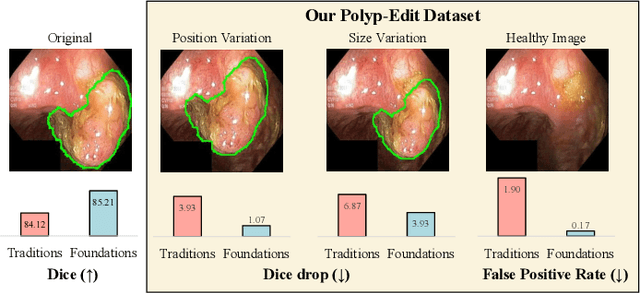
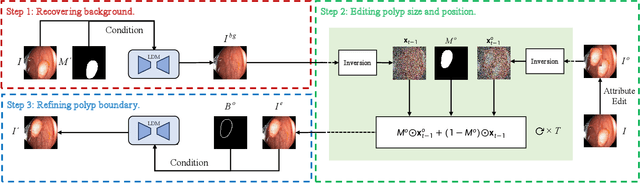
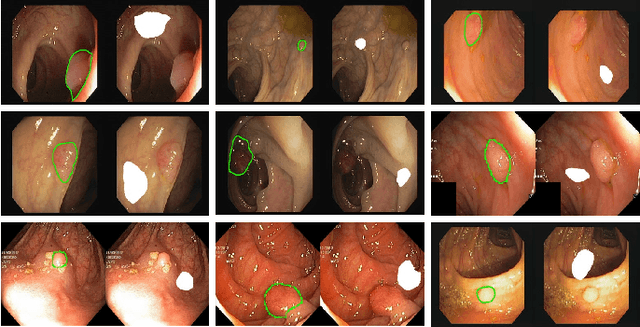
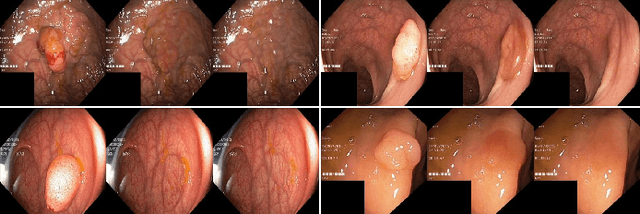
Automatic polyp segmentation is helpful to assist clinical diagnosis and treatment. In daily clinical practice, clinicians exhibit robustness in identifying polyps with both location and size variations. It is uncertain if deep segmentation models can achieve comparable robustness in automated colonoscopic analysis. To benchmark the model robustness, we focus on evaluating the robustness of segmentation models on the polyps with various attributes (e.g. location and size) and healthy samples. Based on the Latent Diffusion Model, we perform attribute editing on real polyps and build a new dataset named Polyp-E. Our synthetic dataset boasts exceptional realism, to the extent that clinical experts find it challenging to discern them from real data. We evaluate several existing polyp segmentation models on the proposed benchmark. The results reveal most of the models are highly sensitive to attribute variations. As a novel data augmentation technique, the proposed editing pipeline can improve both in-distribution and out-of-distribution generalization ability. The code and datasets will be released.
