 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Envelope of Thin Crack Detection
Paper and Code
Jan 09, 2021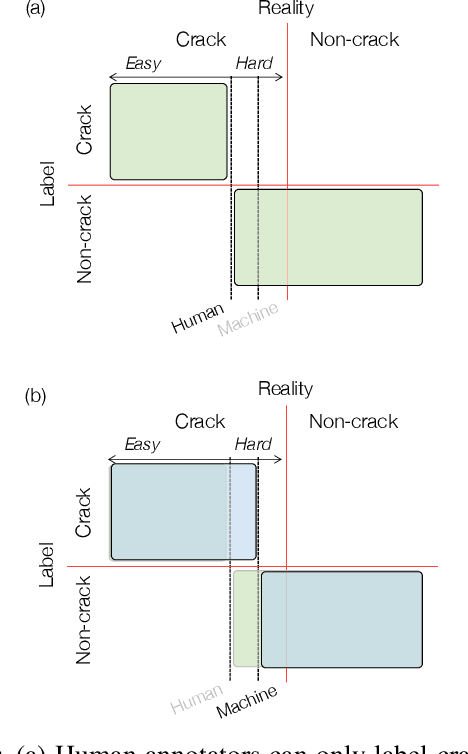
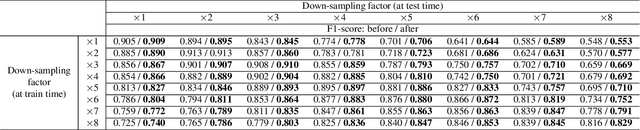

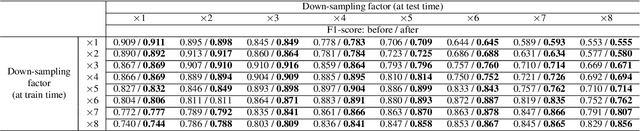
In this study, we consider the problem of detecting cracks from the image of a concrete surface for automated inspection of infrastructure, such as bridges. Its overall accuracy is determined by how accurately thin cracks with sub-pixel widths can be detected. Our interest is in making it possible to detect cracks close to the limit of thinness if it can be defined. Toward this end, we first propose a method for training a CNN to make it detect cracks more accurately than humans while training them on human-annotated labels. To achieve this seemingly impossible goal, we intentionally lower the spatial resolution of input images while maintaining that of their labels when training a CNN. This makes it possible to annotate cracks that are too thin for humans to detect, which we call super-human labels. We experimentally show that this makes it possible to detect cracks from an image of one-third the resolution of images used for annotation with about the same accuracy. We additionally propose three methods for further improving the detection accuracy of thin cracks: i) P-pooling to maintain small image structures during downsampling operations; ii) Removal of short-segment cracks in a post-processing step utilizing a prior of crack shapes learned using the VAE-GAN framework; iii) Modeling uncertainty of the prediction to better handle hard labels beyond the limit of CNNs' detection ability, which technically work as noisy labels. We experimentally examine the effectiveness of these methods.