 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOncilla robot: a versatile open-source quadruped research robot with compliant pantograph legs
Jun 16, 2018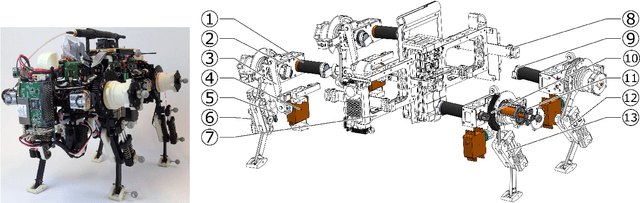
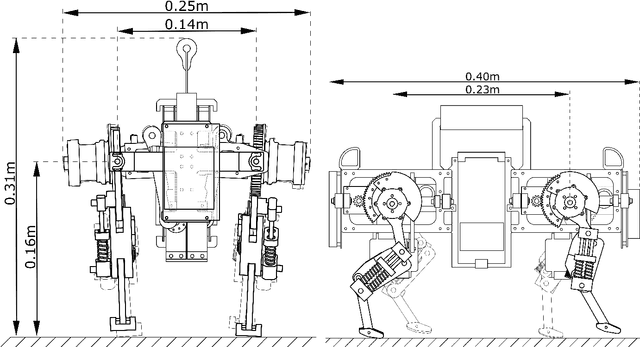

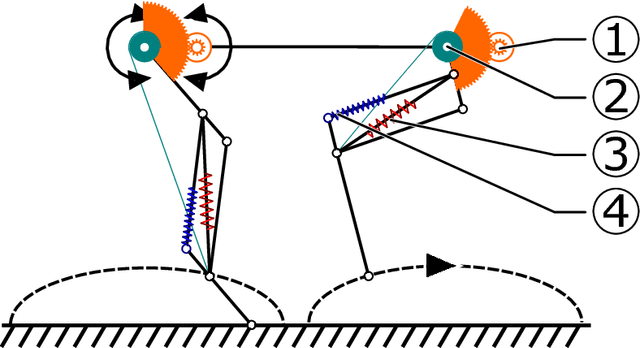
We present Oncilla robot, a novel mobile, quadruped legged locomotion machine. This large-cat sized, 5.1 robot is one of a kind of a recent, bioinspired legged robot class designed with the capability of model-free locomotion control. Animal legged locomotion in rough terrain is clearly shaped by sensor feedback systems. Results with Oncilla robot show that agile and versatile locomotion is possible without sensory signals to some extend, and tracking becomes robust when feedback control is added (Ajaoolleian 2015). By incorporating mechanical and control blueprints inspired from animals, and by observing the resulting robot locomotion characteristics, we aim to understand the contribution of individual components. Legged robots have a wide mechanical and control design parameter space, and a unique potential as research tools to investigate principles of biomechanics and legged locomotion control. But the hardware and controller design can be a steep initial hurdle for academic research. To facilitate the easy start and development of legged robots, Oncilla-robot's blueprints are available through open-source. [...]
Deep Reinforcement Learning for Tensegrity Robot Locomotion
Mar 08, 2017

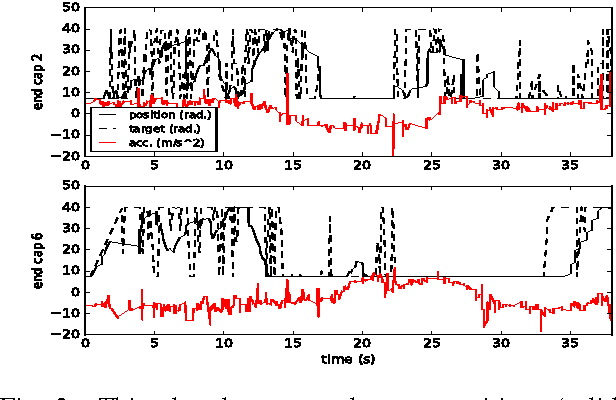
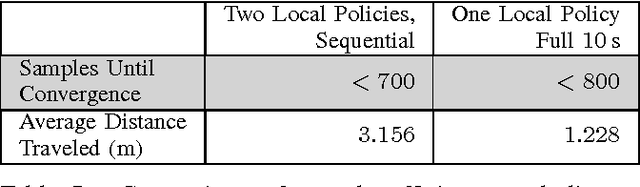
Tensegrity robots, composed of rigid rods connected by elastic cables, have a number of unique properties that make them appealing for use as planetary exploration rovers. However, control of tensegrity robots remains a difficult problem due to their unusual structures and complex dynamics. In this work, we show how locomotion gaits can be learned automatically using a novel extension of mirror descent guided policy search (MDGPS) applied to periodic locomotion movements, and we demonstrate the effectiveness of our approach on tensegrity robot locomotion. We evaluate our method with real-world and simulated experiments on the SUPERball tensegrity robot, showing that the learned policies generalize to changes in system parameters, unreliable sensor measurements, and variation in environmental conditions, including varied terrains and a range of different gravities. Our experiments demonstrate that our method not only learns fast, power-efficient feedback policies for rolling gaits, but that these policies can succeed with only the limited onboard sensing provided by SUPERball's accelerometers. We compare the learned feedback policies to learned open-loop policies and hand-engineered controllers, and demonstrate that the learned policy enables the first continuous, reliable locomotion gait for the real SUPERball robot. Our code and other supplementary materials are available from http://rll.berkeley.edu/drl_tensegrity