 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Decision Transformer for Traffic Coordination
Feb 02, 2026Traffic signal control is a critical challenge in urban transportation, requiring coordination among multiple intersections to optimize network-wide traffic flow. While reinforcement learning has shown promise for adaptive signal control, existing methods struggle with multi-agent coordination and sample efficiency. We introduce MADT (Multi-Agent Decision Transformer), a novel approach that reformulates multi-agent traffic signal control as a sequence modeling problem. MADT extends the Decision Transformer paradigm to multi-agent settings by incorporating: (1) a graph attention mechanism for modeling spatial dependencies between intersections, (2) a|temporal transformer encoder for capturing traffic dynamics, and (3) return-to-go conditioning for target performance specification. Our approach enables offline learning from historical traffic data, with architecture design that facilitates potential online fine-tuning. Experiments on synthetic grid networks and real-world traffic scenarios demonstrate that MADT achieves state-of-the-art performance, reducing average travel time by 5-6% compared to the strongest baseline while exhibiting superior coordination among adjacent intersections.
The End of Reward Engineering: How LLMs Are Redefining Multi-Agent Coordination
Jan 13, 2026Reward engineering, the manual specification of reward functions to induce desired agent behavior, remains a fundamental challenge in multi-agent reinforcement learning. This difficulty is amplified by credit assignment ambiguity, environmental non-stationarity, and the combinatorial growth of interaction complexity. We argue that recent advances in large language models (LLMs) point toward a shift from hand-crafted numerical rewards to language-based objective specifications. Prior work has shown that LLMs can synthesize reward functions directly from natural language descriptions (e.g., EUREKA) and adapt reward formulations online with minimal human intervention (e.g., CARD). In parallel, the emerging paradigm of Reinforcement Learning from Verifiable Rewards (RLVR) provides empirical evidence that language-mediated supervision can serve as a viable alternative to traditional reward engineering. We conceptualize this transition along three dimensions: semantic reward specification, dynamic reward adaptation, and improved alignment with human intent, while noting open challenges related to computational overhead, robustness to hallucination, and scalability to large multi-agent systems. We conclude by outlining a research direction in which coordination arises from shared semantic representations rather than explicitly engineered numerical signals.
Hierarchical GNN-Based Multi-Agent Learning for Dynamic Queue-Jump Lane and Emergency Vehicle Corridor Formation
Jan 07, 2026Emergency vehicles require rapid passage through congested traffic, yet existing strategies fail to adapt to dynamic conditions. We propose a novel hierarchical graph neural network (GNN)-based multi-agent reinforcement learning framework to coordinate connected vehicles for emergency corridor formation. Our approach uses a high-level planner for global strategy and low-level controllers for trajectory execution, utilizing graph attention networks to scale with variable agent counts. Trained via Multi-Agent Proximal Policy Optimization (MAPPO), the system reduces emergency vehicle travel time by 28.3% compared to baselines and 44.6% compared to uncoordinated traffic in simulations. The design achieves near-zero collision rates (0.3%) while maintaining 81% of background traffic efficiency. Ablation and generalization studies confirm the framework's robustness across diverse scenarios. These results demonstrate the effectiveness of combining GNNs with hierarchical learning for intelligent transportation systems.
Geometric and Dynamic Scaling in Deep Transformers
Jan 06, 2026Despite their empirical success, pushing Transformer architectures to extreme depth often leads to a paradoxical failure: representations become increasingly redundant, lose rank, and ultimately collapse. Existing explanations largely attribute this phenomenon to optimization instability or vanishing gradients, yet such accounts fail to explain why collapse persists even under modern normalization and initialization schemes. In this paper, we argue that the collapse of deep Transformers is fundamentally a geometric problem. Standard residual updates implicitly assume that feature accumulation is always beneficial, but offer no mechanism to constrain update directions or to erase outdated information. As depth increases, this leads to systematic drift off the semantic manifold and monotonic feature accumulation, causing representational degeneracy. We propose a unified geometric framework that addresses these failures through two orthogonal principles. First, manifold-constrained hyper-connections restrict residual updates to valid local tangent directions, preventing uncontrolled manifold drift. Second, deep delta learning introduces data-dependent, non-monotonic updates that enable reflection and erasure of redundant features rather than their unconditional accumulation. Together, these mechanisms decouple the direction and sign of feature updates, yielding a stable geometric evolution across depth. We term the resulting architecture the Manifold-Geometric Transformer (MGT). Our analysis predicts that enforcing geometric validity while allowing dynamic erasure is essential for avoiding rank collapse in ultra-deep networks. We outline an evaluation protocol for Transformers exceeding 100 layers to test the hypothesis that geometry, rather than depth itself, is the key limiting factor in deep representation learning.
