 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTQL: Scaling Q-Functions with Transformers by Preventing Attention Collapse
Feb 01, 2026Despite scale driving substantial recent advancements in machine learning, reinforcement learning (RL) methods still primarily use small value functions. Naively scaling value functions -- including with a transformer architecture, which is known to be highly scalable -- often results in learning instability and worse performance. In this work, we ask what prevents transformers from scaling effectively for value functions? Through empirical analysis, we identify the critical failure mode in this scaling: attention scores collapse as capacity increases. Our key insight is that we can effectively prevent this collapse and stabilize training by controlling the entropy of the attention scores, thereby enabling the use of larger models. To this end, we propose Transformer Q-Learning (TQL), a method that unlocks the scaling potential of transformers in learning value functions in RL. Our approach yields up to a 43% improvement in performance when scaling from the smallest to the largest network sizes, while prior methods suffer from performance degradation.
Unified Multimodal Discrete Diffusion
Mar 26, 2025Multimodal generative models that can understand and generate across multiple modalities are dominated by autoregressive (AR) approaches, which process tokens sequentially from left to right, or top to bottom. These models jointly handle images, text, video, and audio for various tasks such as image captioning, question answering, and image generation. In this work, we explore discrete diffusion models as a unified generative formulation in the joint text and image domain, building upon their recent success in text generation. Discrete diffusion models offer several advantages over AR models, including improved control over quality versus diversity of generated samples, the ability to perform joint multimodal inpainting (across both text and image domains), and greater controllability in generation through guidance. Leveraging these benefits, we present the first Unified Multimodal Discrete Diffusion (UniDisc) model which is capable of jointly understanding and generating text and images for a variety of downstream tasks. We compare UniDisc to multimodal AR models, performing a scaling analysis and demonstrating that UniDisc outperforms them in terms of both performance and inference-time compute, enhanced controllability, editability, inpainting, and flexible trade-off between inference time and generation quality. Code and additional visualizations are available at https://unidisc.github.io.
Unifying 2D and 3D Vision-Language Understanding
Mar 13, 2025Progress in 3D vision-language learning has been hindered by the scarcity of large-scale 3D datasets. We introduce UniVLG, a unified architecture for 2D and 3D vision-language understanding that bridges the gap between existing 2D-centric models and the rich 3D sensory data available in embodied systems. Our approach initializes most model weights from pre-trained 2D models and trains on both 2D and 3D vision-language data. We propose a novel language-conditioned mask decoder shared across 2D and 3D modalities to ground objects effectively in both RGB and RGB-D images, outperforming box-based approaches. To further reduce the domain gap between 2D and 3D, we incorporate 2D-to-3D lifting strategies, enabling UniVLG to utilize 2D data to enhance 3D performance. With these innovations, our model achieves state-of-the-art performance across multiple 3D vision-language grounding tasks, demonstrating the potential of transferring advances from 2D vision-language learning to the data-constrained 3D domain. Furthermore, co-training on both 2D and 3D data enhances performance across modalities without sacrificing 2D capabilities. By removing the reliance on 3D mesh reconstruction and ground-truth object proposals, UniVLG sets a new standard for realistic, embodied-aligned evaluation. Code and additional visualizations are available at $\href{https://univlg.github.io}{univlg.github.io}$.
