 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Capacity of a Large-scale Masked Language Model to Recognize Grammatical Errors
Aug 27, 2021
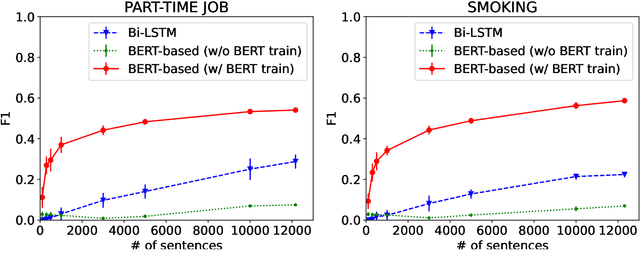
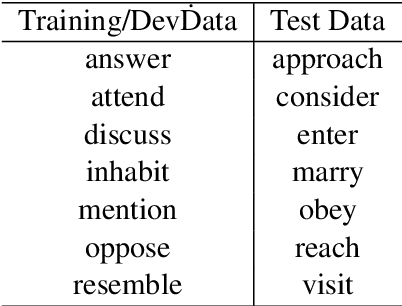
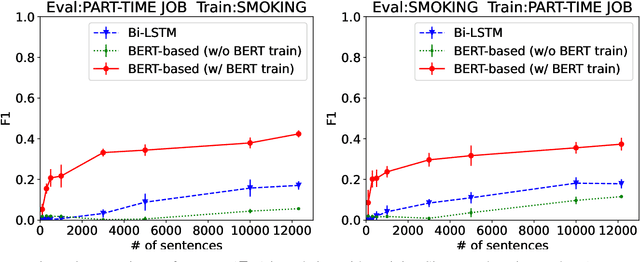
In this paper, we explore the capacity of a language model-based method for grammatical error detection in detail. We first show that 5 to 10% of training data are enough for a BERT-based error detection method to achieve performance equivalent to a non-language model-based method can achieve with the full training data; recall improves much faster with respect to training data size in the BERT-based method than in the non-language model method while precision behaves similarly. These suggest that (i) the BERT-based method should have a good knowledge of grammar required to recognize certain types of error and that (ii) it can transform the knowledge into error detection rules by fine-tuning with a few training samples, which explains its high generalization ability in grammatical error detection. We further show with pseudo error data that it actually exhibits such nice properties in learning rules for recognizing various types of error. Finally, based on these findings, we explore a cost-effective method for detecting grammatical errors with feedback comments explaining relevant grammatical rules to learners.
Information-Maximization Clustering based on Squared-Loss Mutual Information
Dec 03, 2011Information-maximization clustering learns a probabilistic classifier in an unsupervised manner so that mutual information between feature vectors and cluster assignments is maximized. A notable advantage of this approach is that it only involves continuous optimization of model parameters, which is substantially easier to solve than discrete optimization of cluster assignments. However, existing methods still involve non-convex optimization problems, and therefore finding a good local optimal solution is not straightforward in practice. In this paper, we propose an alternative information-maximization clustering method based on a squared-loss variant of mutual information. This novel approach gives a clustering solution analytically in a computationally efficient way via kernel eigenvalue decomposition. Furthermore, we provide a practical model selection procedure that allows us to objectively optimize tuning parameters included in the kernel function. Through experiments, we demonstrate the usefulness of the proposed approach.