 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-to-Defend: Safety-Aware Reasoning Can Defend Large Language Models from Jailbreaking
Feb 18, 2025The reasoning abilities of Large Language Models (LLMs) have demonstrated remarkable advancement and exceptional performance across diverse domains. However, leveraging these reasoning capabilities to enhance LLM safety against adversarial attacks and jailbreak queries remains largely unexplored. To bridge this gap, we propose Reasoning-to-Defend (R2D), a novel training paradigm that integrates safety reflections of queries and responses into LLMs' generation process, unlocking a safety-aware reasoning mechanism. This approach enables self-evaluation at each reasoning step to create safety pivot tokens as indicators of the response's safety status. Furthermore, in order to improve the learning efficiency of pivot token prediction, we propose Contrastive Pivot Optimization(CPO), which enhances the model's ability to perceive the safety status of dialogues. Through this mechanism, LLMs dynamically adjust their response strategies during reasoning, significantly enhancing their defense capabilities against jailbreak attacks. Extensive experimental results demonstrate that R2D effectively mitigates various attacks and improves overall safety, highlighting the substantial potential of safety-aware reasoning in strengthening LLMs' robustness against jailbreaks.
DiffusionAttacker: Diffusion-Driven Prompt Manipulation for LLM Jailbreak
Dec 23, 2024



Large Language Models (LLMs) are susceptible to generating harmful content when prompted with carefully crafted inputs, a vulnerability known as LLM jailbreaking. As LLMs become more powerful, studying jailbreak methods is critical to enhancing security and aligning models with human values. Traditionally, jailbreak techniques have relied on suffix addition or prompt templates, but these methods suffer from limited attack diversity. This paper introduces DiffusionAttacker, an end-to-end generative approach for jailbreak rewriting inspired by diffusion models. Our method employs a sequence-to-sequence (seq2seq) text diffusion model as a generator, conditioning on the original prompt and guiding the denoising process with a novel attack loss. Unlike previous approaches that use autoregressive LLMs to generate jailbreak prompts, which limit the modification of already generated tokens and restrict the rewriting space, DiffusionAttacker utilizes a seq2seq diffusion model, allowing more flexible token modifications. This approach preserves the semantic content of the original prompt while producing harmful content. Additionally, we leverage the Gumbel-Softmax technique to make the sampling process from the diffusion model's output distribution differentiable, eliminating the need for iterative token search. Extensive experiments on Advbench and Harmbench demonstrate that DiffusionAttacker outperforms previous methods across various evaluation metrics, including attack success rate (ASR), fluency, and diversity.
ATM: Adversarial Tuning Multi-agent System Makes a Robust Retrieval-Augmented Generator
May 28, 2024Large language model (LLM) has proven to benefit a lot from retrieval augmentation in alleviating hallucinations confronted with knowledge-intensive questions. Retrieval-augmented generation (RAG) adopts IR-based techniques utilizing semantic-relevant documents as the generator's input context and realizes external knowledge injection. However, on today's Internet which is flooded with content generated by LLMs, there are too many "related yet useless" documents or even fake knowledge fabricated by LLMs, which will introduce extra noise to the generator and distract it from giving correct results. To this end, we regard the training of the RAG generator model as a multi-agent adversarial-defensive system, guiding the generator to have a better taste of whether a specific document helps answer the question through the Adversarial Tuning in a Multi-agent (ATM) system to strengthen the generator's robustness in an RAG pipeline. After rounds of multi-agent iterative tuning, we find that the ATM Generator can eventually discriminate useful documents amongst LLM fabrications and achieve better performance than strong baselines.
A Survey of Neural Network Robustness Assessment in Image Recognition
Apr 15, 2024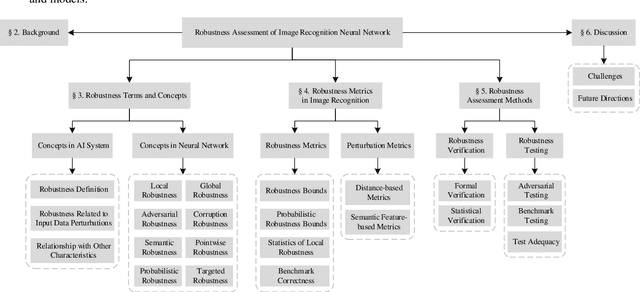

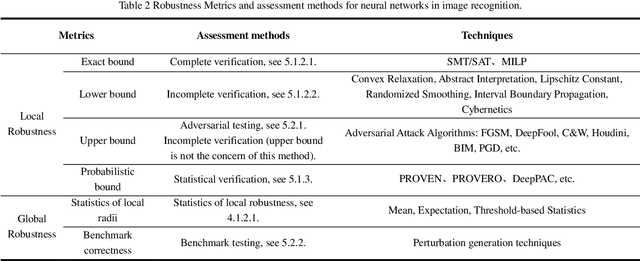
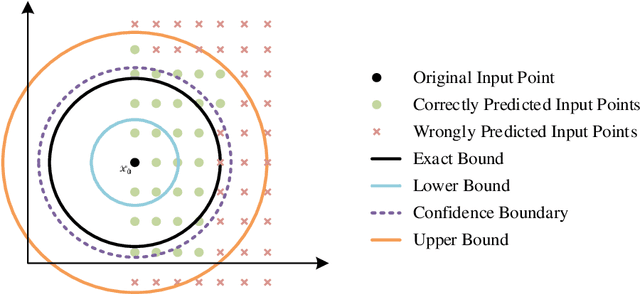
In recent years, there has been significant attention given to the robustness assessment of neural networks. Robustness plays a critical role in ensuring reliable operation of artificial intelligence (AI) systems in complex and uncertain environments. Deep learning's robustness problem is particularly significant, highlighted by the discovery of adversarial attacks on image classification models. Researchers have dedicated efforts to evaluate robustness in diverse perturbation conditions for image recognition tasks. Robustness assessment encompasses two main techniques: robustness verification/ certification for deliberate adversarial attacks and robustness testing for random data corruptions. In this survey, we present a detailed examination of both adversarial robustness (AR) and corruption robustness (CR) in neural network assessment. Analyzing current research papers and standards, we provide an extensive overview of robustness assessment in image recognition. Three essential aspects are analyzed: concepts, metrics, and assessment methods. We investigate the perturbation metrics and range representations used to measure the degree of perturbations on images, as well as the robustness metrics specifically for the robustness conditions of classification models. The strengths and limitations of the existing methods are also discussed, and some potential directions for future research are provided.