 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAYKATE: Hybrid In-Context Example Selection Combining Representativeness Sampling and Retrieval-based Approach -- A Case Study on Science Domains
Dec 28, 2024Large language models (LLMs) demonstrate the ability to learn in-context, offering a potential solution for scientific information extraction, which often contends with challenges such as insufficient training data and the high cost of annotation processes. Given that the selection of in-context examples can significantly impact performance, it is crucial to design a proper method to sample the efficient ones. In this paper, we propose STAYKATE, a static-dynamic hybrid selection method that combines the principles of representativeness sampling from active learning with the prevalent retrieval-based approach. The results across three domain-specific datasets indicate that STAYKATE outperforms both the traditional supervised methods and existing selection methods. The enhancement in performance is particularly pronounced for entity types that other methods pose challenges.
Share What You Already Know: Cross-Language-Script Transfer and Alignment for Sentiment Detection in Code-Mixed Data
Feb 07, 2024
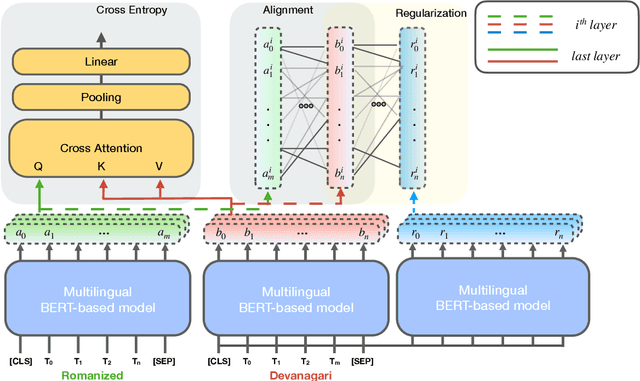

Code-switching entails mixing multiple languages. It is an increasingly occurring phenomenon in social media texts. Usually, code-mixed texts are written in a single script, even though the languages involved have different scripts. Pre-trained multilingual models primarily utilize the data in the native script of the language. In existing studies, the code-switched texts are utilized as they are. However, using the native script for each language can generate better representations of the text owing to the pre-trained knowledge. Therefore, a cross-language-script knowledge sharing architecture utilizing the cross attention and alignment of the representations of text in individual language scripts was proposed in this study. Experimental results on two different datasets containing Nepali-English and Hindi-English code-switched texts, demonstrate the effectiveness of the proposed method. The interpretation of the model using model explainability technique illustrates the sharing of language-specific knowledge between language-specific representations.
LCP-dropout: Compression-based Multiple Subword Segmentation for Neural Machine Translation
Mar 19, 2022



In this study, we propose a simple and effective preprocessing method for subword segmentation based on a data compression algorithm. Compression-based subword segmentation has recently attracted significant attention as a preprocessing method for training data in Neural Machine Translation. Among them, BPE/BPE-dropout is one of the fastest and most effective method compared to conventional approaches. However, compression-based approach has a drawback in that generating multiple segmentations is difficult due to the determinism. To overcome this difficulty, we focus on a probabilistic string algorithm, called locally-consistent parsing (LCP), that has been applied to achieve optimum compression. Employing the probabilistic mechanism of LCP, we propose LCP-dropout for multiple subword segmentation that improves BPE/BPE-dropout, and show that it outperforms various baselines in learning from especially small training data.