Street-View Image Generation from a Bird's-Eye View Layout
Jan 16, 2023
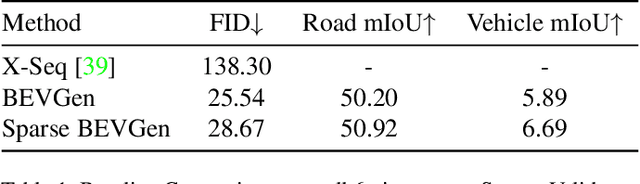
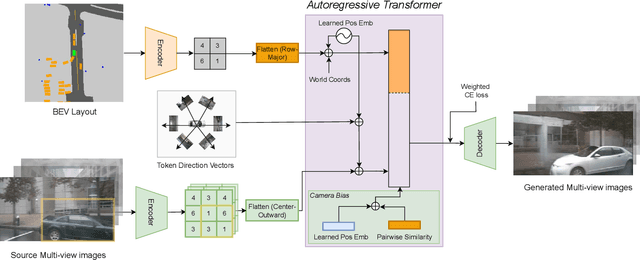

Bird's-Eye View (BEV) Perception has received increasing attention in recent years as it provides a concise and unified spatial representation across views and benefits a diverse set of downstream driving applications. While the focus has been placed on discriminative tasks such as BEV segmentation, the dual generative task of creating street-view images from a BEV layout has rarely been explored. The ability to generate realistic street-view images that align with a given HD map and traffic layout is critical for visualizing complex traffic scenarios and developing robust perception models for autonomous driving. In this paper, we propose BEVGen, a conditional generative model that synthesizes a set of realistic and spatially consistent surrounding images that match the BEV layout of a traffic scenario. BEVGen incorporates a novel cross-view transformation and spatial attention design which learn the relationship between cameras and map views to ensure their consistency. Our model can accurately render road and lane lines, as well as generate traffic scenes under different weather conditions and times of day. The code will be made publicly available.
SCALER: A Tough Versatile Quadruped Free-Climber Robot
Jul 04, 2022

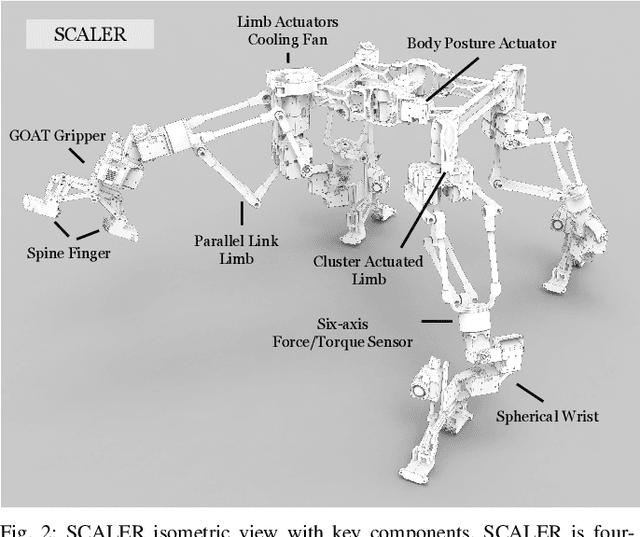
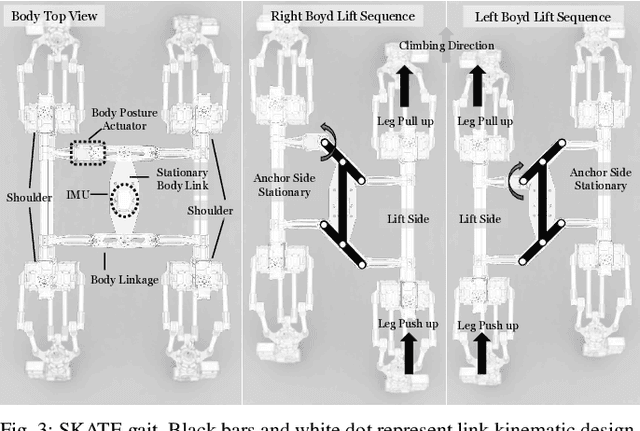
This paper introduces SCALER, a quadrupedal robot that demonstrates climbing on bouldering walls, overhangs, and ceilings and trotting on the ground. SCALER is one of the first high-degrees of freedom four-limbed robots that can free-climb under the Earth's gravity and one of the most mechanically efficient quadrupeds on the ground. Where other state-of-the-art climbers are specialized in climbing itself, SCALER promises practical free-climbing with payload \textit{and} ground locomotion, which realizes true versatile mobility. A new climbing gait, SKATE gait, increases the payload by utilizing the SCALER body linkage mechanism. SCALER achieves a maximum normalized locomotion speed of $1.87$ /s, or $0.56$ m/s on the ground and $1.2$ /min, or $0.42$ m/min in bouldering wall climbing. Payload capacity reaches $233$ % of the SCALER weight on the ground and $35$ % on the vertical wall. Our GOAT gripper, a mechanically adaptable underactuated two-finger gripper, successfully grasps convex and non-convex objects and supports SCALER.