 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding
Aug 16, 2017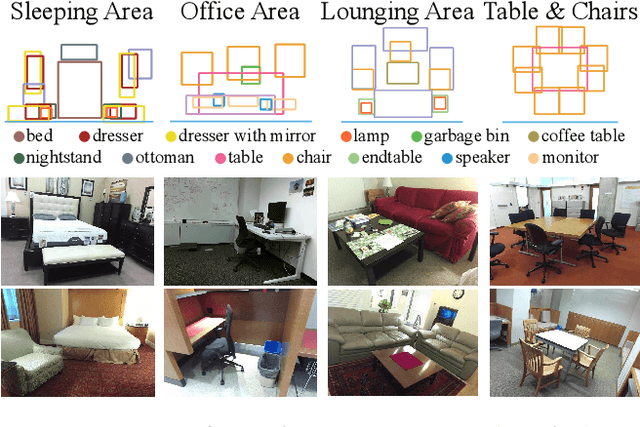
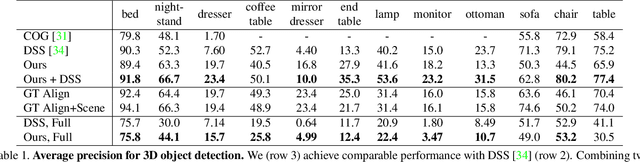

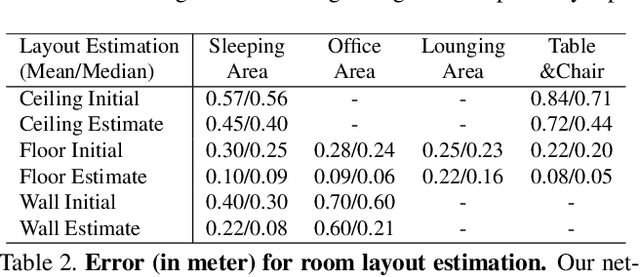
While deep neural networks have led to human-level performance on computer vision tasks, they have yet to demonstrate similar gains for holistic scene understanding. In particular, 3D context has been shown to be an extremely important cue for scene understanding - yet very little research has been done on integrating context information with deep models. This paper presents an approach to embed 3D context into the topology of a neural network trained to perform holistic scene understanding. Given a depth image depicting a 3D scene, our network aligns the observed scene with a predefined 3D scene template, and then reasons about the existence and location of each object within the scene template. In doing so, our model recognizes multiple objects in a single forward pass of a 3D convolutional neural network, capturing both global scene and local object information simultaneously. To create training data for this 3D network, we generate partly hallucinated depth images which are rendered by replacing real objects with a repository of CAD models of the same object category. Extensive experiments demonstrate the effectiveness of our algorithm compared to the state-of-the-arts. Source code and data are available at http://deepcontext.cs.princeton.edu.