Facilitating Emergency Vehicle Passage in Congested Urban Areas Using Multi-agent Deep Reinforcement Learning
Feb 23, 2025



Emergency Response Time (ERT) is crucial for urban safety, measuring cities' ability to handle medical, fire, and crime emergencies. In NYC, medical ERT increased 72% from 7.89 minutes in 2014 to 14.27 minutes in 2024, with half of delays due to Emergency Vehicle (EMV) travel times. Each minute's delay in stroke response costs 2 million brain cells, while cardiac arrest survival drops 7-10% per minute. This dissertation advances EMV facilitation through three contributions. First, EMVLight, a decentralized multi-agent reinforcement learning framework, integrates EMV routing with traffic signal pre-emption. It achieved 42.6% faster EMV travel times and 23.5% improvement for other vehicles. Second, the Dynamic Queue-Jump Lane system uses Multi-Agent Proximal Policy Optimization for coordinated lane-clearing in mixed autonomous and human-driven traffic, reducing EMV travel times by 40%. Third, an equity study of NYC Emergency Medical Services revealed disparities across boroughs: Staten Island faces delays due to sparse signalized intersections, while Manhattan struggles with congestion. Solutions include optimized EMS stations and improved intersection designs. These contributions enhance EMV mobility and emergency service equity, offering insights for policymakers and urban planners to develop safer, more efficient transportation systems.
A Survey of Neural Network Robustness Assessment in Image Recognition
Apr 15, 2024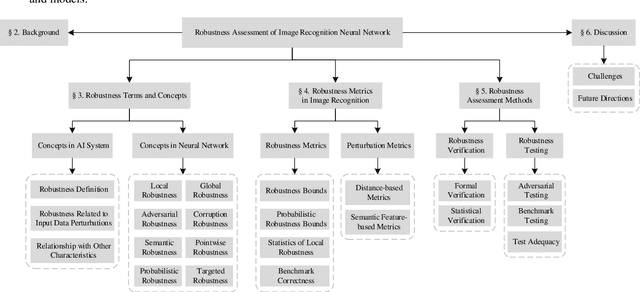

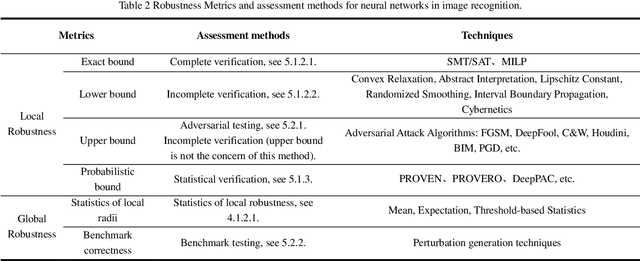
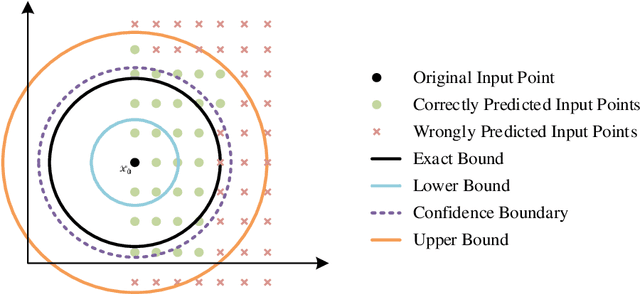
In recent years, there has been significant attention given to the robustness assessment of neural networks. Robustness plays a critical role in ensuring reliable operation of artificial intelligence (AI) systems in complex and uncertain environments. Deep learning's robustness problem is particularly significant, highlighted by the discovery of adversarial attacks on image classification models. Researchers have dedicated efforts to evaluate robustness in diverse perturbation conditions for image recognition tasks. Robustness assessment encompasses two main techniques: robustness verification/ certification for deliberate adversarial attacks and robustness testing for random data corruptions. In this survey, we present a detailed examination of both adversarial robustness (AR) and corruption robustness (CR) in neural network assessment. Analyzing current research papers and standards, we provide an extensive overview of robustness assessment in image recognition. Three essential aspects are analyzed: concepts, metrics, and assessment methods. We investigate the perturbation metrics and range representations used to measure the degree of perturbations on images, as well as the robustness metrics specifically for the robustness conditions of classification models. The strengths and limitations of the existing methods are also discussed, and some potential directions for future research are provided.
