 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching
Jul 23, 2020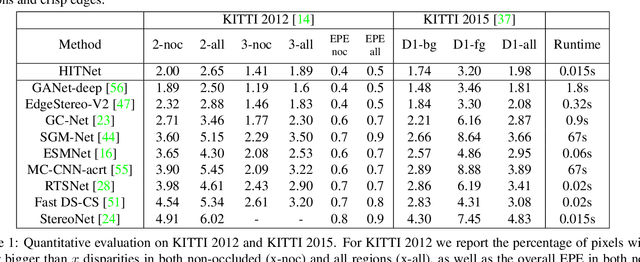
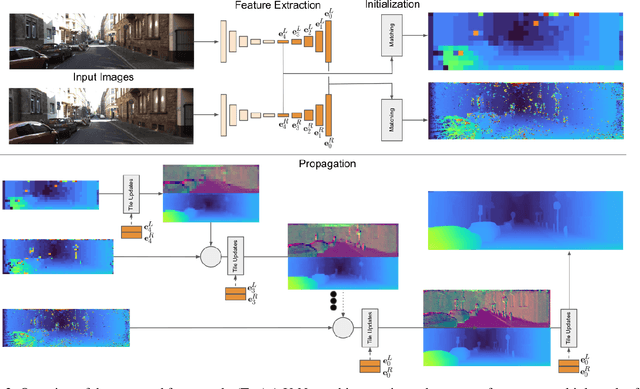


This paper presents HITNet, a novel neural network architecture for real-time stereo matching. Contrary to many recent neural network approaches that operate on a full cost volume and rely on 3D convolutions, our approach does not explicitly build a volume and instead relies on a fast multi-resolution initialization step, differentiable 2D geometric propagation and warping mechanisms to infer disparity hypotheses. To achieve a high level of accuracy, our network not only geometrically reasons about disparities but also infers slanted plane hypotheses allowing to more accurately perform geometric warping and upsampling operations. Our architecture is inherently multi-resolution allowing the propagation of information at different levels. Multiple experiments prove the effectiveness of the proposed approach at a fraction of the computation required by recent state-of-the-art methods. At time of writing, HITNet ranks 1st-3rd on all the metrics published on the ETH3D website for two view stereo and ranks 1st on the popular KITTI 2012 and 2015 benchmarks among the published methods faster than 100ms.
Deep Implicit Volume Compression
May 18, 2020

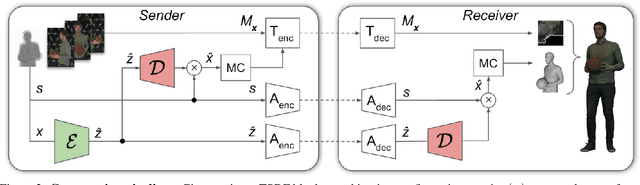
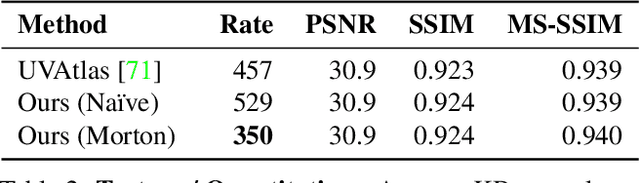
We describe a novel approach for compressing truncated signed distance fields (TSDF) stored in 3D voxel grids, and their corresponding textures. To compress the TSDF, our method relies on a block-based neural network architecture trained end-to-end, achieving state-of-the-art rate-distortion trade-off. To prevent topological errors, we losslessly compress the signs of the TSDF, which also upper bounds the reconstruction error by the voxel size. To compress the corresponding texture, we designed a fast block-based UV parameterization, generating coherent texture maps that can be effectively compressed using existing video compression algorithms. We demonstrate the performance of our algorithms on two 4D performance capture datasets, reducing bitrate by 66% for the same distortion, or alternatively reducing the distortion by 50% for the same bitrate, compared to the state-of-the-art.
