 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-distillation for surgical action recognition
Mar 22, 2023



Surgical scene understanding is a key prerequisite for contextaware decision support in the operating room. While deep learning-based approaches have already reached or even surpassed human performance in various fields, the task of surgical action recognition remains a major challenge. With this contribution, we are the first to investigate the concept of self-distillation as a means of addressing class imbalance and potential label ambiguity in surgical video analysis. Our proposed method is a heterogeneous ensemble of three models that use Swin Transfomers as backbone and the concepts of self-distillation and multi-task learning as core design choices. According to ablation studies performed with the CholecT45 challenge data via cross-validation, the biggest performance boost is achieved by the usage of soft labels obtained by self-distillation. External validation of our method on an independent test set was achieved by providing a Docker container of our inference model to the challenge organizers. According to their analysis, our method outperforms all other solutions submitted to the latest challenge in the field. Our approach thus shows the potential of self-distillation for becoming an important tool in medical image analysis applications.
Unsupervised Domain Transfer with Conditional Invertible Neural Networks
Mar 17, 2023Synthetic medical image generation has evolved as a key technique for neural network training and validation. A core challenge, however, remains in the domain gap between simulations and real data. While deep learning-based domain transfer using Cycle Generative Adversarial Networks and similar architectures has led to substantial progress in the field, there are use cases in which state-of-the-art approaches still fail to generate training images that produce convincing results on relevant downstream tasks. Here, we address this issue with a domain transfer approach based on conditional invertible neural networks (cINNs). As a particular advantage, our method inherently guarantees cycle consistency through its invertible architecture, and network training can