Mine yOur owN Anatomy: Revisiting Medical Image Segmentation with Extremely Limited Labels
Sep 28, 2022
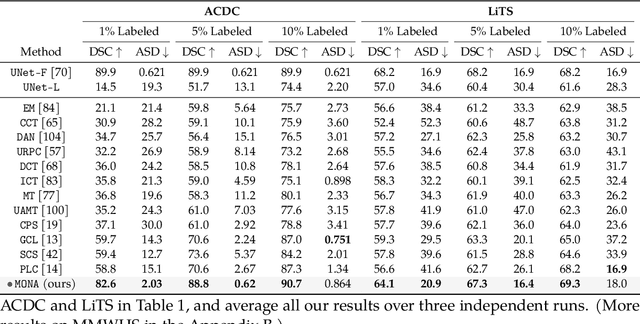
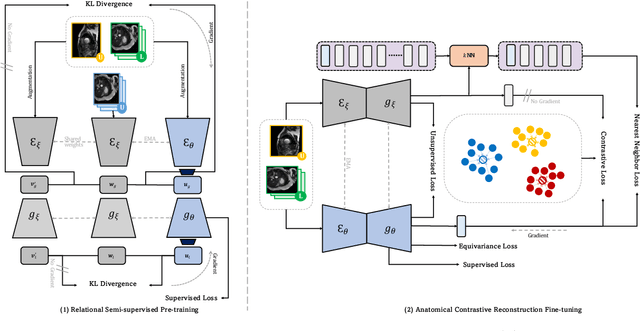
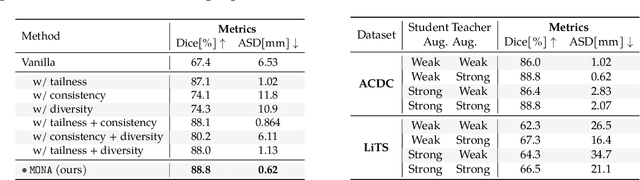
Recent studies on contrastive learning have achieved remarkable performance solely by leveraging few labels in the context of medical image segmentation. Existing methods mainly focus on instance discrimination and invariant mapping. However, they face three common pitfalls: (1) tailness: medical image data usually follows an implicit long-tail class distribution. Blindly leveraging all pixels in training hence can lead to the data imbalance issues, and cause deteriorated performance; (2) consistency: it remains unclear whether a segmentation model has learned meaningful and yet consistent anatomical features due to the intra-class variations between different anatomical features; and (3) diversity: the intra-slice correlations within the entire dataset have received significantly less attention. This motivates us to seek a principled approach for strategically making use of the dataset itself to discover similar yet distinct samples from different anatomical views. In this paper, we introduce a novel semi-supervised medical image segmentation framework termed Mine yOur owN Anatomy (MONA), and make three contributions. First, prior work argues that every pixel equally matters to the model training; we observe empirically that this alone is unlikely to define meaningful anatomical features, mainly due to lacking the supervision signal. We show two simple solutions towards learning invariances - through the use of stronger data augmentations and nearest neighbors. Second, we construct a set of objectives that encourage the model to be capable of decomposing medical images into a collection of anatomical features in an unsupervised manner. Lastly, our extensive results on three benchmark datasets with different labeled settings validate the effectiveness of our proposed MONA which achieves new state-of-the-art under different labeled settings.
