 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Grounding of Whole Radiology Reports for 3D CT Images
Dec 08, 2023Building a large-scale training dataset is an essential problem in the development of medical image recognition systems. Visual grounding techniques, which automatically associate objects in images with corresponding descriptions, can facilitate labeling of large number of images. However, visual grounding of radiology reports for CT images remains challenging, because so many kinds of anomalies are detectable via CT imaging, and resulting report descriptions are long and complex. In this paper, we present the first visual grounding framework designed for CT image and report pairs covering various body parts and diverse anomaly types. Our framework combines two components of 1) anatomical segmentation of images, and 2) report structuring. The anatomical segmentation provides multiple organ masks of given CT images, and helps the grounding model recognize detailed anatomies. The report structuring helps to accurately extract information regarding the presence, location, and type of each anomaly described in corresponding reports. Given the two additional image/report features, the grounding model can achieve better localization. In the verification process, we constructed a large-scale dataset with region-description correspondence annotations for 10,410 studies of 7,321 unique patients. We evaluated our framework using grounding accuracy, the percentage of correctly localized anomalies, as a metric and demonstrated that the combination of the anatomical segmentation and the report structuring improves the performance with a large margin over the baseline model (66.0% vs 77.8%). Comparison with the prior techniques also showed higher performance of our method.
* 14 pages, 7 figures. Accepted at MICCAI 2023
Segmentation of Kidney Tumors on Non-Contrast CT Images using Protuberance Detection Network
Dec 08, 2023Many renal cancers are incidentally found on non-contrast CT (NCCT) images. On contrast-enhanced CT (CECT) images, most kidney tumors, especially renal cancers, have different intensity values compared to normal tissues. However, on NCCT images, some tumors called isodensity tumors, have similar intensity values to the surrounding normal tissues, and can only be detected through a change in organ shape. Several deep learning methods which segment kidney tumors from CECT images have been proposed and showed promising results. However, these methods fail to capture such changes in organ shape on NCCT images. In this paper, we present a novel framework, which can explicitly capture protruded regions in kidneys to enable a better segmentation of kidney tumors. We created a synthetic mask dataset that simulates a protuberance, and trained a segmentation network to separate the protruded regions from the normal kidney regions. To achieve the segmentation of whole tumors, our framework consists of three networks. The first network is a conventional semantic segmentation network which extracts a kidney region mask and an initial tumor region mask. The second network, which we name protuberance detection network, identifies the protruded regions from the kidney region mask. Given the initial tumor region mask and the protruded region mask, the last network fuses them and predicts the final kidney tumor mask accurately. The proposed method was evaluated on a publicly available KiTS19 dataset, which contains 108 NCCT images, and showed that our method achieved a higher dice score of 0.615 (+0.097) and sensitivity of 0.721 (+0.103) compared to 3D-UNet. To the best of our knowledge, this is the first deep learning method that is specifically designed for kidney tumor segmentation on NCCT images.
* Accepted in MICCAI 2023
Pushing the Envelope of Thin Crack Detection
Jan 09, 2021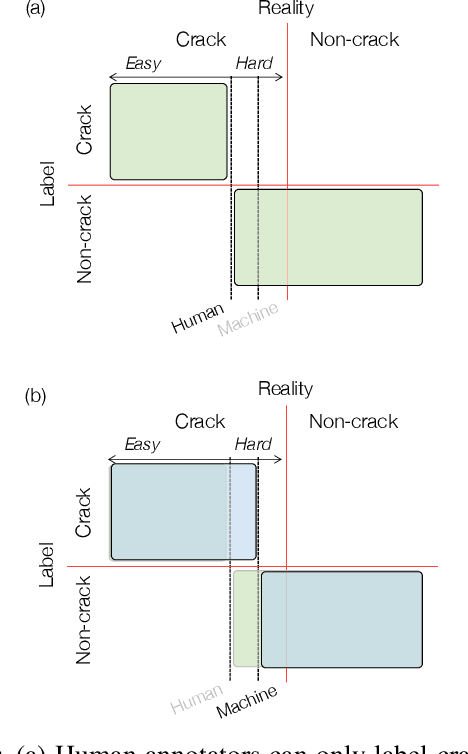
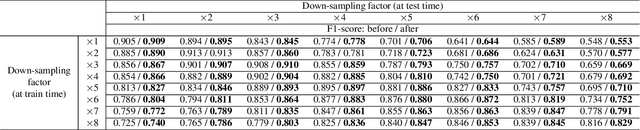

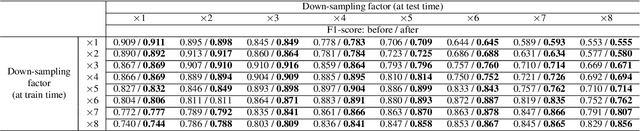
In this study, we consider the problem of detecting cracks from the image of a concrete surface for automated inspection of infrastructure, such as bridges. Its overall accuracy is determined by how accurately thin cracks with sub-pixel widths can be detected. Our interest is in making it possible to detect cracks close to the limit of thinness if it can be defined. Toward this end, we first propose a method for training a CNN to make it detect cracks more accurately than humans while training them on human-annotated labels. To achieve this seemingly impossible goal, we intentionally lower the spatial resolution of input images while maintaining that of their labels when training a CNN. This makes it possible to annotate cracks that are too thin for humans to detect, which we call super-human labels. We experimentally show that this makes it possible to detect cracks from an image of one-third the resolution of images used for annotation with about the same accuracy. We additionally propose three methods for further improving the detection accuracy of thin cracks: i) P-pooling to maintain small image structures during downsampling operations; ii) Removal of short-segment cracks in a post-processing step utilizing a prior of crack shapes learned using the VAE-GAN framework; iii) Modeling uncertainty of the prediction to better handle hard labels beyond the limit of CNNs' detection ability, which technically work as noisy labels. We experimentally examine the effectiveness of these methods.