 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntervention-Based Time Series Causal Discovery via Simulator-Generated Interventional Distributions
May 11, 2026We propose SVAR-FM (Structural VAR with Flow Matching), a framework for time series causal discovery that treats a physics-based simulator as a mechanical realization of Pearl's do operator. Clamping a variable inside the simulator physically severs confounding paths, producing interventional data by construction. Conditional Flow Matching then learns the nonlinear interventional conditionals. Theoretically, we prove that the full structural VAR becomes identifiable under a coverage condition on the simulator-clampable variables, and derive an end-to-end error bound that decomposes into Monte Carlo, simulator fidelity, and Flow Matching terms. A sign-flip corollary predicts that when simulator accuracy falls below a threshold, the estimated causal effect reverses sign. Empirically, a benchmark across four scientific domains confirms that SVAR-FM recovers the correct causal sign where observational methods produce sign-reversed estimates due to confounding. A case study in ultrafast laser physics verifies the sign-flip prediction by physically varying the accuracy level of a first-principles quantum solver: the low-accuracy setting reverses the causal sign, while the high-accuracy setting recovers the correct direction (R-squared = 0.983, zero bias).
High-Performance Self-Supervised Learning by Joint Training of Flow Matching
Dec 17, 2025Diffusion models can learn rich representations during data generation, showing potential for Self-Supervised Learning (SSL), but they face a trade-off between generative quality and discriminative performance. Their iterative sampling also incurs substantial computational and energy costs, hindering industrial and edge AI applications. To address these issues, we propose the Flow Matching-based Foundation Model (FlowFM), which jointly trains a representation encoder and a conditional flow matching generator. This decoupled design achieves both high-fidelity generation and effective recognition. By using flow matching to learn a simpler velocity field, FlowFM accelerates and stabilizes training, improving its efficiency for representation learning. Experiments on wearable sensor data show FlowFM reduces training time by 50.4\% compared to a diffusion-based approach. On downstream tasks, FlowFM surpassed the state-of-the-art SSL method (SSL-Wearables) on all five datasets while achieving up to a 51.0x inference speedup and maintaining high generative quality. The implementation code is available at https://github.com/Okita-Laboratory/jointOptimizationFlowMatching.
