 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Geometric Domain Shifts in Semantic Segmentation of Surgical RGB and Hyperspectral Images
Aug 27, 2024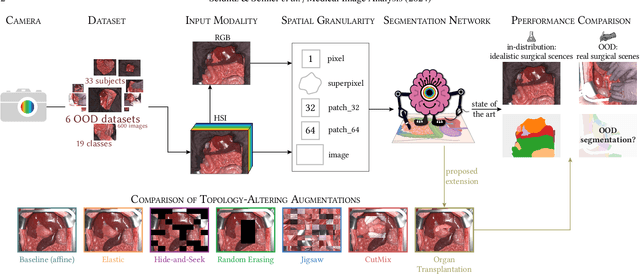
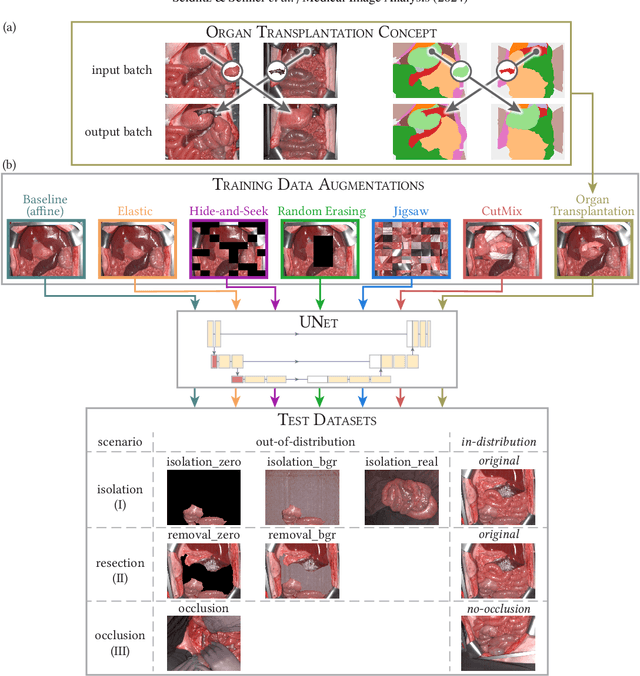
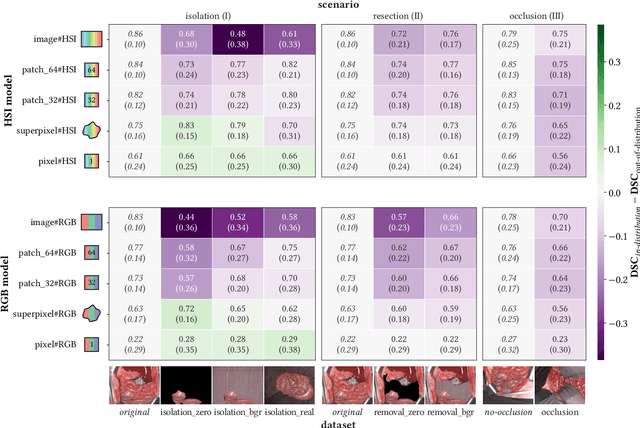
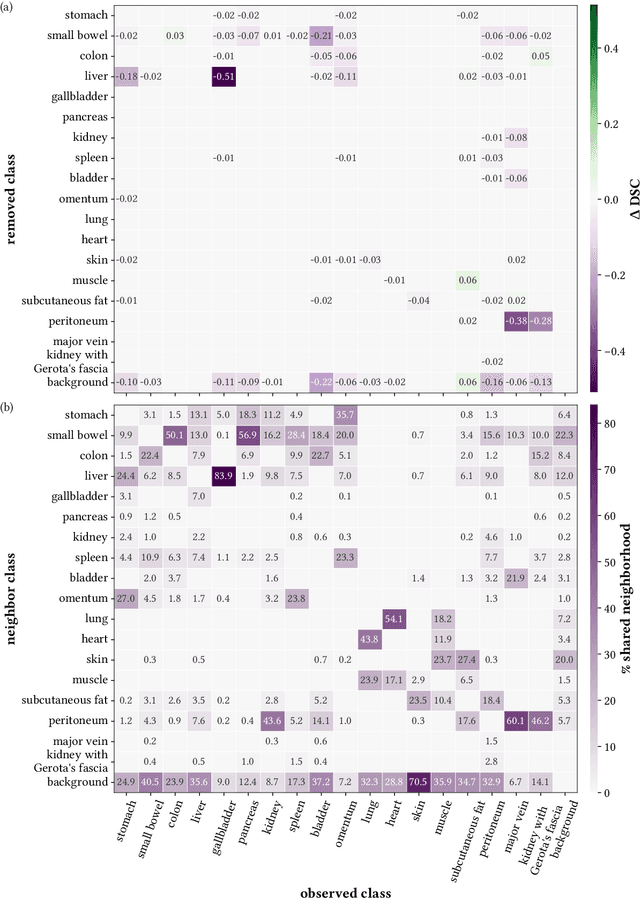
Robust semantic segmentation of intraoperative image data holds promise for enabling automatic surgical scene understanding and autonomous robotic surgery. While model development and validation are primarily conducted on idealistic scenes, geometric domain shifts, such as occlusions of the situs, are common in real-world open surgeries. To close this gap, we (1) present the first analysis of state-of-the-art (SOA) semantic segmentation models when faced with geometric out-of-distribution (OOD) data, and (2) propose an augmentation technique called "Organ Transplantation", to enhance generalizability. Our comprehensive validation on six different OOD datasets, comprising 600 RGB and hyperspectral imaging (HSI) cubes from 33 pigs, each annotated with 19 classes, reveals a large performance drop in SOA organ segmentation models on geometric OOD data. This performance decline is observed not only in conventional RGB data (with a dice similarity coefficient (DSC) drop of 46 %) but also in HSI data (with a DSC drop of 45 %), despite the richer spectral information content. The performance decline increases with the spatial granularity of the input data. Our augmentation technique improves SOA model performance by up to 67 % for RGB data and 90 % for HSI data, achieving performance at the level of in-distribution performance on real OOD test data. Given the simplicity and effectiveness of our augmentation method, it is a valuable tool for addressing geometric domain shifts in surgical scene segmentation, regardless of the underlying model. Our code and pre-trained models are publicly available at https://github.com/IMSY-DKFZ/htc.
