 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoice between Partial Trajectories
Paper and Code
Oct 30, 2024

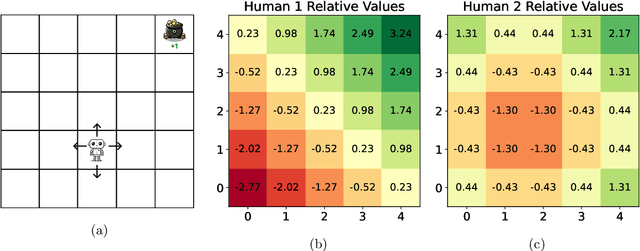

As AI agents generate increasingly sophisticated behaviors, manually encoding human preferences to guide these agents becomes more challenging. To address this, it has been suggested that agents instead learn preferences from human choice data. This approach requires a model of choice behavior that the agent can use to interpret the data. For choices between partial trajectories of states and actions, previous models assume choice probabilities to be determined by the partial return or the cumulative advantage. We consider an alternative model based instead on the bootstrapped return, which adds to the partial return an estimate of the future return. Benefits of the bootstrapped return model stem from its treatment of human beliefs. Unlike partial return, choices based on bootstrapped return reflect human beliefs about the environment. Further, while recovering the reward function from choices based on cumulative advantage requires that those beliefs are correct, doing so from choices based on bootstrapped return does not. To motivate the bootstrapped return model, we formulate axioms and prove an Alignment Theorem. This result formalizes how, for a general class of human preferences, such models are able to disentangle goals from beliefs. This ensures recovery of an aligned reward function when learning from choices based on bootstrapped return. The bootstrapped return model also affords greater robustness to choice behavior. Even when choices are based on partial return, learning via a bootstrapped return model recovers an aligned reward function. The same holds with choices based on the cumulative advantage if the human and the agent both adhere to correct and consistent beliefs about the environment. On the other hand, if choices are based on bootstrapped return, learning via partial return or cumulative advantage models does not generally produce an aligned reward function.