 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks
May 02, 2024Large Language Models (LLMs) have been shown to be capable of performing high-level planning for long-horizon robotics tasks, yet existing methods require access to a pre-defined skill library (e.g. picking, placing, pulling, pushing, navigating). However, LLM planning does not address how to design or learn those behaviors, which remains challenging particularly in long-horizon settings. Furthermore, for many tasks of interest, the robot needs to be able to adjust its behavior in a fine-grained manner, requiring the agent to be capable of modifying low-level control actions. Can we instead use the internet-scale knowledge from LLMs for high-level policies, guiding reinforcement learning (RL) policies to efficiently solve robotic control tasks online without requiring a pre-determined set of skills? In this paper, we propose Plan-Seq-Learn (PSL): a modular approach that uses motion planning to bridge the gap between abstract language and learned low-level control for solving long-horizon robotics tasks from scratch. We demonstrate that PSL achieves state-of-the-art results on over 25 challenging robotics tasks with up to 10 stages. PSL solves long-horizon tasks from raw visual input spanning four benchmarks at success rates of over 85%, out-performing language-based, classical, and end-to-end approaches. Video results and code at https://mihdalal.github.io/planseqlearn/
Personalized Federated Learning for Heterogeneous Clients with Clustered Knowledge Transfer
Sep 16, 2021
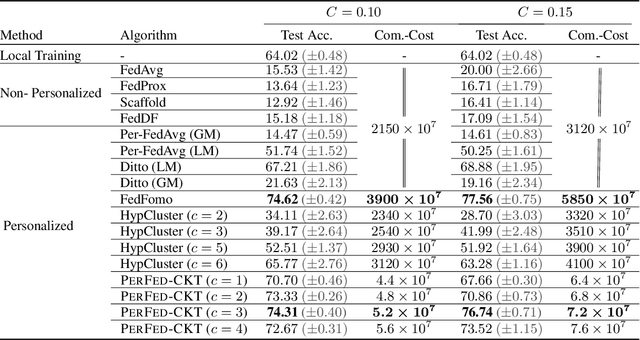


Personalized federated learning (FL) aims to train model(s) that can perform well for individual clients that are highly data and system heterogeneous. Most work in personalized FL, however, assumes using the same model architecture at all clients and increases the communication cost by sending/receiving models. This may not be feasible for realistic scenarios of FL. In practice, clients have highly heterogeneous system-capabilities and limited communication resources. In our work, we propose a personalized FL framework, PerFed-CKT, where clients can use heterogeneous model architectures and do not directly communicate their model parameters. PerFed-CKT uses clustered co-distillation, where clients use logits to transfer their knowledge to other clients that have similar data-distributions. We theoretically show the convergence and generalization properties of PerFed-CKT and empirically show that PerFed-CKT achieves high test accuracy with several orders of magnitude lower communication cost compared to the state-of-the-art personalized FL schemes.