Robust deep learning-based semantic organ segmentation in hyperspectral images
Nov 09, 2021Semantic image segmentation is an important prerequisite for context-awareness and autonomous robotics in surgery. The state of the art has focused on conventional RGB video data acquired during minimally invasive surgery, but full-scene semantic segmentation based on spectral imaging data and obtained during open surgery has received almost no attention to date. To address this gap in the literature, we are investigating the following research questions based on hyperspectral imaging (HSI) data of pigs acquired in an open surgery setting: (1) What is an adequate representation of HSI data for neural network-based fully automated organ segmentation, especially with respect to the spatial granularity of the data (pixels vs. superpixels vs. patches vs. full images)? (2) Is there a benefit of using HSI data compared to other modalities, namely RGB data and processed HSI data (e.g. tissue parameters like oxygenation), when performing semantic organ segmentation? According to a comprehensive validation study based on 506 HSI images from 20 pigs, annotated with a total of 19 classes, deep learning-based segmentation performance increases - consistently across modalities - with the spatial context of the input data. Unprocessed HSI data offers an advantage over RGB data or processed data from the camera provider, with the advantage increasing with decreasing size of the input to the neural network. Maximum performance (HSI applied to whole images) yielded a mean dice similarity coefficient (DSC) of 0.89 (standard deviation (SD) 0.04), which is in the range of the inter-rater variability (DSC of 0.89 (SD 0.07)). We conclude that HSI could become a powerful image modality for fully-automatic surgical scene understanding with many advantages over traditional imaging, including the ability to recover additional functional tissue information.
