 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Envelope of Thin Crack Detection
Jan 09, 2021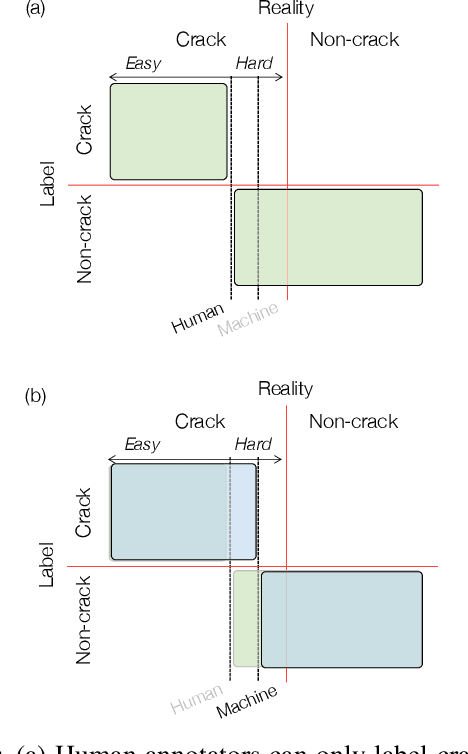
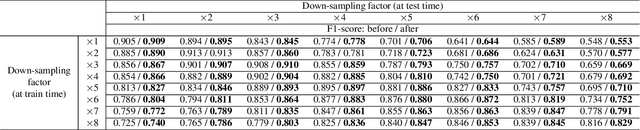

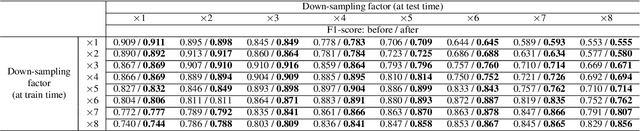
In this study, we consider the problem of detecting cracks from the image of a concrete surface for automated inspection of infrastructure, such as bridges. Its overall accuracy is determined by how accurately thin cracks with sub-pixel widths can be detected. Our interest is in making it possible to detect cracks close to the limit of thinness if it can be defined. Toward this end, we first propose a method for training a CNN to make it detect cracks more accurately than humans while training them on human-annotated labels. To achieve this seemingly impossible goal, we intentionally lower the spatial resolution of input images while maintaining that of their labels when training a CNN. This makes it possible to annotate cracks that are too thin for humans to detect, which we call super-human labels. We experimentally show that this makes it possible to detect cracks from an image of one-third the resolution of images used for annotation with about the same accuracy. We additionally propose three methods for further improving the detection accuracy of thin cracks: i) P-pooling to maintain small image structures during downsampling operations; ii) Removal of short-segment cracks in a post-processing step utilizing a prior of crack shapes learned using the VAE-GAN framework; iii) Modeling uncertainty of the prediction to better handle hard labels beyond the limit of CNNs' detection ability, which technically work as noisy labels. We experimentally examine the effectiveness of these methods.