efficiently be conducted with maximum likelihood training. To showcase our method's generic applicability, we apply it to two spectral imaging modalities at different scales, namely hyperspectral imaging (pixel-level) and photoacoustic tomography (image-level). According to comprehensive experiments, our method enables the generation of realistic spectral data and outperforms the state of the art on two downstream classification tasks (binary and multi-class). cINN-based domain transfer could thus evolve as an important method for realistic synthetic data generation in the field of spectral imaging and beyond.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023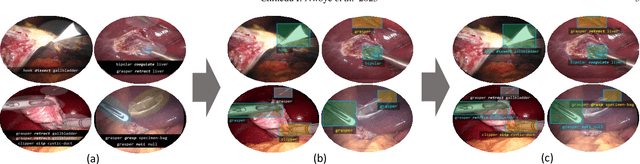
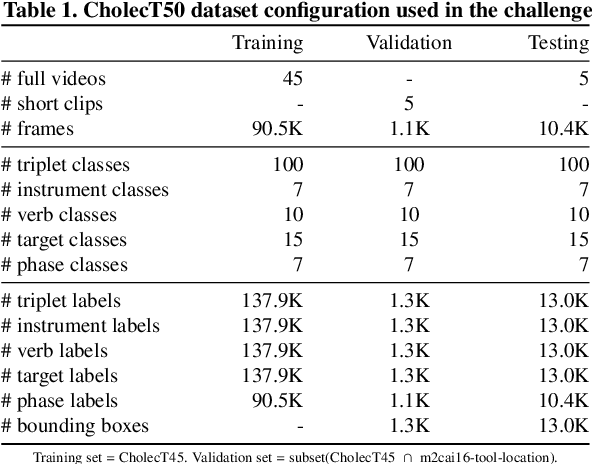
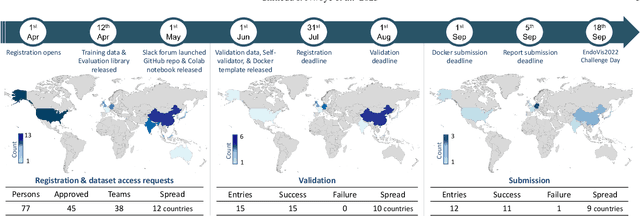
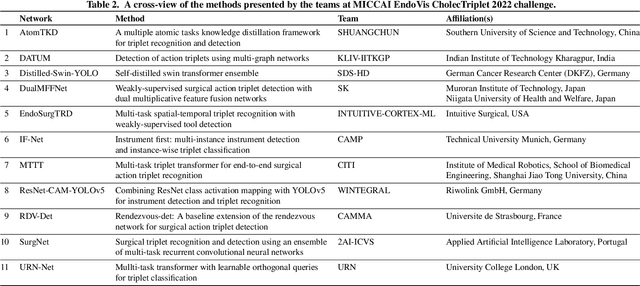
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
Semantic segmentation of multispectral photoacoustic images using deep learning
May 20, 2021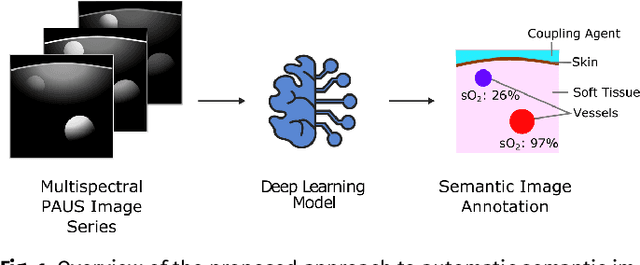

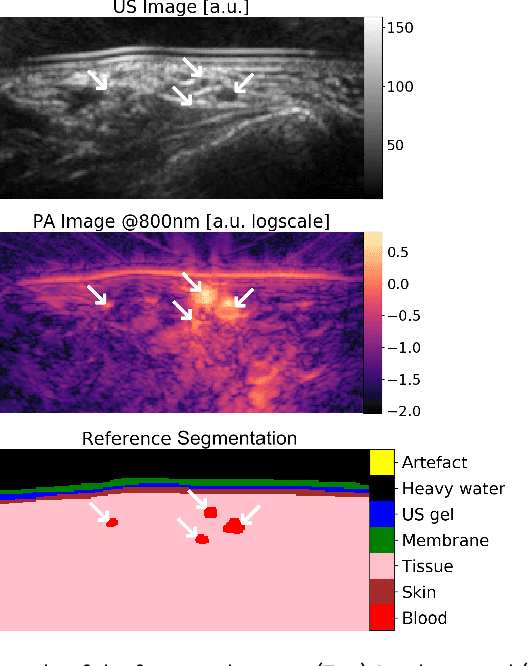
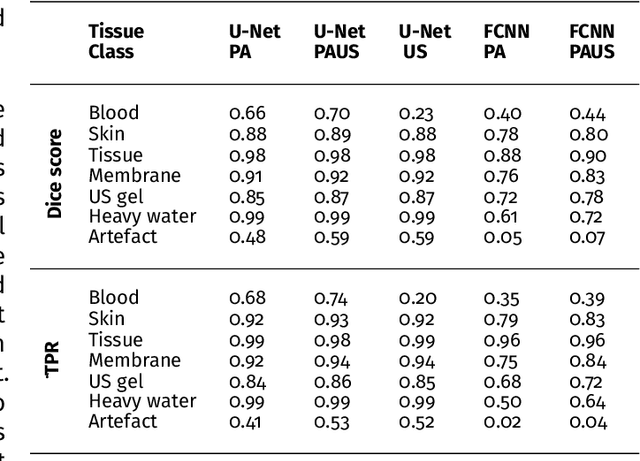
Photoacoustic imaging has the potential to revolutionise healthcare due to the valuable information on tissue physiology that is contained in multispectral photoacoustic measurements. Clinical translation of the technology requires conversion of the high-dimensional acquired data into clinically relevant and interpretable information. In this work, we present a deep learning-based approach to semantic segmentation of multispectral photoacoustic images to facilitate the interpretability of recorded images. Manually annotated multispectral photoacoustic imaging data are used as gold standard reference annotations and enable the training of a deep learning-based segmentation algorithm in a supervised manner. Based on a validation study with experimentally acquired data of healthy human volunteers, we show that automatic tissue segmentation can be used to create powerful analyses and visualisations of multispectral photoacoustic images. Due to the intuitive representation of high-dimensional information, such a processing algorithm could be a valuable means to facilitate the clinical translation of photoacoustic imaging.