Cooperative Assistance in Robotic Surgery through Multi-Agent Reinforcement Learning
Oct 10, 2021

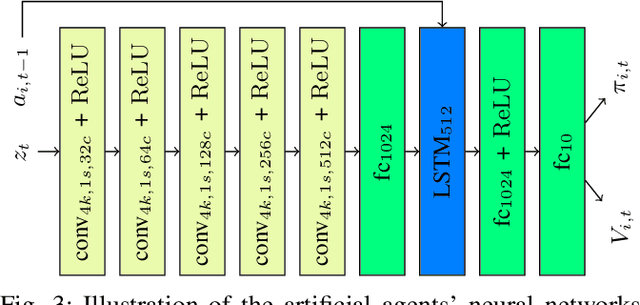
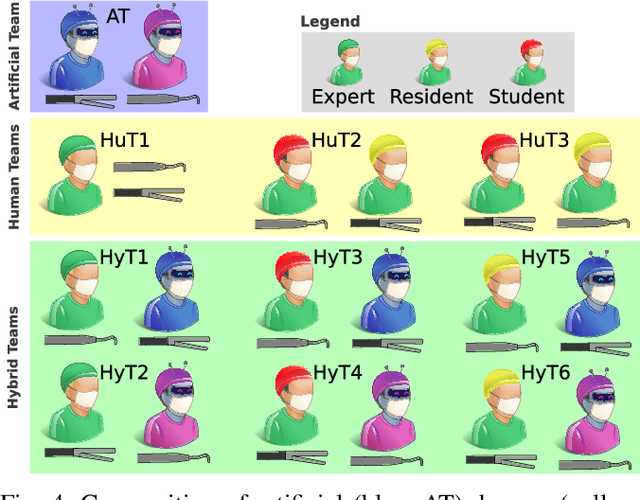
Cognitive cooperative assistance in robot-assisted surgery holds the potential to increase quality of care in minimally invasive interventions. Automation of surgical tasks promises to reduce the mental exertion and fatigue of surgeons. In this work, multi-agent reinforcement learning is demonstrated to be robust to the distribution shift introduced by pairing a learned policy with a human team member. Multi-agent policies are trained directly from images in simulation to control multiple instruments in a sub task of the minimally invasive removal of the gallbladder. These agents are evaluated individually and in cooperation with humans to demonstrate their suitability as autonomous assistants. Compared to human teams, the hybrid teams with artificial agents perform better considering completion time (44.4% to 71.2% shorter) as well as number of collisions (44.7% to 98.0% fewer). Path lengths, however, increase under control of an artificial agent (11.4% to 33.5% longer). A multi-agent formulation of the learning problem was favored over a single-agent formulation on this surgical sub task, due to the sequential learning of the two instruments. This approach may be extended to other tasks that are difficult to formulate within the standard reinforcement learning framework. Multi-agent reinforcement learning may shift the paradigm of cognitive robotic surgery towards seamless cooperation between surgeons and assistive technologies.
How can we learn from challenges? A statistical approach to driving future algorithm development
Jun 17, 2021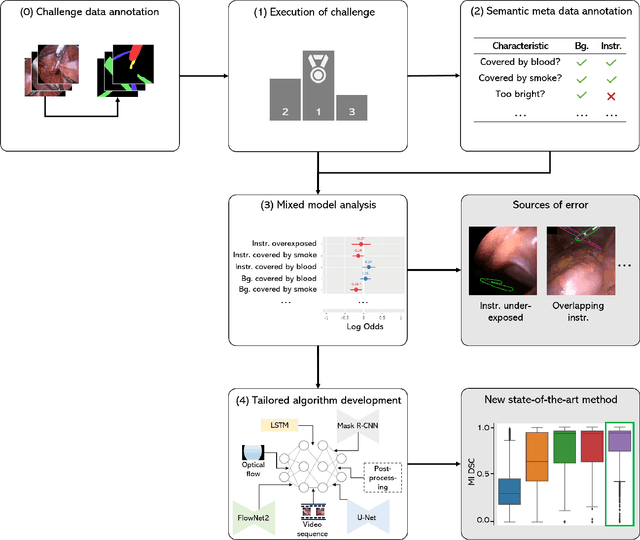


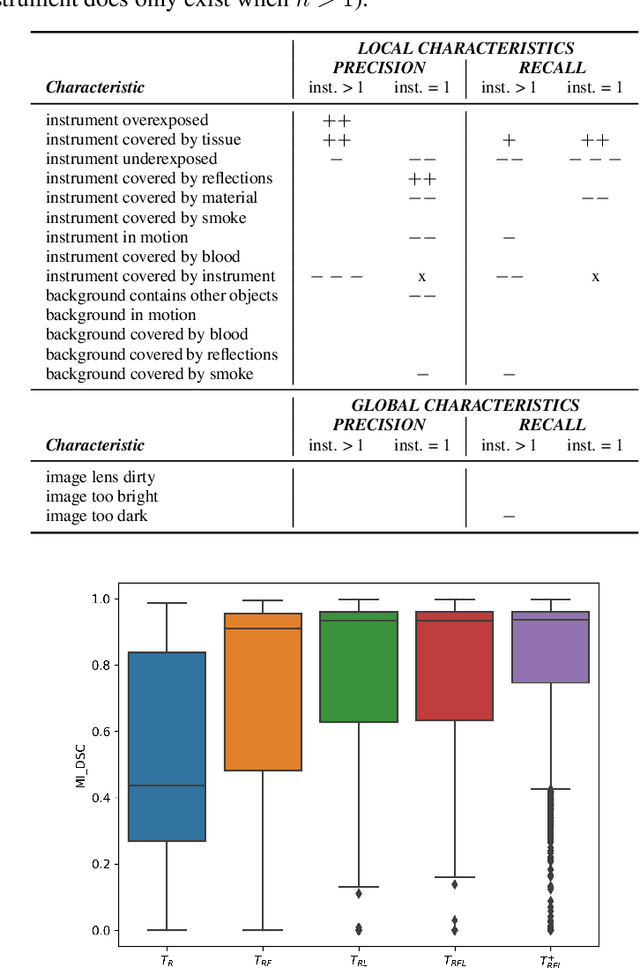
Challenges have become the state-of-the-art approach to benchmark image analysis algorithms in a comparative manner. While the validation on identical data sets was a great step forward, results analysis is often restricted to pure ranking tables, leaving relevant questions unanswered. Specifically, little effort has been put into the systematic