Knowledge Distillation for Reservoir-based Classifier: Human Activity Recognition
May 29, 2025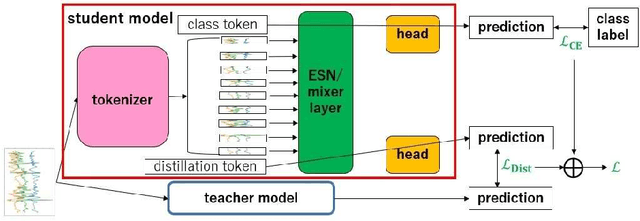
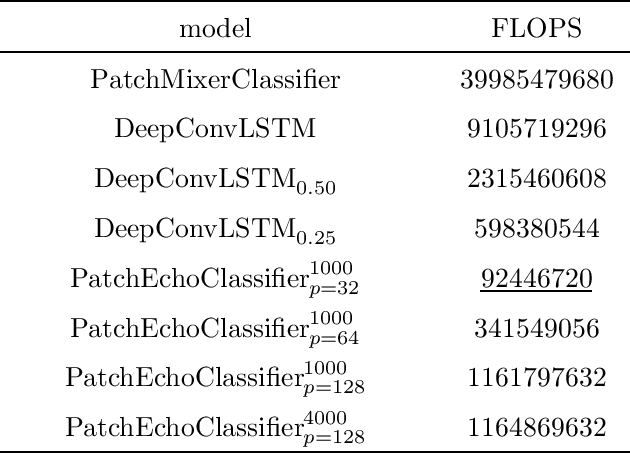
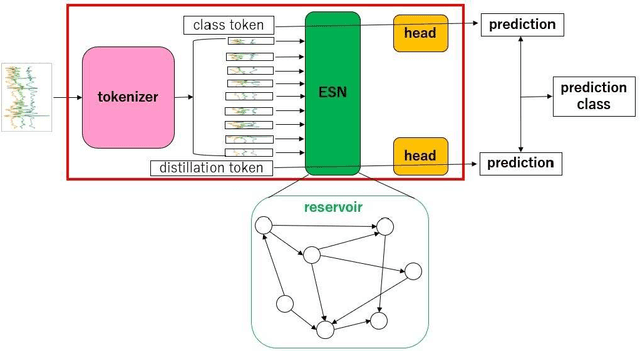
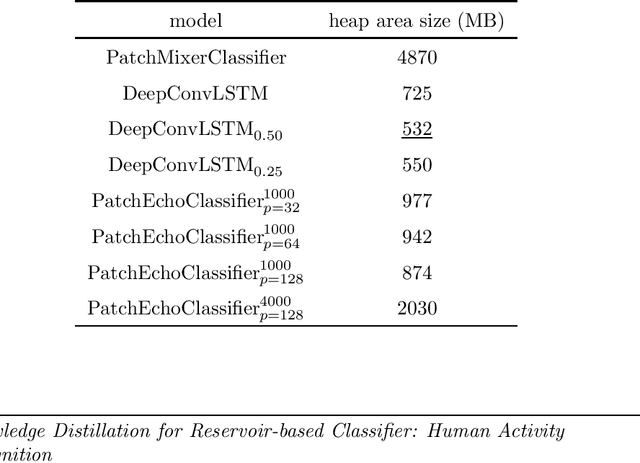
This paper aims to develop an energy-efficient classifier for time-series data by introducing PatchEchoClassifier, a novel model that leverages a reservoir-based mechanism known as the Echo State Network (ESN). The model is designed for human activity recognition (HAR) using one-dimensional sensor signals and incorporates a tokenizer to extract patch-level representations. To train the model efficiently, we propose a knowledge distillation framework that transfers knowledge from a high-capacity MLP-Mixer teacher to the lightweight reservoir-based student model. Experimental evaluations on multiple HAR datasets demonstrate that our model achieves over 80 percent accuracy while significantly reducing computational cost. Notably, PatchEchoClassifier requires only about one-sixth of the floating point operations (FLOPS) compared to DeepConvLSTM, a widely used convolutional baseline. These results suggest that PatchEchoClassifier is a promising solution for real-time and energy-efficient human activity recognition in edge computing environments.
Diffusion Model-based Activity Completion for AI Motion Capture from Videos
May 27, 2025AI-based motion capture is an emerging technology that offers a cost-effective alternative to traditional motion capture systems. However, current AI motion capture methods rely entirely on observed video sequences, similar to conventional motion capture. This means that all human actions must be predefined, and movements outside the observed sequences are not possible. To address this limitation, we aim to apply AI motion capture to virtual humans, where flexible actions beyond the observed sequences are required. We assume that while many action fragments exist in the training data, the transitions between them may be missing. To bridge these gaps, we propose a diffusion-model-based action completion technique that generates complementary human motion sequences, ensuring smooth and continuous movements. By introducing a gate module and a position-time embedding module, our approach achieves competitive results on the Human3.6M dataset. Our experimental results show that (1) MDC-Net outperforms existing methods in ADE, FDE, and MMADE but is slightly less accurate in MMFDE, (2) MDC-Net has a smaller model size (16.84M) compared to HumanMAC (28.40M), and (3) MDC-Net generates more natural and coherent motion sequences. Additionally, we propose a method for extracting sensor data, including acceleration and angular velocity, from human motion sequences.
