 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage Training Framework for Joint Speech Compression and Enhancement
Paper and Code

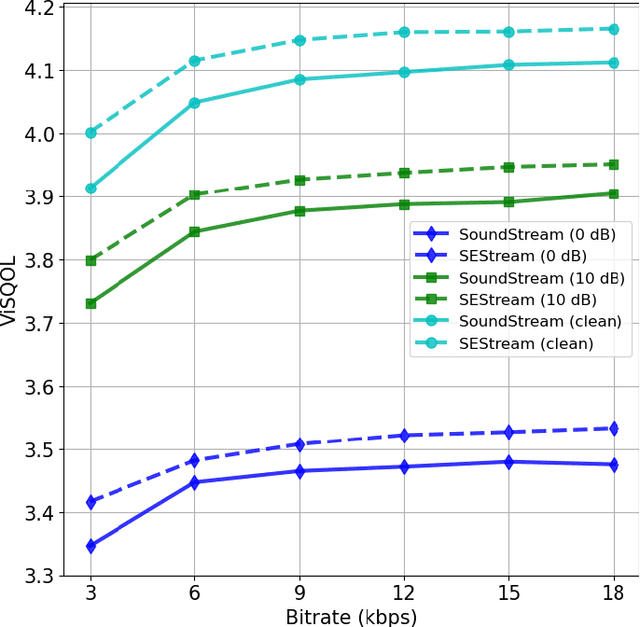
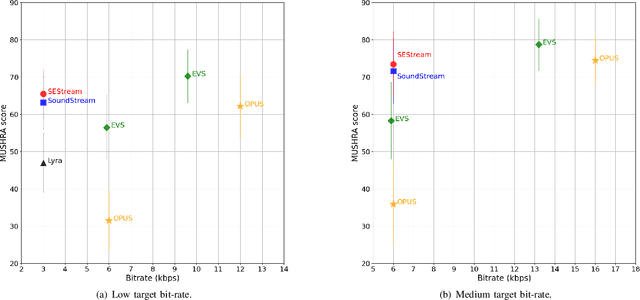
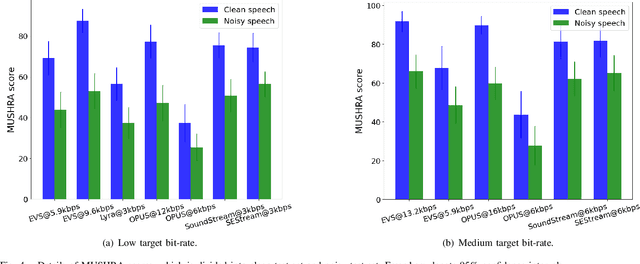
This paper considers the joint compression and enhancement problem for speech signal in the presence of noise. Recently, the SoundStream codec, which relies on end-to-end joint training of an encoder-decoder pair and a residual vector quantizer by a combination of adversarial and reconstruction losses,has shown very promising performance, especially in subjective perception quality. In this work, we provide a theoretical result to show that, to simultaneously achieve low distortion and high perception in the presence of noise, there exist an optimal two-stage optimization procedure for the joint compression and enhancement problem. This procedure firstly optimizes an encoder-decoder pair using only distortion loss and then fixes the encoder to optimize a perceptual decoder using perception loss. Based on this result, we construct a two-stage training framework for joint compression and enhancement of noisy speech signal. Unlike existing training methods which are heuristic, the proposed two-stage training method has a theoretical foundation. Finally, experimental results for various noise and bit-rate conditions are provided. The results demonstrate that a codec trained by the proposed framework can outperform SoundStream and other representative codecs in terms of both objective and subjective evaluation metrics. Code is available at \textit{https://github.com/jscscloris/SEStream}.