 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiresolution Knowledge Distillation for Anomaly Detection
Paper and Code
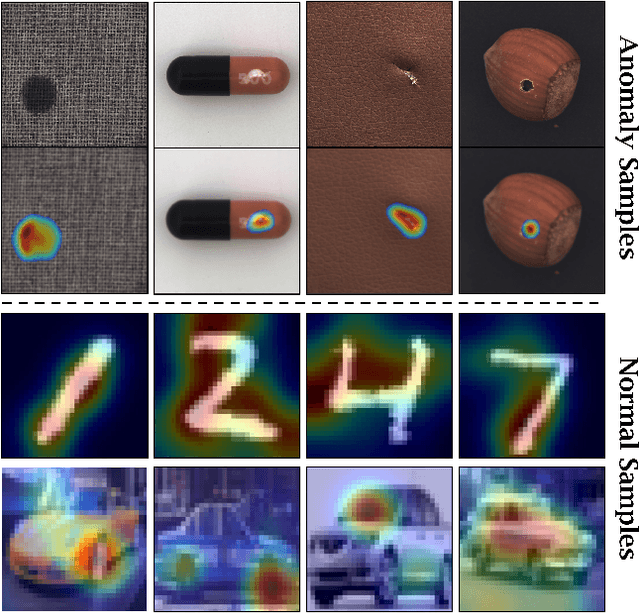
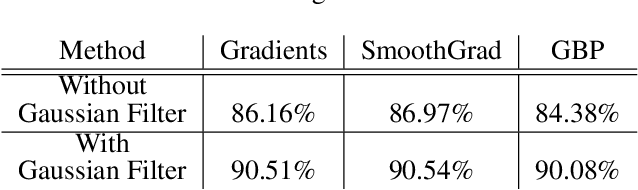
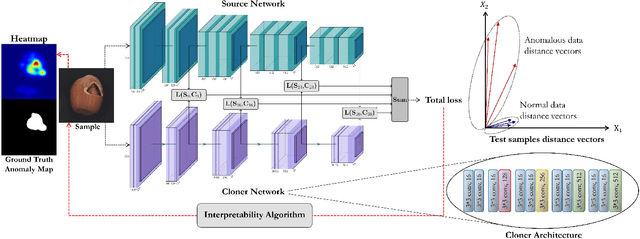
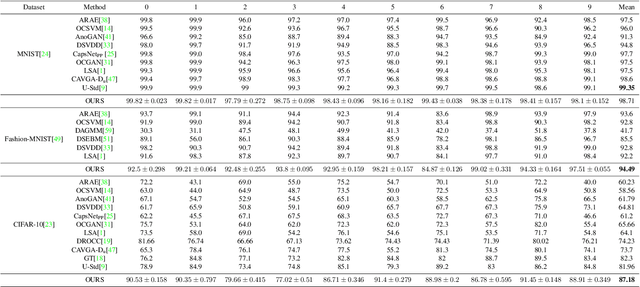
Unsupervised representation learning has proved to be a critical component of anomaly detection/localization in images. The challenges to learn such a representation are two-fold. Firstly, the sample size is not often large enough to learn a rich generalizable representation through conventional techniques. Secondly, while only normal samples are available at training, the learned features should be discriminative of normal and anomalous samples. Here, we propose to use the "distillation" of features at various layers of an expert network, pre-trained on ImageNet, into a simpler cloner network to tackle both issues. We detect and localize anomalies using the discrepancy between the expert and cloner networks' intermediate activation values given the input data. We show that considering multiple intermediate hints in distillation leads to better exploiting the expert's knowledge and more distinctive discrepancy compared to solely utilizing the last layer activation values. Notably, previous methods either fail in precise anomaly localization or need expensive region-based training. In contrast, with no need for any special or intensive training procedure, we incorporate interpretability algorithms in our novel framework for the localization of anomalous regions. Despite the striking contrast between some test datasets and ImageNet, we achieve competitive or significantly superior results compared to the SOTA methods on MNIST, F-MNIST, CIFAR-10, MVTecAD, Retinal-OCT, and two Medical datasets on both anomaly detection and localization.