 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback-to-Rubrics: Can We Learn Expert Criteria from Inline Comments?
May 28, 2026Large language models (LLMs) are increasingly used for writing and review support, but their usefulness depends on context-dependent criteria, such as expert preferences or organization-specific conventions, that are often tacit, undocumented, and difficult to elicit directly. We propose a problem setting for learning reusable natural-language rubrics from accumulated inline comments on artifacts such as human-written or LLM-generated drafts. Our method infers rubrics from these comments and iteratively refines them by observing comment-wise mismatches between rubric-conditioned predictions and reference comments. We evaluate the proposed method in real-world review settings and in controlled settings with reference rubrics. These results show that inline comments can be distilled into reusable rubrics that support comment prediction, rubric understanding, and automatic artifact revision.
Revisiting Generalization Measures Beyond IID: An Empirical Study under Distributional Shift
Feb 02, 2026Generalization remains a central yet unresolved challenge in deep learning, particularly the ability to predict a model's performance beyond its training distribution using quantities available prior to test-time evaluation. Building on the large-scale study of Jiang et al. (2020). and concerns by Dziugaite et al. (2020). about instability across training configurations, we benchmark the robustness of generalization measures beyond IID regime. We train small-to-medium models over 10,000 hyperparameter configurations and evaluate more than 40 measures computable from the trained model and the available training data alone. We significantly broaden the experimental scope along multiple axes: (i) extending the evaluation beyond the standard IID setting to include benchmarking for robustness across diverse distribution shifts, (ii) evaluating multiple architectures and training recipes, and (iii) newly incorporating calibration- and information-criteria-based measures to assess their alignment with both IID and OOD generalization. We find that distribution shifts can substantially alter the predictive performance of many generalization measures, while a smaller subset remains comparatively stable across settings.
On Fairness of Task Arithmetic: The Role of Task Vectors
May 30, 2025Model editing techniques, particularly task arithmetic using task vectors, have shown promise in efficiently modifying pre-trained models through arithmetic operations like task addition and negation. Despite computational advantages, these methods may inadvertently affect model fairness, creating risks in sensitive applications like hate speech detection. However, the fairness implications of task arithmetic remain largely unexplored, presenting a critical gap in the existing literature. We systematically examine how manipulating task vectors affects fairness metrics, including Demographic Parity and Equalized Odds. To rigorously assess these effects, we benchmark task arithmetic against full fine-tuning, a costly but widely used baseline, and Low-Rank Adaptation (LoRA), a prevalent parameter-efficient fine-tuning method. Additionally, we explore merging task vectors from models fine-tuned on demographic subgroups vulnerable to hate speech, investigating whether fairness outcomes can be controlled by adjusting task vector coefficients, potentially enabling tailored model behavior. Our results offer novel insights into the fairness implications of model editing and establish a foundation for fairness-aware and responsible model editing practices.
Robust Invariant Representation Learning by Distribution Extrapolation
May 22, 2025
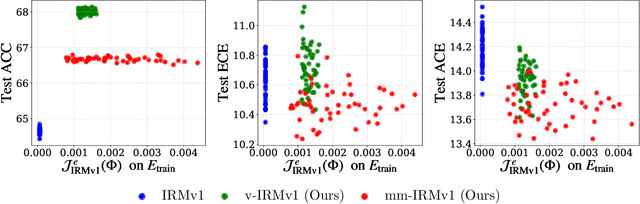
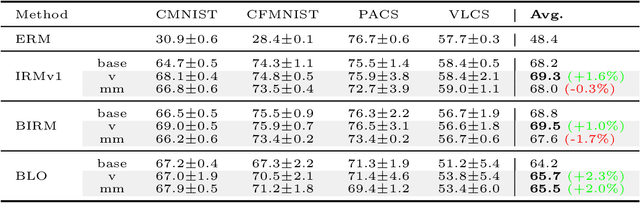
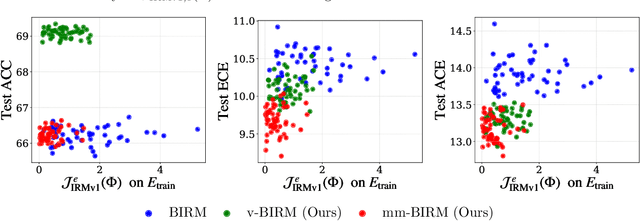
Invariant risk minimization (IRM) aims to enable out-of-distribution (OOD) generalization in deep learning by learning invariant representations. As IRM poses an inherently challenging bi-level optimization problem, most existing approaches -- including IRMv1 -- adopt penalty-based single-level approximations. However, empirical studies consistently show that these methods often fail to outperform well-tuned empirical risk minimization (ERM), highlighting the need for more robust IRM implementations. This work theoretically identifies a key limitation common to many IRM variants: their penalty terms are highly sensitive to limited environment diversity and over-parameterization, resulting in performance degradation. To address this issue, a novel extrapolation-based framework is proposed that enhances environmental diversity by augmenting the IRM penalty through synthetic distributional shifts. Extensive experiments -- ranging from synthetic setups to realistic, over-parameterized scenarios -- demonstrate that the proposed method consistently outperforms state-of-the-art IRM variants, validating its effectiveness and robustness.
Towards Understanding Variants of Invariant Risk Minimization through the Lens of Calibration
Jan 31, 2024Machine learning models traditionally assume that training and test data are independently and identically distributed. However, in real-world applications, the test distribution often differs from training. This problem, known as out-of-distribution generalization, challenges conventional models. Invariant Risk Minimization (IRM) emerges as a solution, aiming to identify features invariant across different environments to enhance out-of-distribution robustness. However, IRM's complexity, particularly its bi-level optimization, has led to the development of various approximate methods. Our study investigates these approximate IRM techniques, employing the Expected Calibration Error (ECE) as a key metric. ECE, which measures the reliability of model prediction, serves as an indicator of whether models effectively capture environment-invariant features. Through a comparative analysis of datasets with distributional shifts, we observe that Information Bottleneck-based IRM, which condenses representational information, achieves a balance in improving ECE while preserving accuracy relatively. This finding is pivotal, as it demonstrates a feasible path to maintaining robustness without compromising accuracy. Nonetheless, our experiments also caution against over-regularization, which can diminish accuracy. This underscores the necessity for a systematic approach in evaluating out-of-distribution generalization metrics, one that beyond mere accuracy to address the nuanced interplay between accuracy and calibration.