RePose: Learning Deep Kinematic Priors for Fast Human Pose Estimation
Feb 10, 2020
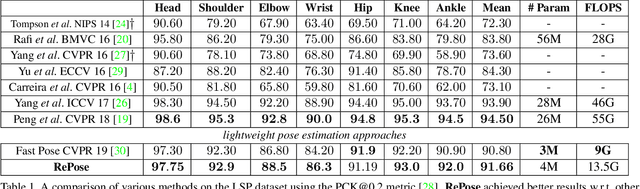
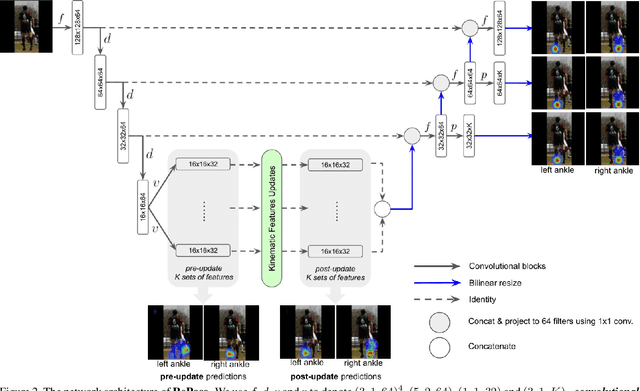
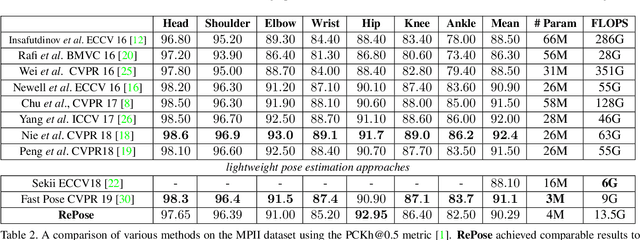
We propose a novel efficient and lightweight model for human pose estimation from a single image. Our model is designed to achieve competitive results at a fraction of the number of parameters and computational cost of various state-of-the-art methods. To this end, we explicitly incorporate part-based structural and geometric priors in a hierarchical prediction framework. At the coarsest resolution, and in a manner similar to classical part-based approaches, we leverage the kinematic structure of the human body to propagate convolutional feature updates between the keypoints or body parts. Unlike classical approaches, we adopt end-to-end training to learn this geometric prior through feature updates from data. We then propagate the feature representation at the coarsest resolution up the hierarchy to refine the predicted pose in a coarse-to-fine fashion. The final network effectively models the geometric prior and intuition within a lightweight deep neural network, yielding state-of-the-art results for a model of this size on two standard datasets, Leeds Sports Pose and MPII Human Pose.
Volumetric Capture of Humans with a Single RGBD Camera via Semi-Parametric Learning
May 29, 2019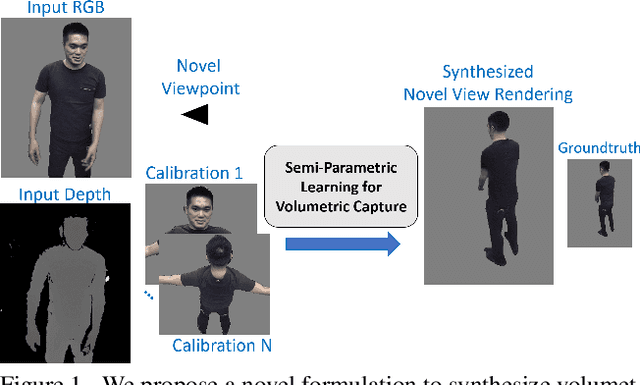

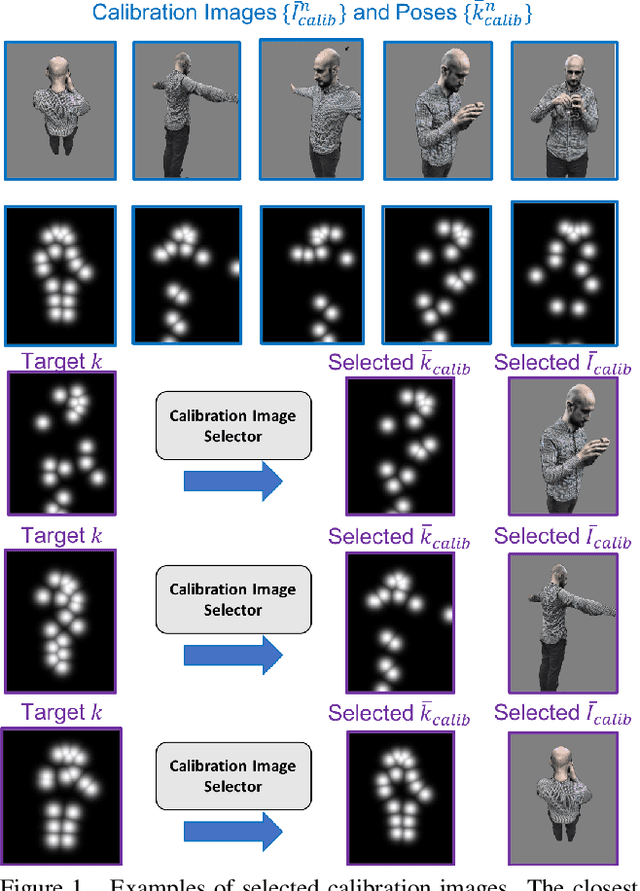
