 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Grounding of Whole Radiology Reports for 3D CT Images
Dec 08, 2023Building a large-scale training dataset is an essential problem in the development of medical image recognition systems. Visual grounding techniques, which automatically associate objects in images with corresponding descriptions, can facilitate labeling of large number of images. However, visual grounding of radiology reports for CT images remains challenging, because so many kinds of anomalies are detectable via CT imaging, and resulting report descriptions are long and complex. In this paper, we present the first visual grounding framework designed for CT image and report pairs covering various body parts and diverse anomaly types. Our framework combines two components of 1) anatomical segmentation of images, and 2) report structuring. The anatomical segmentation provides multiple organ masks of given CT images, and helps the grounding model recognize detailed anatomies. The report structuring helps to accurately extract information regarding the presence, location, and type of each anomaly described in corresponding reports. Given the two additional image/report features, the grounding model can achieve better localization. In the verification process, we constructed a large-scale dataset with region-description correspondence annotations for 10,410 studies of 7,321 unique patients. We evaluated our framework using grounding accuracy, the percentage of correctly localized anomalies, as a metric and demonstrated that the combination of the anatomical segmentation and the report structuring improves the performance with a large margin over the baseline model (66.0% vs 77.8%). Comparison with the prior techniques also showed higher performance of our method.
* 14 pages, 7 figures. Accepted at MICCAI 2023
Segmentation of Kidney Tumors on Non-Contrast CT Images using Protuberance Detection Network
Dec 08, 2023Many renal cancers are incidentally found on non-contrast CT (NCCT) images. On contrast-enhanced CT (CECT) images, most kidney tumors, especially renal cancers, have different intensity values compared to normal tissues. However, on NCCT images, some tumors called isodensity tumors, have similar intensity values to the surrounding normal tissues, and can only be detected through a change in organ shape. Several deep learning methods which segment kidney tumors from CECT images have been proposed and showed promising results. However, these methods fail to capture such changes in organ shape on NCCT images. In this paper, we present a novel framework, which can explicitly capture protruded regions in kidneys to enable a better segmentation of kidney tumors. We created a synthetic mask dataset that simulates a protuberance, and trained a segmentation network to separate the protruded regions from the normal kidney regions. To achieve the segmentation of whole tumors, our framework consists of three networks. The first network is a conventional semantic segmentation network which extracts a kidney region mask and an initial tumor region mask. The second network, which we name protuberance detection network, identifies the protruded regions from the kidney region mask. Given the initial tumor region mask and the protruded region mask, the last network fuses them and predicts the final kidney tumor mask accurately. The proposed method was evaluated on a publicly available KiTS19 dataset, which contains 108 NCCT images, and showed that our method achieved a higher dice score of 0.615 (+0.097) and sensitivity of 0.721 (+0.103) compared to 3D-UNet. To the best of our knowledge, this is the first deep learning method that is specifically designed for kidney tumor segmentation on NCCT images.
* Accepted in MICCAI 2023
Synthesizing Diverse Lung Nodules Wherever Massively: 3D Multi-Conditional GAN-based CT Image Augmentation for Object Detection
Jun 12, 2019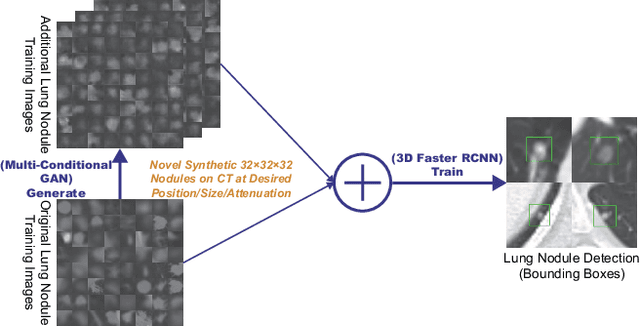
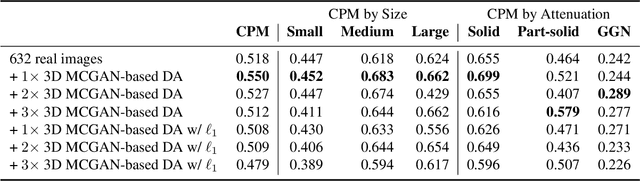
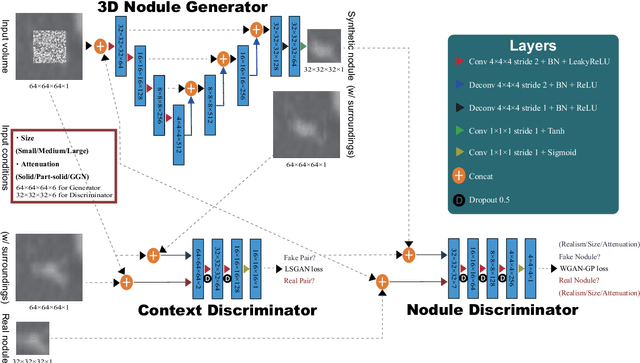
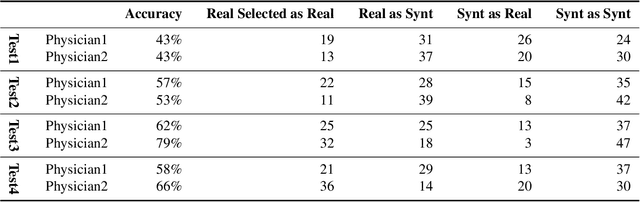
Accurate computer-assisted diagnosis, relying on large-scale annotated pathological images, can alleviate the risk of overlooking the diagnosis. Unfortunately, in medical imaging, most available datasets are small/fragmented. To tackle this, as a Data Augmentation (DA) method, 3D conditional Generative Adversarial Networks (GANs) can synthesize desired realistic/diverse 3D images as additional training data. However, no 3D conditional GAN-based DA approach exists for general bounding box-based 3D object detection, while it can locate disease areas with physicians' minimum annotation cost, unlike rigorous 3D segmentation. Moreover, since lesions vary in position/size/attenuation, further GAN-based DA performance requires multiple conditions. Therefore, we propose 3D Multi-Conditional GAN (MCGAN) to generate realistic/diverse 32 x 32 x 32 nodules placed naturally on lung Computed Tomography images to boost sensitivity in 3D object detection. Our MCGAN adopts two discriminators for conditioning: the context discriminator learns to classify real vs synthetic nodule/surrounding pairs with noise box-centered surroundings; the nodule discriminator attempts to classify real vs synthetic nodules with size/attenuation conditions. The results show that 3D Convolutional Neural Network-based detection can achieve higher sensitivity under any nodule size/attenuation at fixed False Positive rates and overcome the medical data paucity with the MCGAN-generated realistic nodules---even expert physicians fail to distinguish them from the real ones in Visual Turing Test.