Data-driven generation of plausible tissue geometries for realistic photoacoustic image synthesis
Mar 29, 2021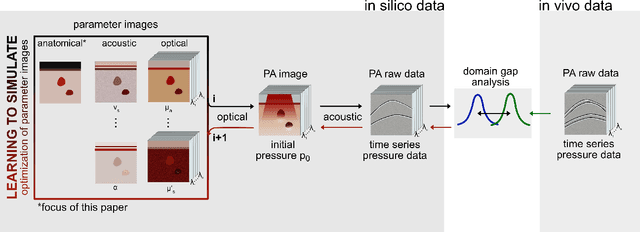
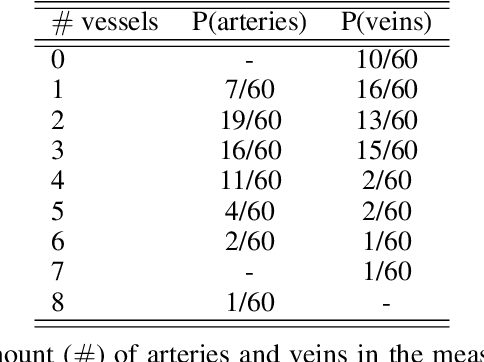
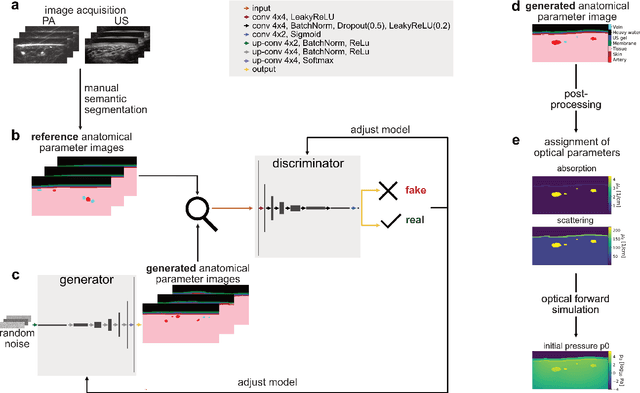

Photoacoustic tomography (PAT) has the potential to recover morphological and functional tissue properties such as blood oxygenation with high spatial resolution and in an interventional setting. However, decades of research invested in solving the inverse problem of recovering clinically relevant tissue properties from spectral measurements have failed to produce solutions that can quantify tissue parameters robustly in a clinical setting. Previous attempts to address the limitations of model-based approaches with machine learning were hampered by the absence of labeled reference data needed for supervised algorithm training. While this bottleneck has been tackled by simulating training data, the domain gap between real and simulated images remains a huge unsolved challenge. As a first step to address this bottleneck, we propose a novel approach to PAT data simulation, which we refer to as "learning to simulate". Our approach involves subdividing the challenge of generating plausible simulations into two disjoint problems: (1) Probabilistic generation of realistic tissue morphology, represented by semantic segmentation maps and (2) pixel-wise assignment of corresponding optical and acoustic properties. In the present work, we focus on the first challenge. Specifically, we leverage the concept of Generative Adversarial Networks (GANs) trained on semantically annotated medical imaging data to generate plausible tissue geometries. According to an initial in silico feasibility study our approach is well-suited for contributing to realistic PAT image synthesis and could thus become a fundamental step for deep learning-based quantitative PAT.