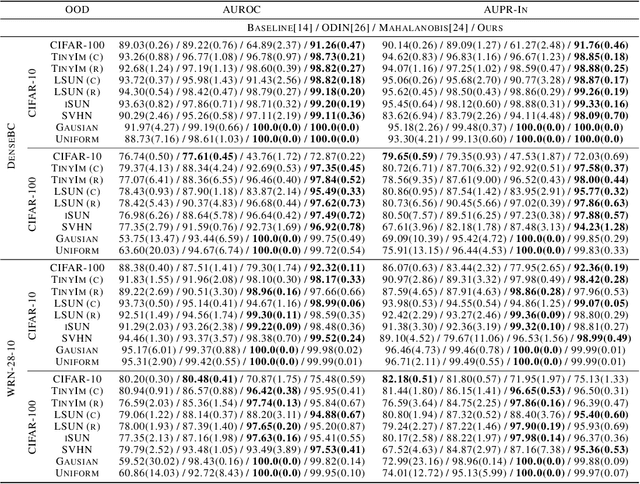
Bridging In- and Out-of-distribution Samples for Their Better Discriminability
Jan 07, 2021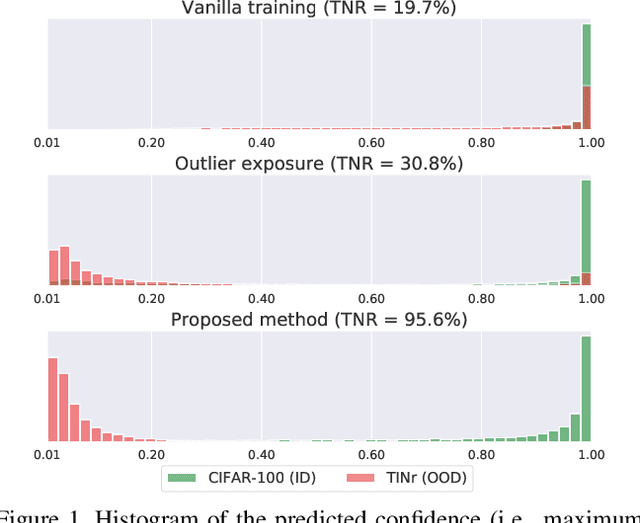
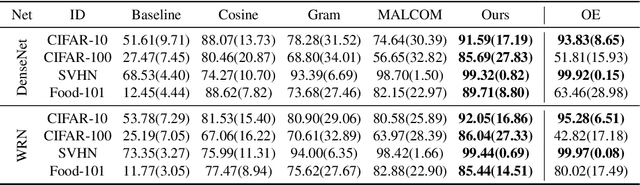

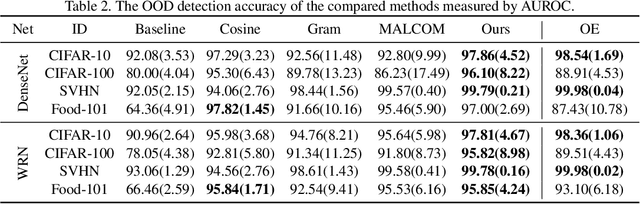
This paper proposes a method for OOD detection. Questioning the premise of previous studies that ID and OOD samples are separated distinctly, we consider samples lying in the intermediate of the two and use them for training a network. We generate such samples using multiple image transformations that corrupt inputs in various ways and with different severity levels. We estimate where the generated samples by a single image transformation lie between ID and OOD using a network trained on clean ID samples. To be specific, we make the network classify the generated samples and calculate their mean classification accuracy, using which we create a soft target label for them. We train the same network from scratch using the original ID samples and the generated samples with the soft labels created for them. We detect OOD samples by thresholding the entropy of the predicted softmax probability. The experimental results show that our method outperforms the previous state-of-the-art in the standard benchmark tests. We also analyze the effect of the number and particular combinations of image corrupting transformations on the performance.