investigation on what characterizes images in which state-of-the-art algorithms fail. To address this gap in the literature, we (1) present a statistical framework for learning from challenges and (2) instantiate it for the specific task of instrument instance segmentation in laparoscopic videos. Our framework relies on the semantic meta data annotation of images, which serves as foundation for a General Linear Mixed Models (GLMM) analysis. Based on 51,542 meta data annotations performed on 2,728 images, we applied our approach to the results of the Robust Medical Instrument Segmentation Challenge (ROBUST-MIS) challenge 2019 and revealed underexposure, motion and occlusion of instruments as well as the presence of smoke or other objects in the background as major sources of algorithm failure. Our subsequent method development, tailored to the specific remaining issues, yielded a deep learning model with state-of-the-art overall performance and specific strengths in the processing of images in which previous methods tended to fail. Due to the objectivity and generic applicability of our approach, it could become a valuable tool for validation in the field of medical image analysis and beyond. and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Machine learning-based analysis of hyperspectral images for automated sepsis diagnosis
Jun 15, 2021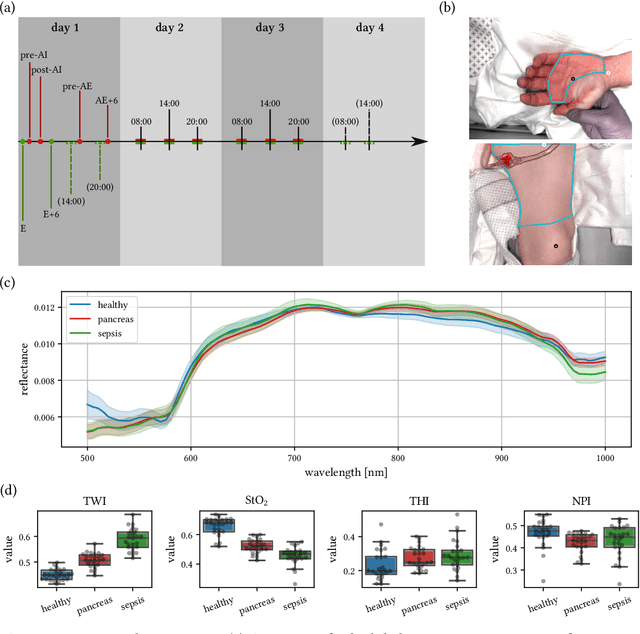
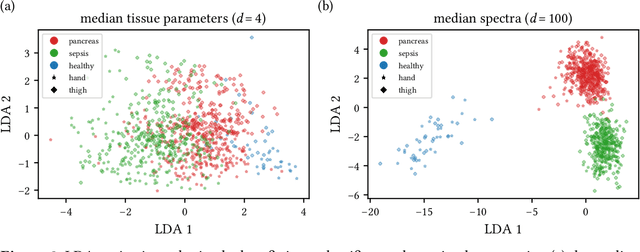
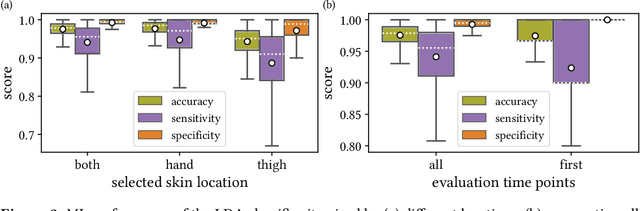
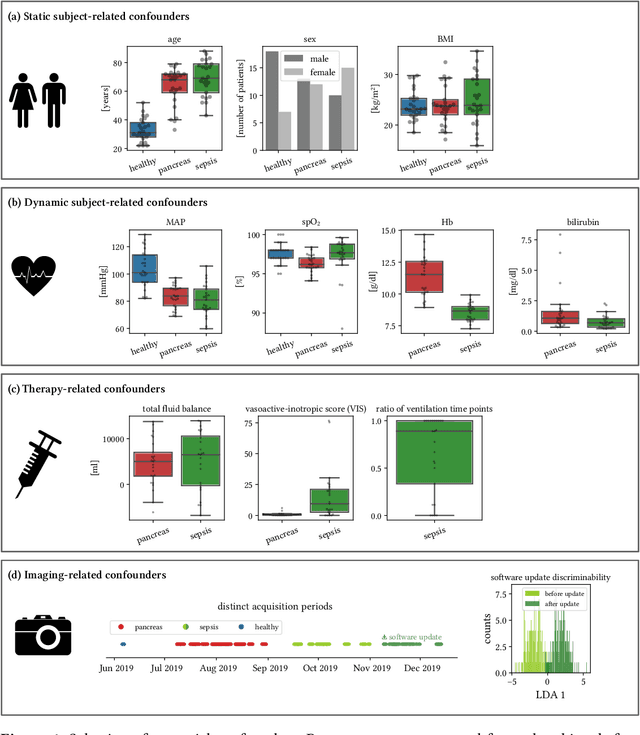
Sepsis is a leading cause of mortality and critical illness worldwide. While robust biomarkers for early diagnosis are still missing, recent work indicates that hyperspectral imaging (HSI) has the potential to overcome this bottleneck by monitoring microcirculatory alterations. Automated machine learning-based diagnosis of sepsis based on HSI data, however, has not been explored to date. Given this gap in the literature, we leveraged an existing data set to (1) investigate whether HSI-based automated diagnosis of sepsis is possible and (2) put forth a list of possible confounders relevant for HSI-based tissue classification. While we were