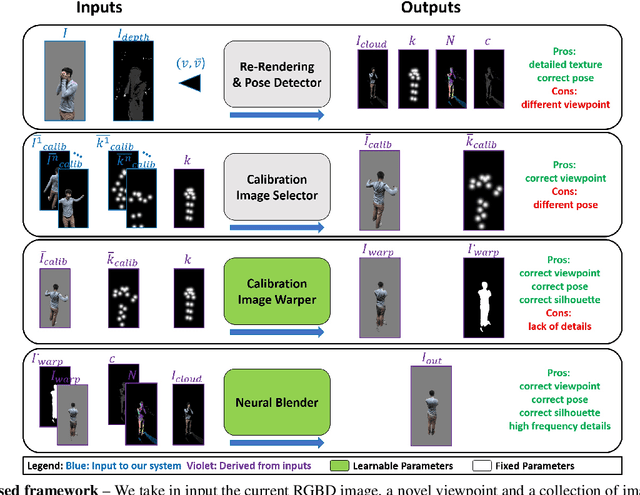
Volumetric (4D) performance capture is fundamental for AR/VR content generation. Whereas previous work in 4D performance capture has shown impressive results in studio settings, the technology is still far from being accessible to a typical consumer who, at best, might own a single RGBD sensor. Thus, in this work, we propose a method to synthesize free viewpoint renderings using a single RGBD camera. The key insight is to leverage previously seen "calibration" images of a given user to extrapolate what should be rendered in a novel viewpoint from the data available in the sensor. Given these past observations from multiple viewpoints, and the current RGBD image from a fixed view, we propose an end-to-end framework that fuses both these data sources to generate novel renderings of the performer. We demonstrate that the method can produce high fidelity images, and handle extreme changes in subject pose and camera viewpoints. We also show that the system generalizes to performers not seen in the training data. We run exhaustive experiments demonstrating the effectiveness of the proposed semi-parametric model (i.e. calibration images available to the neural network) compared to other state of the art machine learned solutions. Further, we compare the method with more traditional pipelines that employ multi-view capture. We show that our framework is able to achieve compelling results, with substantially less infrastructure than previously required.