Practical Evaluation of Out-of-Distribution Detection Methods for Image Classification
Jan 07, 2021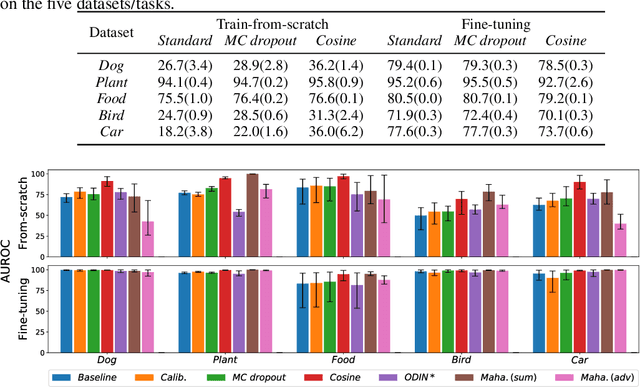
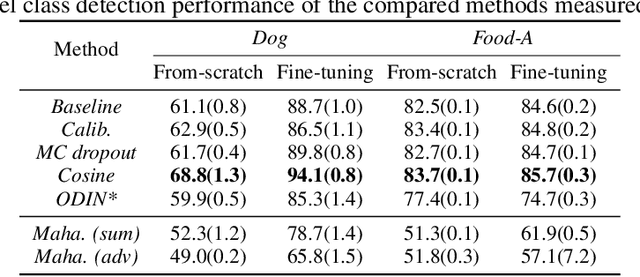
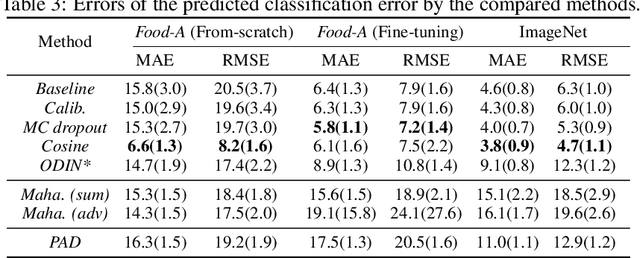
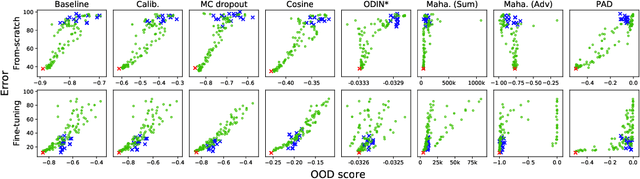
We reconsider the evaluation of OOD detection methods for image recognition. Although many studies have been conducted so far to build better OOD detection methods, most of them follow Hendrycks and Gimpel's work for the method of experimental evaluation. While the unified evaluation method is necessary for a fair comparison, there is a question of if its choice of tasks and datasets reflect real-world applications and if the evaluation results can generalize to other OOD detection application scenarios. In this paper, we experimentally evaluate the performance of representative OOD detection methods for three scenarios, i.e., irrelevant input detection, novel class detection, and domain shift detection, on various datasets and classification tasks. The results show that differences in scenarios and datasets alter the relative performance among the methods. Our results can also be used as a guide for practitioners for the selection of OOD detection methods.
Hyperparameter-Free Out-of-Distribution Detection Using Softmax of Scaled Cosine Similarity
May 25, 2019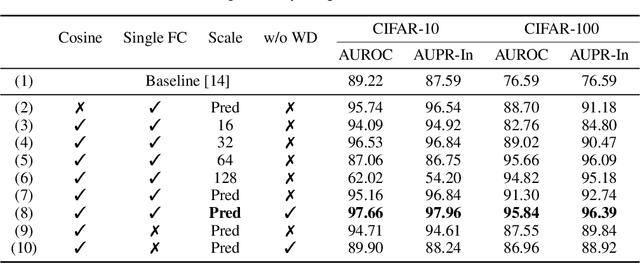
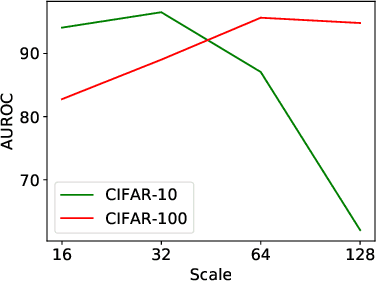

The ability of detecting out-of-distribution (OOD) samples is important to secure reliability of deep neural networks in real-world applications. Considering the nature of OOD samples, detection methods should not have hyperparameters whose optimal values vary sensitively depending on incoming OOD samples. This requirement is not met by many previous methods. In this paper, we propose a simple, hyperparameter-free method that is based on softmax of scaled cosine similarity. It resembles the approach employed by recent metric learning methods, but it differs in details; the differences are essential to achieve high detection performance. As compared with the current state-of-the-art methods, which needs hyperparameter tuning that could compromise real-world performance, the proposed method attains at least competitive detection accuracy even without (tuning of) a hyperparameter; furthermore, it is computationally more efficient, since it needs only a single forward pass unlike previous methods that need backpropagation for each input.