 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastDiagnosis: Enhancing Interpretability in Lung Nodule Diagnosis Using Contrastive Learning
Mar 08, 2024With the ongoing development of deep learning, an increasing number of AI models have surpassed the performance levels of human clinical practitioners. However, the prevalence of AI diagnostic products in actual clinical practice remains significantly lower than desired. One crucial reason for this gap is the so-called `black box' nature of AI models. Clinicians' distrust of black box models has directly hindered the clinical deployment of AI products. To address this challenge, we propose ContrastDiagnosis, a straightforward yet effective interpretable diagnosis framework. This framework is designed to introduce inherent transparency and provide extensive post-hoc explainability for deep learning model, making them more suitable for clinical medical diagnosis. ContrastDiagnosis incorporates a contrastive learning mechanism to provide a case-based reasoning diagnostic rationale, enhancing the model's transparency and also offers post-hoc interpretability by highlighting similar areas. High diagnostic accuracy was achieved with AUC of 0.977 while maintain a high transparency and explainability.
DiffuVST: Narrating Fictional Scenes with Global-History-Guided Denoising Models
Dec 12, 2023
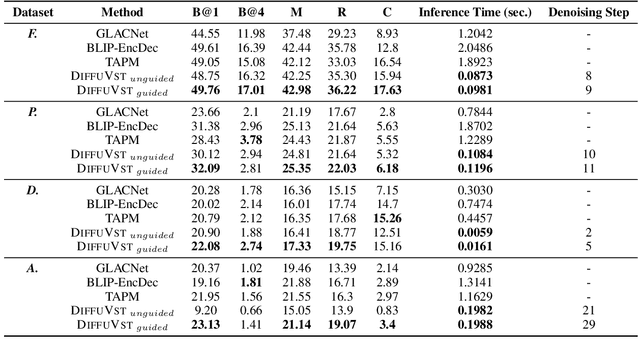
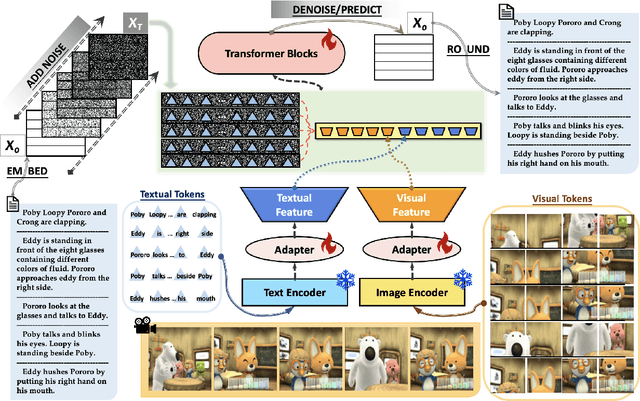
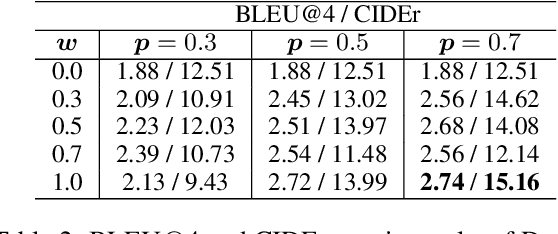
Recent advances in image and video creation, especially AI-based image synthesis, have led to the production of numerous visual scenes that exhibit a high level of abstractness and diversity. Consequently, Visual Storytelling (VST), a task that involves generating meaningful and coherent narratives from a collection of images, has become even more challenging and is increasingly desired beyond real-world imagery. While existing VST techniques, which typically use autoregressive decoders, have made significant progress, they suffer from low inference speed and are not well-suited for synthetic scenes. To this end, we propose a novel diffusion-based system DiffuVST, which models the generation of a series of visual descriptions as a single conditional denoising process. The stochastic and non-autoregressive nature of DiffuVST at inference time allows it to generate highly diverse narratives more efficiently. In addition, DiffuVST features a unique design with bi-directional text history guidance and multimodal adapter modules, which effectively improve inter-sentence coherence and image-to-text fidelity. Extensive experiments on the story generation task covering four fictional visual-story datasets demonstrate the superiority of DiffuVST over traditional autoregressive models in terms of both text quality and inference speed.