Tattoo tomography: Freehand 3D photoacoustic image reconstruction with an optical pattern
Nov 11, 2020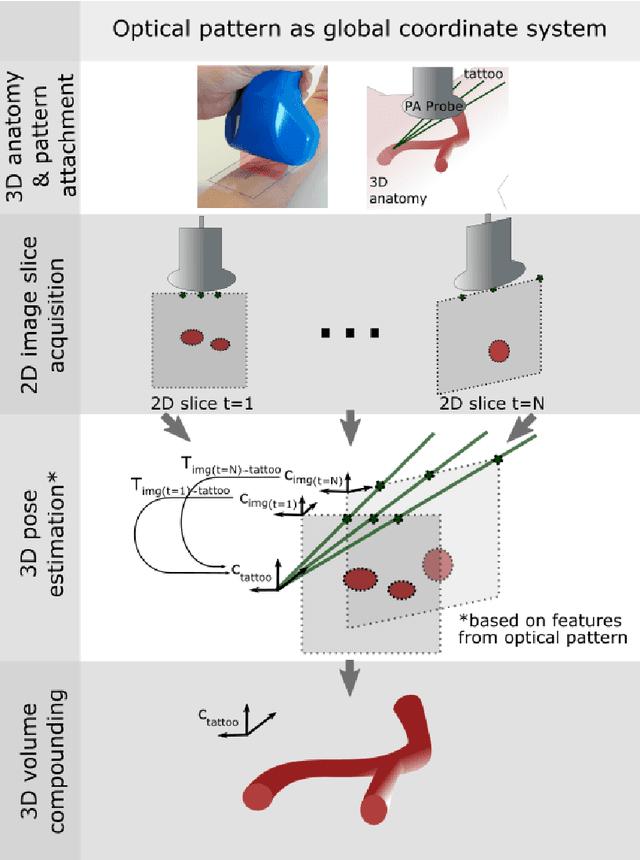
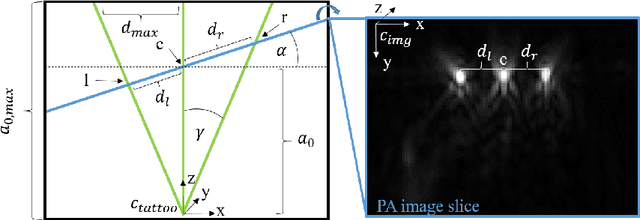


Purpose: Photoacoustic tomography (PAT) is a novel imaging technique that can spatially resolve both morphological and functional tissue properties, such as the vessel topology and tissue oxygenation. While this capacity makes PAT a promising modality for the diagnosis, treatment and follow-up of various diseases, a current drawback is the limited field-of-view (FoV) provided by the conventionally applied 2D probes. Methods: In this paper, we present a novel approach to 3D reconstruction of PAT data (Tattoo tomography) that does not require an external tracking system and can smoothly be integrated into clinical workflows. It is based on an optical pattern placed on the region of interest prior to image acquisition. This pattern is designed in a way that a tomographic image of it enables the recovery of the probe pose relative to the coordinate system of the pattern. This allows the transformation of a sequence of acquired PA images into one common global coordinate system and thus the consistent 3D reconstruction of PAT imaging data. Results: An initial feasibility study conducted with experimental phantom data and in vivo forearm data indicates that the Tattoo approach is well-suited for 3D reconstruction of PAT data with high accuracy and precision. Conclusion: