 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Physics-Driven Neural Network with Parameter Embedding for Generating Quantitative MR Maps from Weighted Images
Aug 11, 2025We propose a deep learning-based approach that integrates MRI sequence parameters to improve the accuracy and generalizability of quantitative image synthesis from clinical weighted MRI. Our physics-driven neural network embeds MRI sequence parameters -- repetition time (TR), echo time (TE), and inversion time (TI) -- directly into the model via parameter embedding, enabling the network to learn the underlying physical principles of MRI signal formation. The model takes conventional T1-weighted, T2-weighted, and T2-FLAIR images as input and synthesizes T1, T2, and proton density (PD) quantitative maps. Trained on healthy brain MR images, it was evaluated on both internal and external test datasets. The proposed method achieved high performance with PSNR values exceeding 34 dB and SSIM values above 0.92 for all synthesized parameter maps. It outperformed conventional deep learning models in accuracy and robustness, including data with previously unseen brain structures and lesions. Notably, our model accurately synthesized quantitative maps for these unseen pathological regions, highlighting its superior generalization capability. Incorporating MRI sequence parameters via parameter embedding allows the neural network to better learn the physical characteristics of MR signals, significantly enhancing the performance and reliability of quantitative MRI synthesis. This method shows great potential for accelerating qMRI and improving its clinical utility.
ContrastDiagnosis: Enhancing Interpretability in Lung Nodule Diagnosis Using Contrastive Learning
Mar 08, 2024With the ongoing development of deep learning, an increasing number of AI models have surpassed the performance levels of human clinical practitioners. However, the prevalence of AI diagnostic products in actual clinical practice remains significantly lower than desired. One crucial reason for this gap is the so-called `black box' nature of AI models. Clinicians' distrust of black box models has directly hindered the clinical deployment of AI products. To address this challenge, we propose ContrastDiagnosis, a straightforward yet effective interpretable diagnosis framework. This framework is designed to introduce inherent transparency and provide extensive post-hoc explainability for deep learning model, making them more suitable for clinical medical diagnosis. ContrastDiagnosis incorporates a contrastive learning mechanism to provide a case-based reasoning diagnostic rationale, enhancing the model's transparency and also offers post-hoc interpretability by highlighting similar areas. High diagnostic accuracy was achieved with AUC of 0.977 while maintain a high transparency and explainability.
$\mathrm{SAM^{Med}}$: A medical image annotation framework based on large vision model
Jul 11, 2023



Recently, large vision model, Segment Anything Model (SAM), has revolutionized the computer vision field, especially for image segmentation. SAM presented a new promptable segmentation paradigm that exhibit its remarkable zero-shot generalization ability. An extensive researches have explore the potential and limits of SAM in various downstream tasks. In this study, we presents $\mathrm{SAM^{Med}}$, an enhanced framework for medical image annotation that leverages the capabilities of SAM. $\mathrm{SAM^{Med}}$ framework consisted of two submodules, namely $\mathrm{SAM^{assist}}$ and $\mathrm{SAM^{auto}}$. The $\mathrm{SAM^{assist}}$ demonstrates the generalization ability of SAM to the downstream medical segmentation task using the prompt-learning approach. Results show a significant improvement in segmentation accuracy with only approximately 5 input points. The $\mathrm{SAM^{auto}}$ model aims to accelerate the annotation process by automatically generating input prompts. The proposed SAP-Net model achieves superior segmentation performance with only five annotated slices, achieving an average Dice coefficient of 0.80 and 0.82 for kidney and liver segmentation, respectively. Overall, $\mathrm{SAM^{Med}}$ demonstrates promising results in medical image annotation. These findings highlight the potential of leveraging large-scale vision models in medical image annotation tasks.
Towards Reliable and Explainable AI Model for Solid Pulmonary Nodule Diagnosis
Apr 08, 2022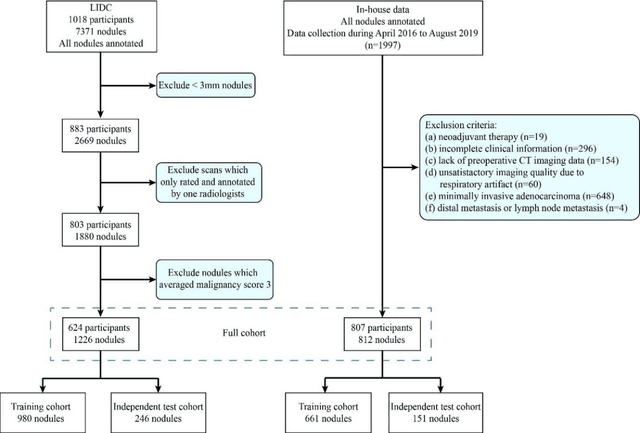
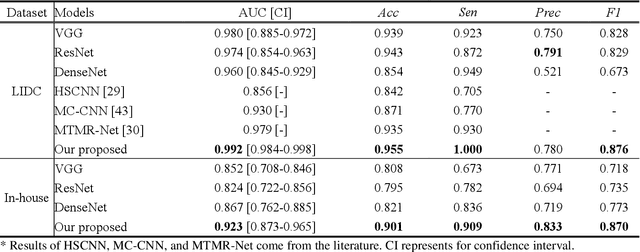
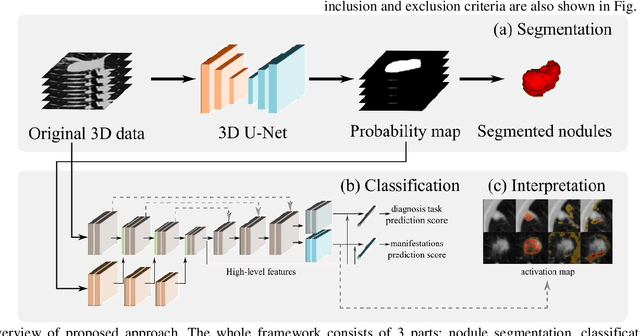
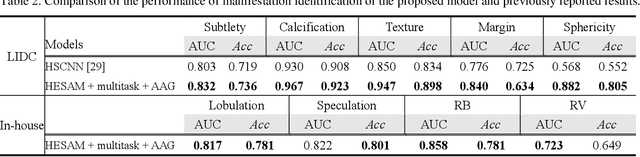
Lung cancer has the highest mortality rate of deadly cancers in the world. Early detection is essential to treatment of lung cancer. However, detection and accurate diagnosis of pulmonary nodules depend heavily on the experiences of radiologists and can be a heavy workload for them. Computer-aided diagnosis (CAD) systems have been developed to assist radiologists in nodule detection and diagnosis, greatly easing the workload while increasing diagnosis accuracy. Recent development of deep learning, greatly improved the performance of CAD systems. However, lack of model reliability and interpretability remains a major obstacle for its large-scale clinical application. In this work, we proposed a multi-task explainable deep-learning model for pulmonary nodule diagnosis. Our neural model can not only predict lesion malignancy but also identify relevant manifestations. Further, the location of each manifestation can also be visualized for visual interpretability. Our proposed neural model achieved a test AUC of 0.992 on LIDC public dataset and a test AUC of 0.923 on our in-house dataset. Moreover, our experimental results proved that by incorporating manifestation identification tasks into the multi-task model, the accuracy of the malignancy classification can also be improved. This multi-task explainable model may provide a scheme for better interaction with the radiologists in a clinical environment.