able to classify sepsis with an accuracy of over $98\,\%$ using the existing data, our research also revealed several subject-, therapy- and imaging-related confounders that may lead to an overestimation of algorithm performance when not balanced across the patient groups. We conclude that further prospective studies, carefully designed with respect to these confounders, are necessary to confirm the preliminary results obtained in this study.
Tattoo tomography: Freehand 3D photoacoustic image reconstruction with an optical pattern
Nov 11, 2020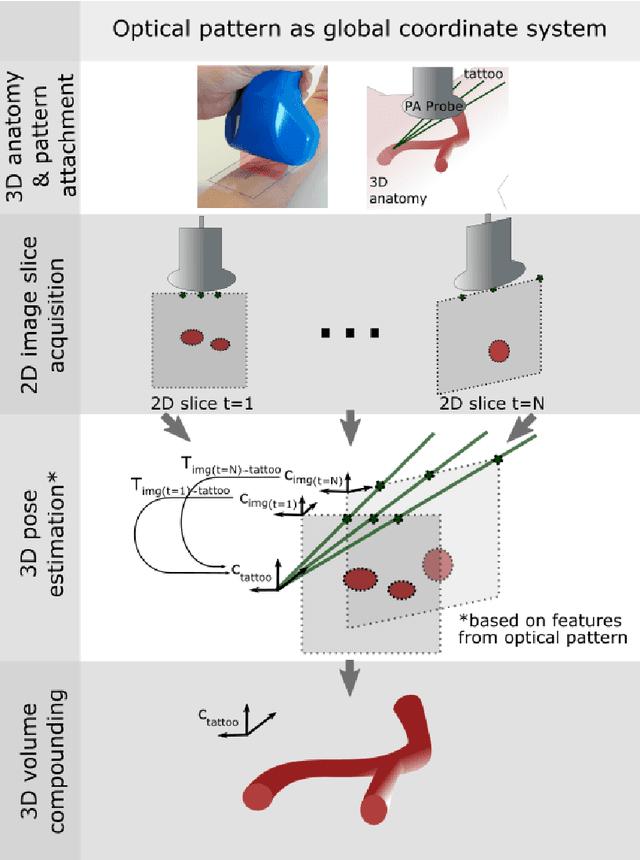
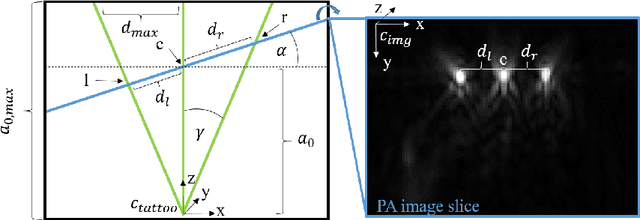


Purpose: Photoacoustic tomography (PAT) is a novel imaging technique that can spatially resolve both morphological and functional tissue properties, such as the vessel topology and tissue oxygenation. While this capacity makes PAT a promising modality for the diagnosis, treatment and follow-up of various diseases, a current drawback is the limited field-of-view (FoV) provided by the conventionally applied 2D probes. Methods: In this paper, we present a novel approach to 3D reconstruction of PAT data (Tattoo tomography) that does not require an external tracking system and can smoothly be integrated into clinical workflows. It is based on an optical pattern placed on the region of interest prior to image acquisition. This pattern is designed in a way that a tomographic image of it enables the recovery of the probe pose relative to the coordinate system of the pattern. This allows the transformation of a sequence of acquired PA images into one common global coordinate system and thus the consistent 3D reconstruction of PAT imaging data. Results: An initial feasibility study conducted with experimental phantom data and in vivo forearm data indicates that the Tattoo approach is well-suited for 3D reconstruction of PAT data with high accuracy and precision. Conclusion: In contrast to previous approaches to 3D ultrasound (US) or PAT reconstruction, the Tattoo approach neither requires complex external hardware nor training data acquired for a specific application. It could thus become a valuable tool for clinical freehand PAT.