MIST: Multiple Instance Spatial Transformer Network
Nov 26, 2018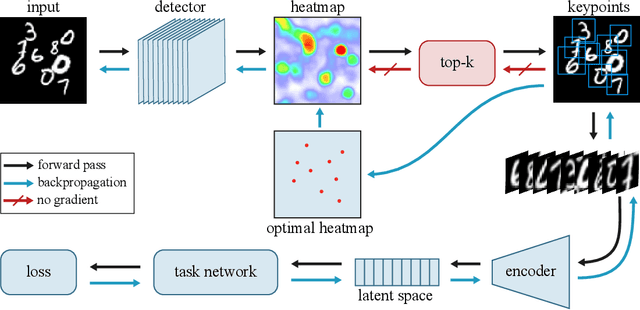
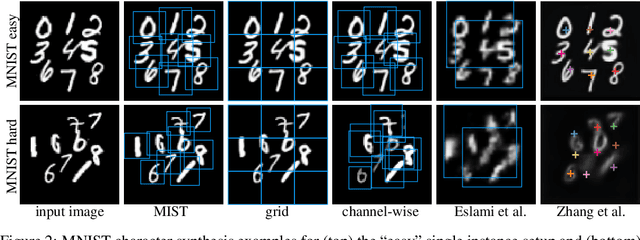
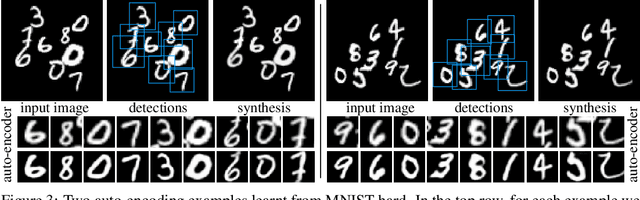

We propose a deep network that can be trained to tackle image reconstruction and classification problems that involve detection of multiple object instances, without any supervision regarding their whereabouts. The network learns to extract the most significant top-K patches, and feeds these patches to a task-specific network -- e.g., auto-encoder or classifier -- to solve a domain specific problem. The challenge in training such a network is the non-differentiable top-K selection process. To address this issue, we lift the training optimization problem by treating the result of top-K selection as a slack variable, resulting in a simple, yet effective, multi-stage training. Our method is able to learn to detect recurrent structures in the training dataset by learning to reconstruct images. It can also learn to localize structures when only knowledge on the occurrence of the object is provided, and in doing so it outperforms the state-of-the-art.
LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Nov 12, 2018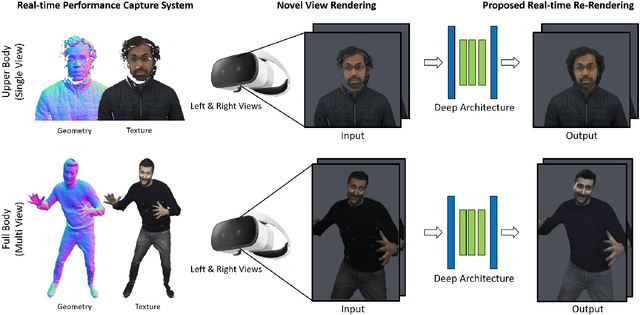
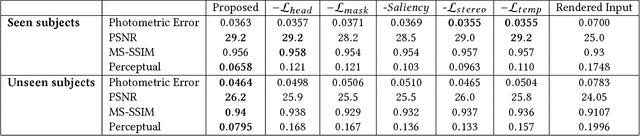


Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. We call this approach neural (re-)rendering, and our live system "LookinGood". Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 degree capture. Through extensive experimentation, we demonstrate how our system generalizes across unseen sequences and subjects. The supplementary video is available at http://youtu.be/Md3tdAKoLGU.
SplineNets: Continuous Neural Decision Graphs
Oct 31, 2018
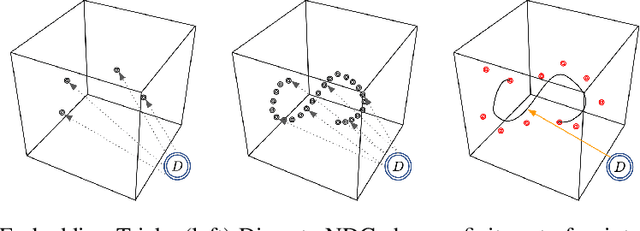

We present SplineNets, a practical and novel approach for using conditioning in convolutional neural networks (CNNs). SplineNets are continuous generalizations of neural decision graphs, and they can dramatically reduce runtime complexity and computation costs of CNNs, while maintaining or even increasing accuracy. Functions of SplineNets are both dynamic (i.e., conditioned on the input) and hierarchical (i.e., conditioned on the computational path). SplineNets employ a unified loss function with a desired level of smoothness over both the network and decision parameters, while allowing for sparse activation of a subset of nodes for individual samples. In particular, we embed infinitely many function weights (e.g. filters) on smooth, low dimensional manifolds parameterized by compact B-splines, which are indexed by a position parameter. Instead of sampling from a categorical distribution to pick a branch, samples choose a continuous position to pick a function weight. We further show that by maximizing the mutual information between spline positions and class labels, the network can be optimally utilized and specialized for classification tasks. Experiments show that our approach can significantly increase the accuracy of ResNets with negligible cost in speed, matching the precision of a 110 level ResNet with a 32 level SplineNet.
StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction
Jul 24, 2018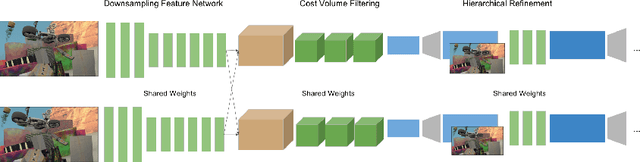
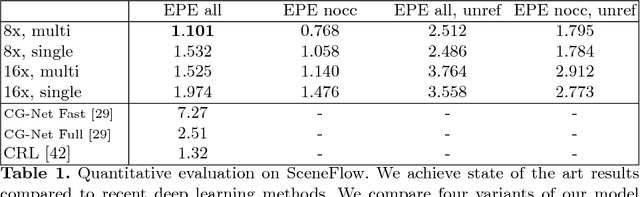

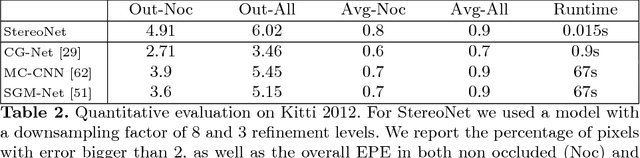
This paper presents StereoNet, the first end-to-end deep architecture for real-time stereo matching that runs at 60 fps on an NVidia Titan X, producing high-quality, edge-preserved, quantization-free disparity maps. A key insight of this paper is that the network achieves a sub-pixel matching precision than is a magnitude higher than those of traditional stereo matching approaches. This allows us to achieve real-time performance by using a very low resolution cost volume that encodes all the information needed to achieve high disparity precision. Spatial precision is achieved by employing a learned edge-aware upsampling function. Our model uses a Siamese network to extract features from the left and right image. A first estimate of the disparity is computed in a very low resolution cost volume, then hierarchically the model re-introduces high-frequency details through a learned upsampling function that uses compact pixel-to-pixel refinement networks. Leveraging color input as a guide, this function is capable of producing high-quality edge-aware output. We achieve compelling results on multiple benchmarks, showing how the proposed method offers extreme flexibility at an acceptable computational budget.