In contrast to previous approaches to 3D ultrasound (US) or PAT reconstruction, the Tattoo approach neither requires complex external hardware nor training data acquired for a specific application. It could thus become a valuable tool for clinical freehand PAT.
Deep learning for biomedical photoacoustic imaging: A review
Nov 05, 2020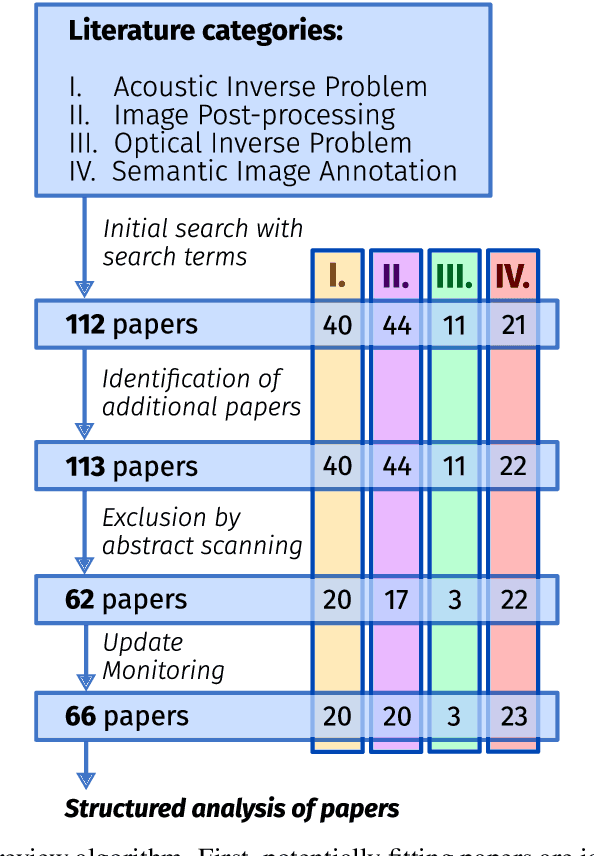
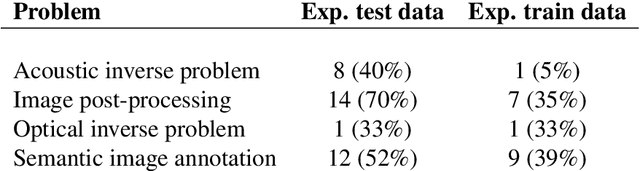
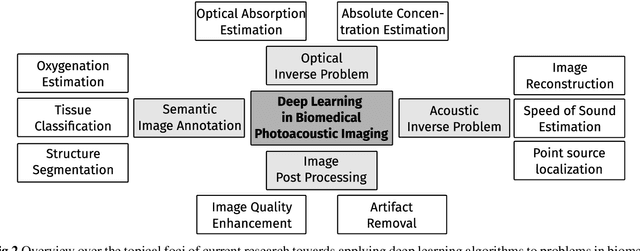

Photoacoustic imaging (PAI) is a promising emerging imaging modality that enables spatially resolved imaging of optical tissue properties up to several centimeters deep in tissue, creating the potential for numerous exciting clinical applications. However, extraction of relevant tissue parameters from the raw data requires the solving of inverse image reconstruction problems, which have proven extremely difficult to solve. The application of deep learning methods has recently exploded in popularity, leading to impressive successes in the context of medical imaging and also finding first use in the field of PAI. Deep learning methods possess unique advantages that can facilitate the clinical translation of PAI, such as extremely fast computation times and the fact that they can be adapted to any given problem. In this review, we examine the current state of the art regarding deep learning in PAI and identify potential directions of research that will help to reach the goal of clinical applicability