EMVLight: a Multi-agent Reinforcement Learning Framework for an Emergency Vehicle Decentralized Routing and Traffic Signal Control System
Jun 29, 2022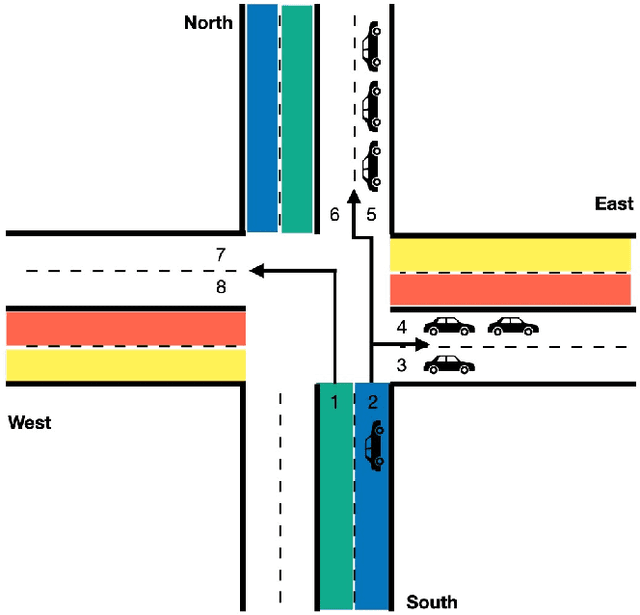

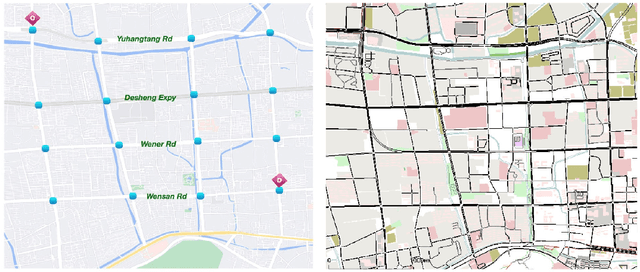

Emergency vehicles (EMVs) play a crucial role in responding to time-critical calls such as medical emergencies and fire outbreaks in urban areas. Existing methods for EMV dispatch typically optimize routes based on historical traffic-flow data and design traffic signal pre-emption accordingly; however, we still lack a systematic methodology to address the coupling between EMV routing and traffic signal control. In this paper, we propose EMVLight, a decentralized reinforcement learning (RL) framework for joint dynamic EMV routing and traffic signal pre-emption. We adopt the multi-agent advantage actor-critic method with policy sharing and spatial discounted factor. This framework addresses the coupling between EMV navigation and traffic signal control via an innovative design of multi-class RL agents and a novel pressure-based reward function. The proposed methodology enables EMVLight to learn network-level cooperative traffic signal phasing strategies that not only reduce EMV travel time but also shortens the travel time of non-EMVs. Simulation-based experiments indicate that EMVLight enables up to a $42.6\%$ reduction in EMV travel time as well as an $23.5\%$ shorter average travel time compared with existing approaches.