Multi-view Data Classification with a Label-driven Auto-weighted Strategy
Jan 03, 2022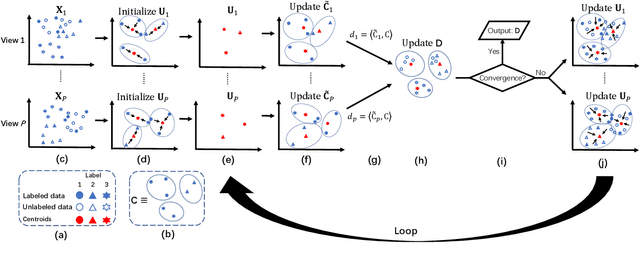
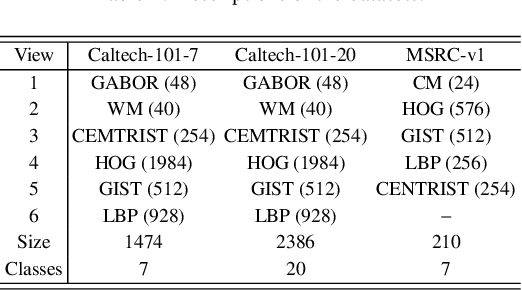
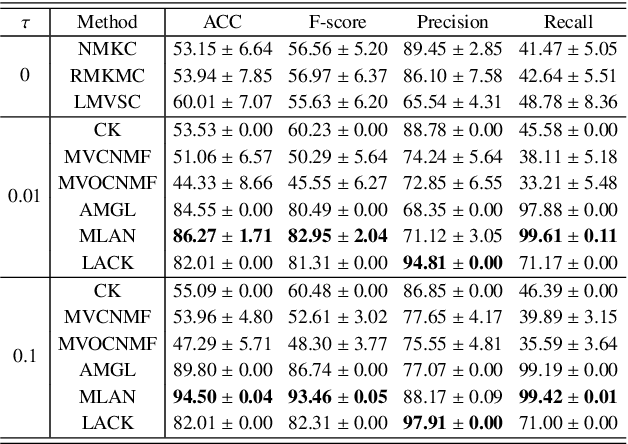
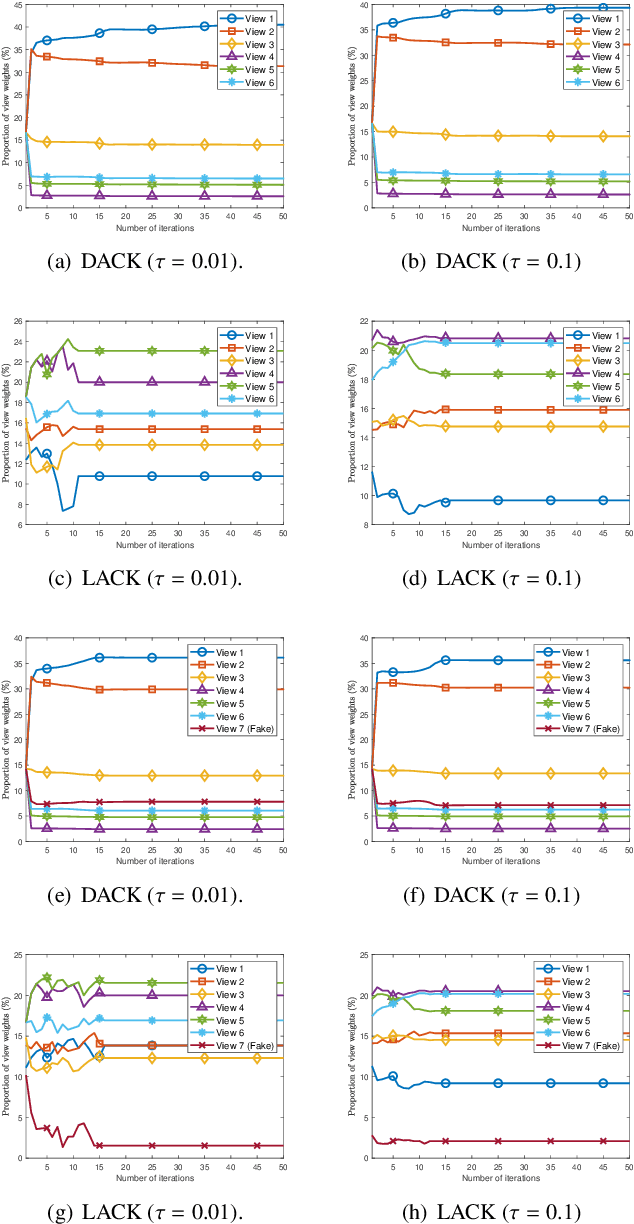
Distinguishing the importance of views has proven to be quite helpful for semi-supervised multi-view learning models. However, existing strategies cannot take advantage of semi-supervised information, only distinguishing the importance of views from a data feature perspective, which is often influenced by low-quality views then leading to poor performance. In this paper, by establishing a link between labeled data and the importance of different views, we propose an auto-weighted strategy to evaluate the importance of views from a label perspective to avoid the negative impact of unimportant or low-quality views. Based on this strategy, we propose a transductive semi-supervised auto-weighted multi-view classification model. The initialization of the proposed model can be effectively determined by labeled data, which is practical. The model is decoupled into three small-scale sub-problems that can efficiently be optimized with a local convergence guarantee. The experimental results on classification tasks show that the proposed method achieves optimal or sub-optimal classification accuracy at the lowest computational cost compared to other related methods, and the weight change experiments show that our proposed strategy can distinguish view importance more accurately than other related strategies on multi-view datasets with low-quality views.