Heidelberg Colorectal Data Set for Surgical Data Science in the Sensor Operating Room
May 28, 2020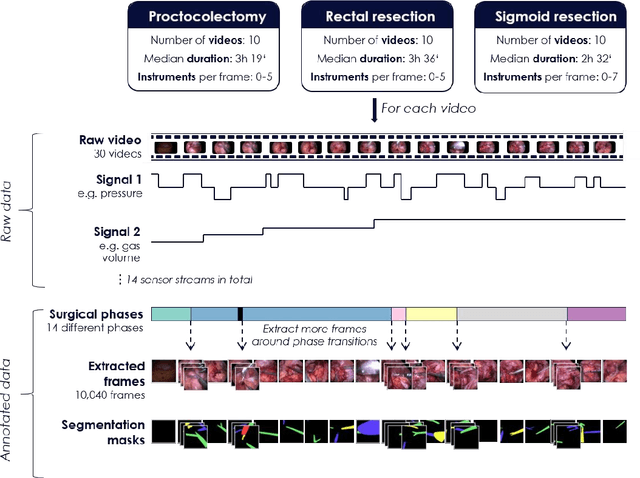
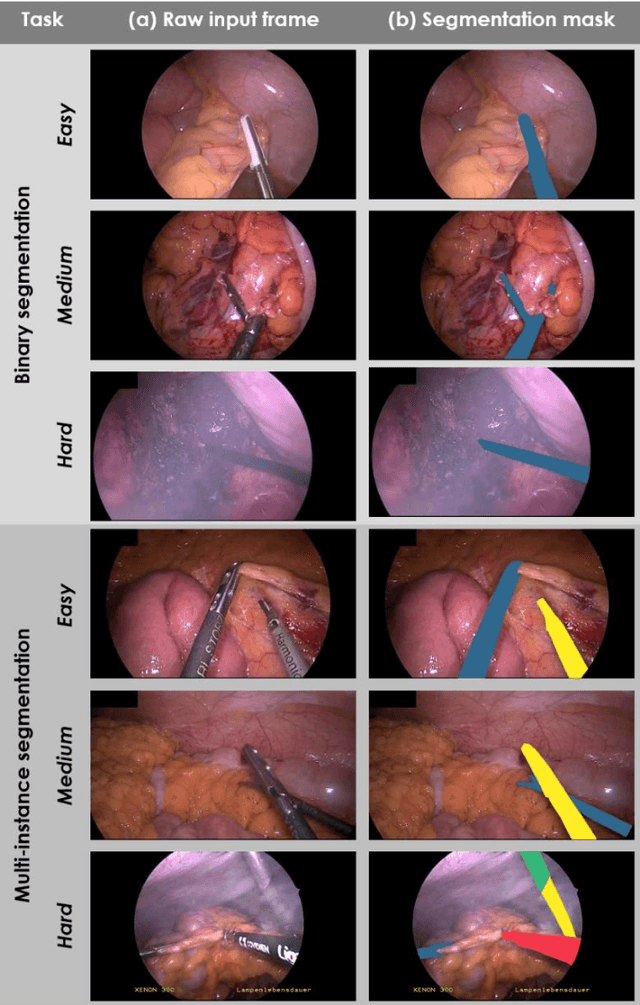
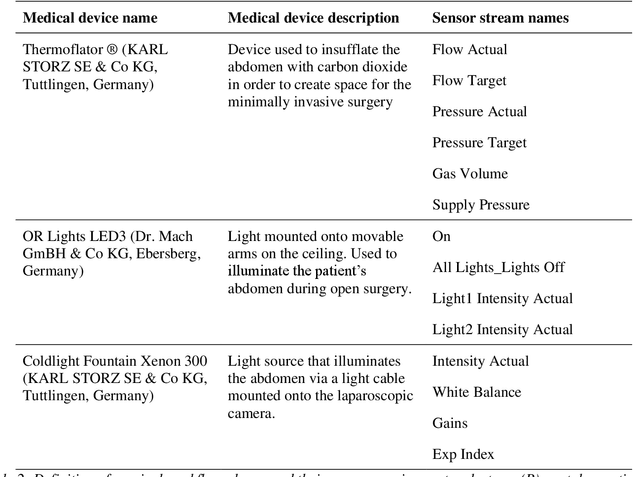
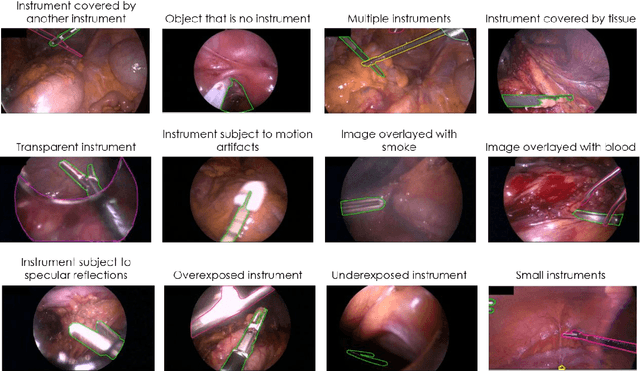
Image-based tracking of medical instruments is an integral part of many surgical data science applications. Previous research has addressed the tasks of detecting, segmenting and tracking medical instruments based on laparoscopic video data. However, the methods proposed still tend to fail when applied to challenging images and do not generalize well to data they have not been trained on. This paper introduces the Heidelberg Colorectal (HeiCo) data set - the first publicly available data set enabling comprehensive benchmarking of medical instrument detection and segmentation algorithms with a specific emphasis on robustness and generalization capabilities of the methods. Our data set comprises 30 laparoscopic videos and corresponding sensor data from medical devices in the operating