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems
Jul 16, 2018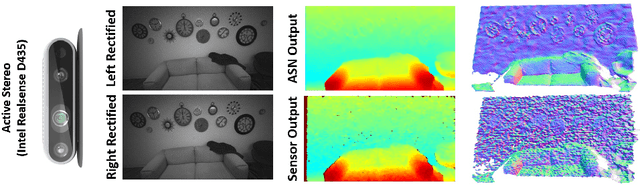
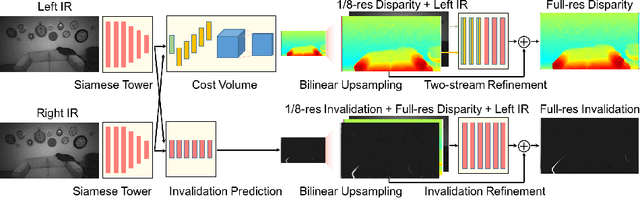

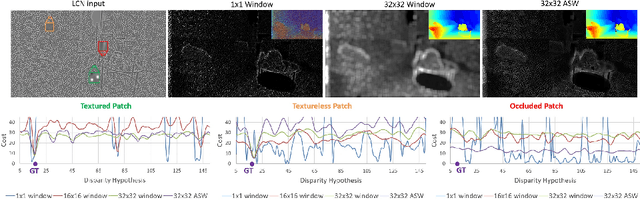
In this paper we present ActiveStereoNet, the first deep learning solution for active stereo systems. Due to the lack of ground truth, our method is fully self-supervised, yet it produces precise depth with a subpixel precision of $1/30th$ of a pixel; it does not suffer from the common over-smoothing issues; it preserves the edges; and it explicitly handles occlusions. We introduce a novel reconstruction loss that is more robust to noise and texture-less patches, and is invariant to illumination changes. The proposed loss is optimized using a window-based cost aggregation with an adaptive support weight scheme. This cost aggregation is edge-preserving and smooths the loss function, which is key to allow the network to reach compelling results. Finally we show how the task of predicting invalid regions, such as occlusions, can be trained end-to-end without ground-truth. This component is crucial to reduce blur and particularly improves predictions along depth discontinuities. Extensive quantitatively and qualitatively evaluations on real and synthetic data demonstrate state of the art results in many challenging scenes.
DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding
Aug 16, 2017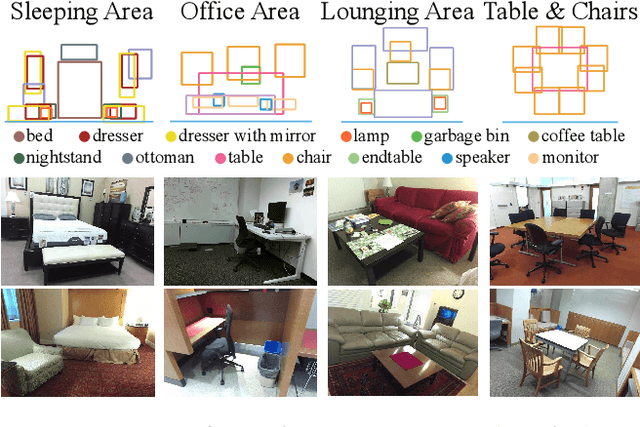
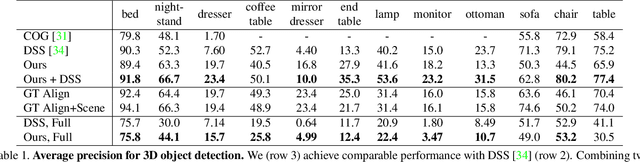

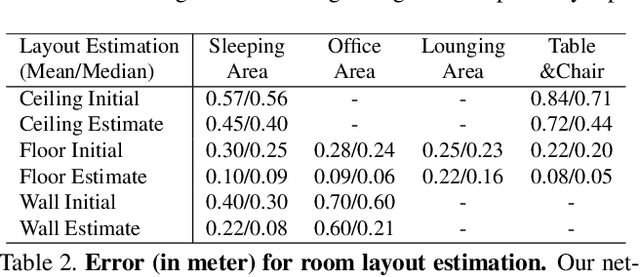
While deep neural networks have led to human-level performance on computer vision tasks, they have yet to demonstrate similar gains for holistic scene understanding. In particular, 3D context has been shown to be an extremely important cue for scene understanding - yet very little research has been done on integrating context information with deep models. This paper presents an approach to embed 3D context into the topology of a neural network trained to perform holistic scene understanding. Given a depth image depicting a 3D scene, our network aligns the observed scene with a predefined 3D scene template, and then reasons about the existence and location of each object within the scene template. In doing so, our model recognizes multiple objects in a single forward pass of a 3D convolutional neural network, capturing both global scene and local object information simultaneously. To create training data for this 3D network, we generate partly hallucinated depth images which are rendered by replacing real objects with a repository of CAD models of the same object category. Extensive experiments demonstrate the effectiveness of our algorithm compared to the state-of-the-arts. Source code and data are available at http://deepcontext.cs.princeton.edu.