Partially Shared Semi-supervised Deep Matrix Factorization with Multi-view Data
Dec 02, 2020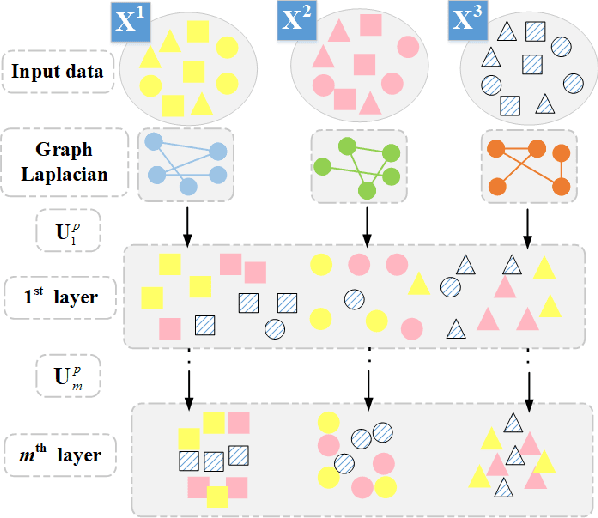
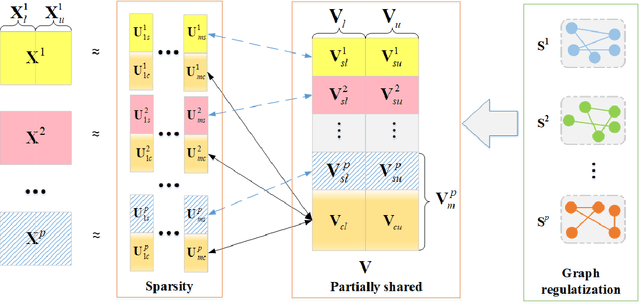
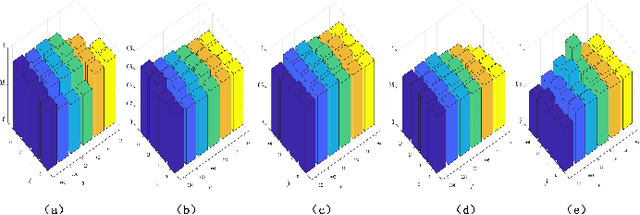

Since many real-world data can be described from multiple views, multi-view learning has attracted considerable attention. Various methods have been proposed and successfully applied to multi-view learning, typically based on matrix factorization models. Recently, it is extended to the deep structure to exploit the hierarchical information of multi-view data, but the view-specific features and the label information are seldom considered. To address these concerns, we present a partially shared semi-supervised deep matrix factorization model (PSDMF). By integrating the partially shared deep decomposition structure, graph regularization and the semi-supervised regression model, PSDMF can learn a compact and discriminative representation through eliminating the effects of uncorrelated information. In addition, we develop an efficient iterative updating algorithm for PSDMF. Extensive experiments on five benchmark datasets demonstrate that PSDMF can achieve better performance than the state-of-the-art multi-view learning approaches. The MATLAB source code is available at https://github.com/libertyhhn/PartiallySharedDMF.