Heidelberg Colorectal Data Set for Surgical Data Science in the Sensor Operating Room
May 28, 2020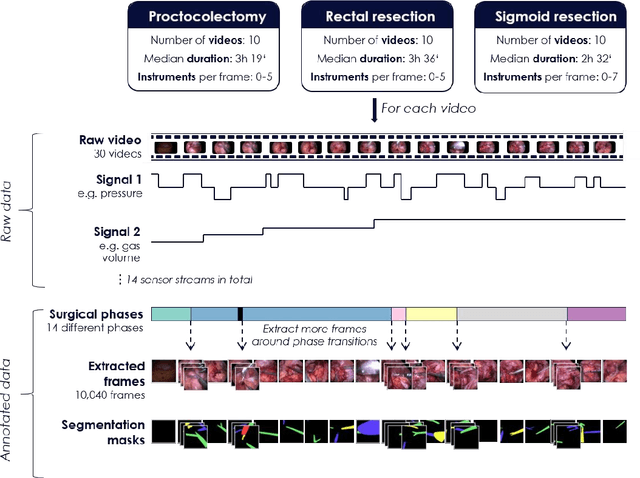
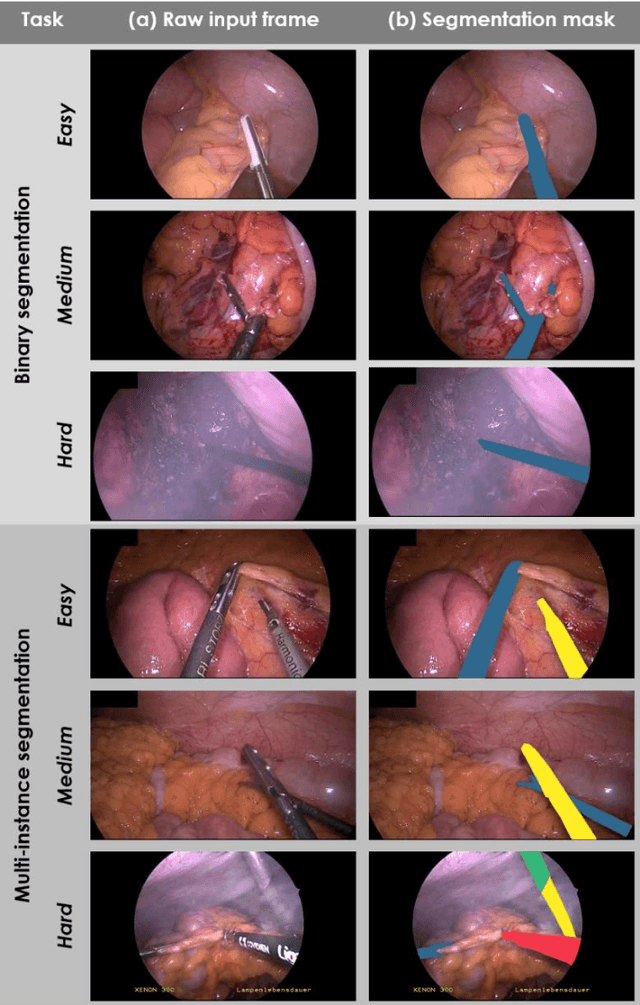
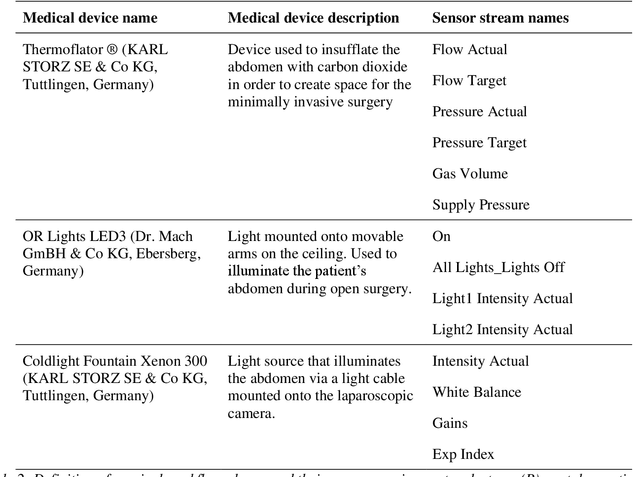
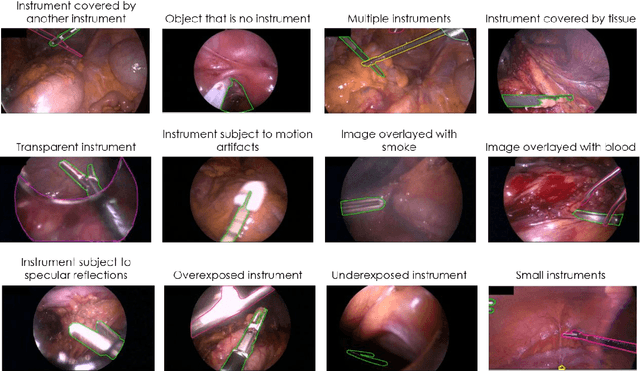
Image-based tracking of medical instruments is an integral part of many surgical data science applications. Previous research has addressed the tasks of detecting, segmenting and tracking medical instruments based on laparoscopic video data. However, the methods proposed still tend to fail when applied to challenging images and do not generalize well to data they have not been trained on. This paper introduces the Heidelberg Colorectal (HeiCo) data set - the first publicly available data set enabling comprehensive benchmarking of medical instrument detection and segmentation algorithms with a specific emphasis on robustness and generalization capabilities of the methods. Our data set comprises 30 laparoscopic videos and corresponding sensor data from medical devices in the operating room for three different types of laparoscopic surgery. Annotations include surgical phase labels for all frames in the videos as well as instance-wise segmentation masks for surgical instruments in more than 10,000 individual frames. The data has successfully been used to organize international competitions in the scope of the Endoscopic Vision Challenges (EndoVis) 2017 and 2019.