A Decentralized Reinforcement Learning Framework for Efficient Passage of Emergency Vehicles
Nov 08, 2021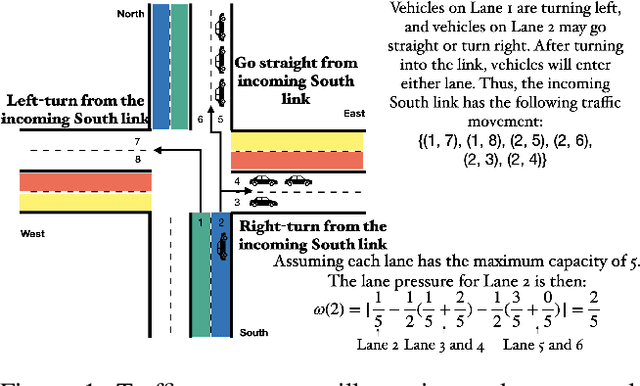

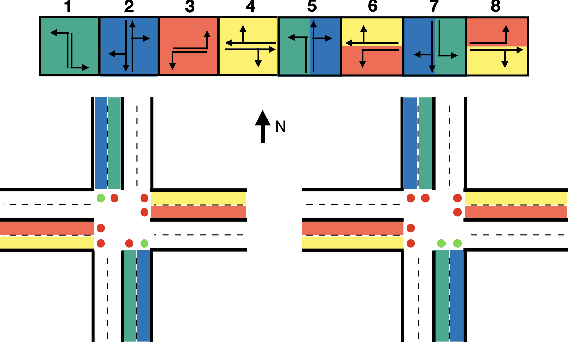
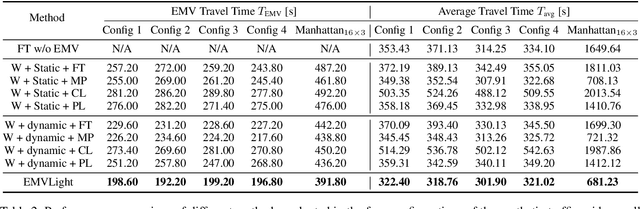
Emergency vehicles (EMVs) play a critical role in a city's response to time-critical events such as medical emergencies and fire outbreaks. The existing approaches to reduce EMV travel time employ route optimization and traffic signal pre-emption without accounting for the coupling between route these two subproblems. As a result, the planned route often becomes suboptimal. In addition, these approaches also do not focus on minimizing disruption to the overall traffic flow. To address these issues, we introduce EMVLight in this paper. This is a decentralized reinforcement learning (RL) framework for simultaneous dynamic routing and traffic signal control. EMVLight extends Dijkstra's algorithm to efficiently update the optimal route for an EMV in real-time as it travels through the traffic network. Consequently, the decentralized RL agents learn network-level cooperative traffic signal phase strategies that reduce EMV travel time and the average travel time of non-EMVs in the network. We have carried out comprehensive experiments with synthetic and real-world maps to demonstrate this benefit. Our results show that EMVLight outperforms benchmark transportation engineering techniques as well as existing RL-based traffic signal control methods.
EMVLight: A Decentralized Reinforcement Learning Framework for Efficient Passage of Emergency Vehicles
Sep 19, 2021Emergency vehicles (EMVs) play a crucial role in responding to time-critical events such as medical emergencies and fire outbreaks in an urban area. The less time EMVs spend traveling through the traffic, the more likely it would help save people's lives and reduce property loss. To reduce the travel time of EMVs, prior work has used route optimization based on historical traffic-flow data and traffic signal pre-emption based on the optimal route. However, traffic signal pre-emption dynamically changes the traffic flow which, in turn, modifies the optimal route of an EMV. In addition, traffic signal pre-emption practices usually lead to significant disturbances in traffic flow and subsequently increase the travel time for non-EMVs. In this paper, we propose EMVLight, a decentralized reinforcement learning (RL) framework for simultaneous dynamic routing and traffic signal control. EMVLight extends Dijkstra's algorithm to efficiently update the optimal route for the EMVs in real time as it travels through the traffic network. The decentralized RL agents learn network-level cooperative traffic signal phase strategies that not only reduce EMV travel time but also reduce the average travel time of non-EMVs in the network. This benefit has been demonstrated through comprehensive experiments with synthetic and real-world maps. These experiments show that EMVLight outperforms benchmark transportation engineering techniques and existing RL-based signal control methods.