room for three different types of laparoscopic surgery. Annotations include surgical phase labels for all frames in the videos as well as instance-wise segmentation masks for surgical instruments in more than 10,000 individual frames. The data has successfully been used to organize international competitions in the scope of the Endoscopic Vision Challenges (EndoVis) 2017 and 2019.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020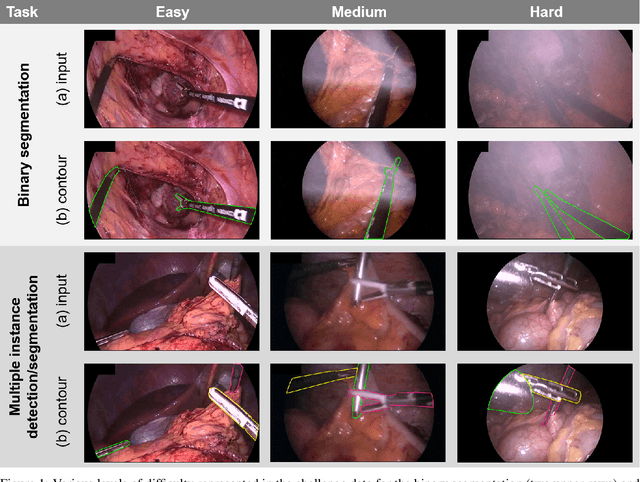
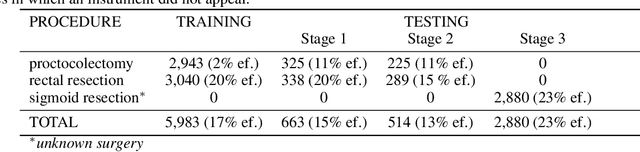
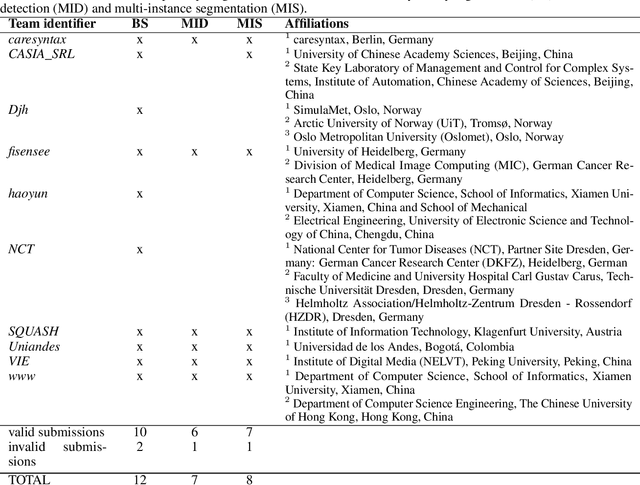
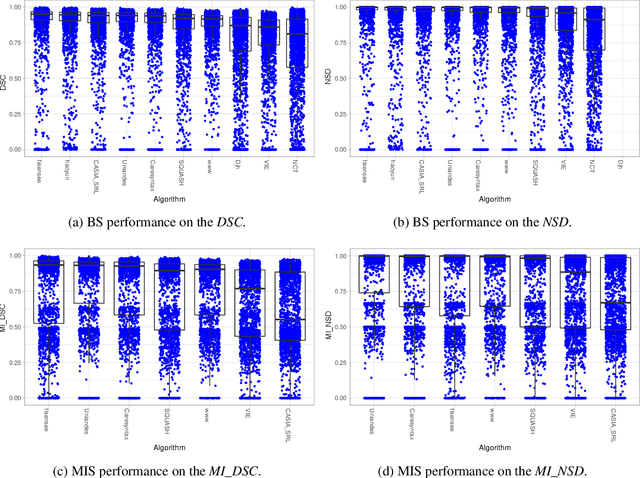
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Out of distribution detection for intra-operative functional imaging
Nov 05, 2019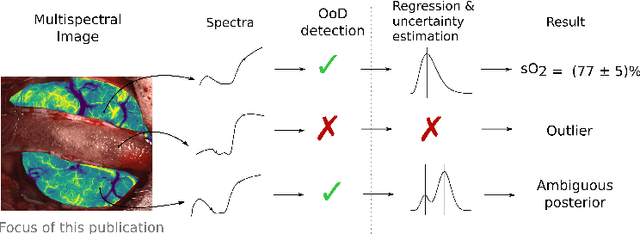
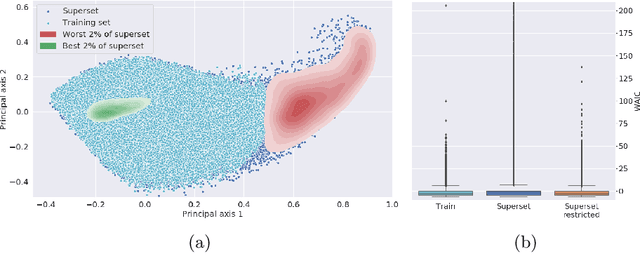
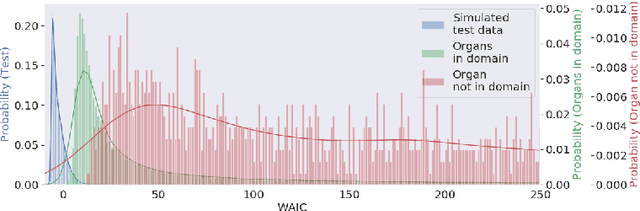
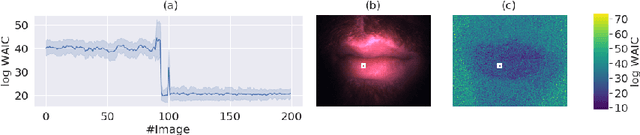
Multispectral optical imaging is becoming a key tool in the operating room. Recent research has shown that machine learning algorithms can be used to convert pixel-wise reflectance measurements to tissue parameters, such as oxygenation. However, the accuracy of these algorithms can only be guaranteed if the spectra acquired during surgery match the ones seen during training. It is therefore of great interest to detect so-called out of distribution (OoD) spectra to prevent the algorithm from presenting spurious results. In this paper we present an information theory based approach to OoD detection based on the widely applicable information criterion (WAIC). Our work builds upon recent methodology related to invertible neural networks (INN). Specifically, we make use of an ensemble of INNs as we need their tractable Jacobians in order to compute the WAIC. Comprehensive experiments with in silico, and in vivo multispectral imaging data indicate that our approach is well-suited for OoD detection. Our method could thus be an important step towards reliable functional imaging in the operating room.
* The final authenticated version is available online at https://doi.org/10.1007/978-3-030-32689-0_8