Towards Reliable and Explainable AI Model for Solid Pulmonary Nodule Diagnosis
Apr 08, 2022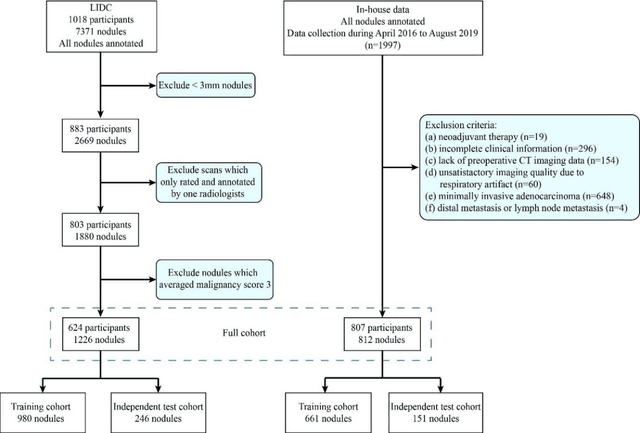
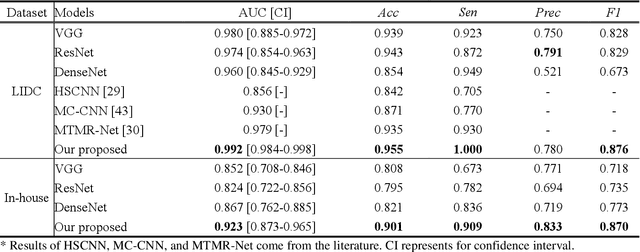
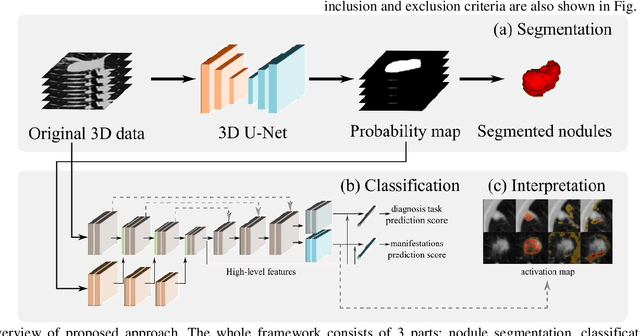
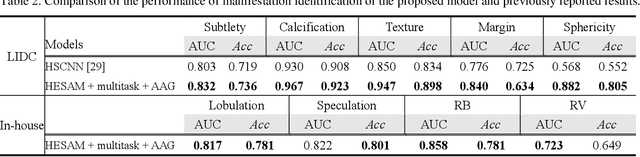
Lung cancer has the highest mortality rate of deadly cancers in the world. Early detection is essential to treatment of lung cancer. However, detection and accurate diagnosis of pulmonary nodules depend heavily on the experiences of radiologists and can be a heavy workload for them. Computer-aided diagnosis (CAD) systems have been developed to assist radiologists in nodule detection and diagnosis, greatly easing the workload while increasing diagnosis accuracy. Recent development of deep learning, greatly improved the performance of CAD systems. However, lack of model reliability and interpretability remains a major obstacle for its large-scale clinical application. In this work, we proposed a multi-task explainable deep-learning model for pulmonary nodule diagnosis. Our neural model can not only predict lesion malignancy but also identify relevant manifestations. Further, the location of each manifestation can also be visualized for visual interpretability. Our proposed neural model achieved a test AUC of 0.992 on LIDC public dataset and a test AUC of 0.923 on our in-house dataset. Moreover, our experimental results proved that by incorporating manifestation identification tasks into the multi-task model, the accuracy of the malignancy classification can also be improved. This multi-task explainable model may provide a scheme for better interaction with the radiologists in a clinical environment.