Multi-instance Learning as Downstream Task of Self-Supervised Learning-based Pre-trained Model
May 27, 2025In deep multi-instance learning, the number of applicable instances depends on the data set. In histopathology images, deep learning multi-instance learners usually assume there are hundreds to thousands instances in a bag. However, when the number of instances in a bag increases to 256 in brain hematoma CT, learning becomes extremely difficult. In this paper, we address this drawback. To overcome this problem, we propose using a pre-trained model with self-supervised learning for the multi-instance learner as a downstream task. With this method, even when the original target task suffers from the spurious correlation problem, we show improvements of 5% to 13% in accuracy and 40% to 55% in the F1 measure for the hypodensity marker classification of brain hematoma CT.
Detecting Informative Channels: ActionFormer
May 27, 2025Human Activity Recognition (HAR) has recently witnessed advancements with Transformer-based models. Especially, ActionFormer shows us a new perspectives for HAR in the sense that this approach gives us additional outputs which detect the border of the activities as well as the activity labels. ActionFormer was originally proposed with its input as image/video. However, this was converted to with its input as sensor signals as well. We analyze this extensively in terms of deep learning architectures. Based on the report of high temporal dynamics which limits the model's ability to capture subtle changes effectively and of the interdependencies between the spatial and temporal features. We propose the modified ActionFormer which will decrease these defects for sensor signals. The key to our approach lies in accordance with the Sequence-and-Excitation strategy to minimize the increase in additional parameters and opt for the swish activation function to retain the information about direction in the negative range. Experiments on the WEAR dataset show that our method achieves substantial improvement of a 16.01\% in terms of average mAP for inertial data.
Thoughts on Objectives of Sparse and Hierarchical Masked Image Model
May 12, 2025Masked image modeling is one of the most poplular objectives of training. Recently, the SparK model has been proposed with superior performance among self-supervised learning models. This paper proposes a new mask pattern for this SparK model, proposing it as the Mesh Mask-ed SparK model. We report the effect of the mask pattern used for image masking in pre-training on performance.
Image Classification Using a Diffusion Model as a Pre-Training Model
May 11, 2025In this paper, we propose a diffusion model that integrates a representation-conditioning mechanism, where the representations derived from a Vision Transformer (ViT) are used to condition the internal process of a Transformer-based diffusion model. This approach enables representation-conditioned data generation, addressing the challenge of requiring large-scale labeled datasets by leveraging self-supervised learning on unlabeled data. We evaluate our method through a zero-shot classification task for hematoma detection in brain imaging. Compared to the strong contrastive learning baseline, DINOv2, our method achieves a notable improvement of +6.15% in accuracy and +13.60% in F1-score, demonstrating its effectiveness in image classification.
Brain Hematoma Marker Recognition Using Multitask Learning: SwinTransformer and Swin-Unet
May 09, 2025



This paper proposes a method MTL-Swin-Unet which is multi-task learning using transformers for classification and semantic segmentation. For spurious-correlation problems, this method allows us to enhance the image representation with two other image representations: representation obtained by semantic segmentation and representation obtained by image reconstruction. In our experiments, the proposed method outperformed in F-value measure than other classifiers when the test data included slices from the same patient (no covariate shift). Similarly, when the test data did not include slices from the same patient (covariate shift setting), the proposed method outperformed in AUC measure.
LCP-dropout: Compression-based Multiple Subword Segmentation for Neural Machine Translation
Mar 19, 2022



In this study, we propose a simple and effective preprocessing method for subword segmentation based on a data compression algorithm. Compression-based subword segmentation has recently attracted significant attention as a preprocessing method for training data in Neural Machine Translation. Among them, BPE/BPE-dropout is one of the fastest and most effective method compared to conventional approaches. However, compression-based approach has a drawback in that generating multiple segmentations is difficult due to the determinism. To overcome this difficulty, we focus on a probabilistic string algorithm, called locally-consistent parsing (LCP), that has been applied to achieve optimum compression. Employing the probabilistic mechanism of LCP, we propose LCP-dropout for multiple subword segmentation that improves BPE/BPE-dropout, and show that it outperforms various baselines in learning from especially small training data.