 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning
Paper and Code
Jun 18, 2017
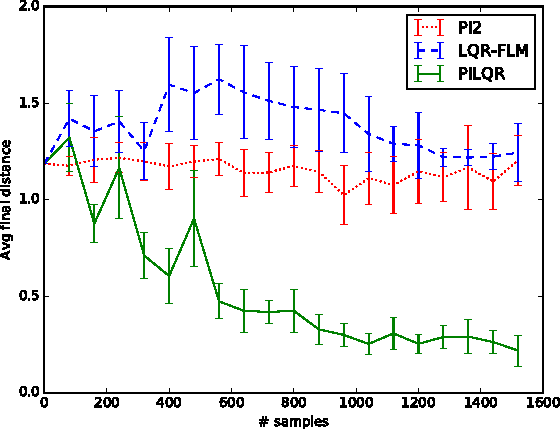
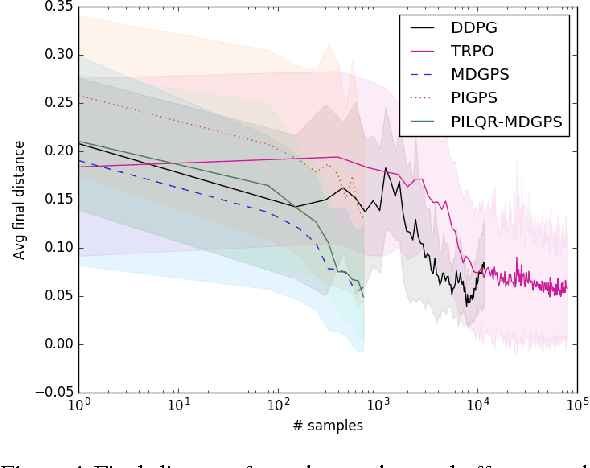
Reinforcement learning (RL) algorithms for real-world robotic applications need a data-efficient learning process and the ability to handle complex, unknown dynamical systems. These requirements are handled well by model-based and model-free RL approaches, respectively. In this work, we aim to combine the advantages of these two types of methods in a principled manner. By focusing on time-varying linear-Gaussian policies, we enable a model-based algorithm based on the linear quadratic regulator (LQR) that can be integrated into the model-free framework of path integral policy improvement (PI2). We can further combine our method with guided policy search (GPS) to train arbitrary parameterized policies such as deep neural networks. Our simulation and real-world experiments demonstrate that this method can solve challenging manipulation tasks with comparable or better performance than model-free methods while maintaining the sample efficiency of model-based methods. A video presenting our results is available at https://sites.google.com/site/icml17pilqr