 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShare What You Already Know: Cross-Language-Script Transfer and Alignment for Sentiment Detection in Code-Mixed Data
Paper and Code

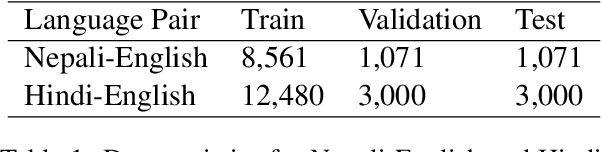
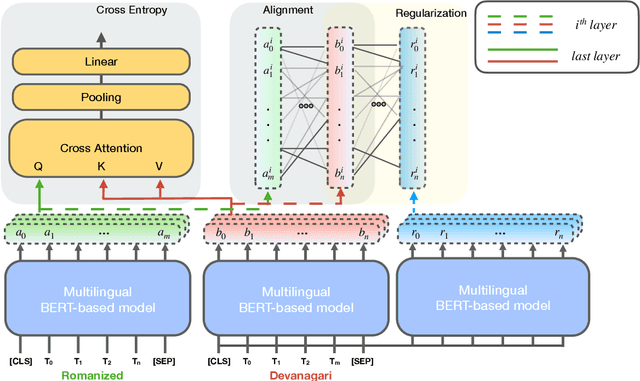

Code-switching entails mixing multiple languages. It is an increasingly occurring phenomenon in social media texts. Usually, code-mixed texts are written in a single script, even though the languages involved have different scripts. Pre-trained multilingual models primarily utilize the data in the native script of the language. In existing studies, the code-switched texts are utilized as they are. However, using the native script for each language can generate better representations of the text owing to the pre-trained knowledge. Therefore, a cross-language-script knowledge sharing architecture utilizing the cross attention and alignment of the representations of text in individual language scripts was proposed in this study. Experimental results on two different datasets containing Nepali-English and Hindi-English code-switched texts, demonstrate the effectiveness of the proposed method. The interpretation of the model using model explainability technique illustrates the sharing of language-specific knowledge between language-specific representations.