 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammar and Gameplay-aligned RL for Game Description Generation with LLMs
Mar 20, 2025Game Description Generation (GDG) is the task of generating a game description written in a Game Description Language (GDL) from natural language text. Previous studies have explored generation methods leveraging the contextual understanding capabilities of Large Language Models (LLMs); however, accurately reproducing the game features of the game descriptions remains a challenge. In this paper, we propose reinforcement learning-based fine-tuning of LLMs for GDG (RLGDG). Our training method simultaneously improves grammatical correctness and fidelity to game concepts by introducing both grammar rewards and concept rewards. Furthermore, we adopt a two-stage training strategy where Reinforcement Learning (RL) is applied following Supervised Fine-Tuning (SFT). Experimental results demonstrate that our proposed method significantly outperforms baseline methods using SFT alone.
Grammar-based Game Description Generation using Large Language Models
Jul 24, 2024



To lower the barriers to game design development, automated game design, which generates game designs through computational processes, has been explored. In automated game design, machine learning-based techniques such as evolutionary algorithms have achieved success. Benefiting from the remarkable advancements in deep learning, applications in computer vision and natural language processing have progressed in level generation. However, due to the limited amount of data in game design, the application of deep learning has been insufficient for tasks such as game description generation. To pioneer a new approach for handling limited data in automated game design, we focus on the in-context learning of large language models (LLMs). LLMs can capture the features of a task from a few demonstration examples and apply the capabilities acquired during pre-training. We introduce the grammar of game descriptions, which effectively structures the game design space, into the LLMs' reasoning process. Grammar helps LLMs capture the characteristics of the complex task of game description generation. Furthermore, we propose a decoding method that iteratively improves the generated output by leveraging the grammar. Our experiments demonstrate that this approach performs well in generating game descriptions.
Return-Aligned Decision Transformer
Feb 06, 2024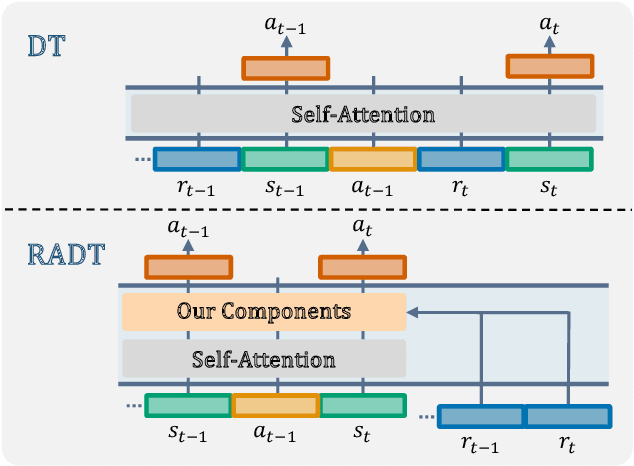
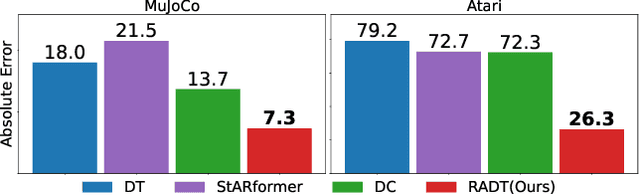
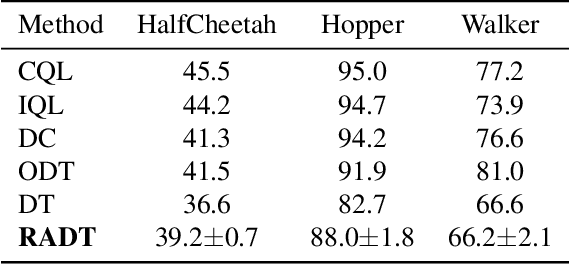
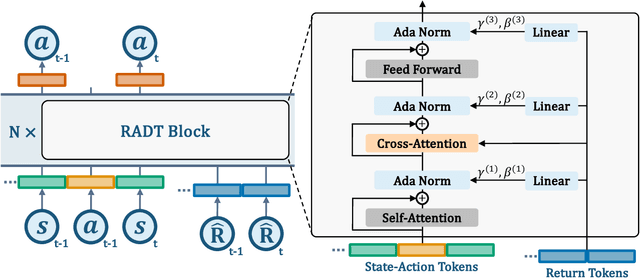
Traditional approaches in offline reinforcement learning aim to learn the optimal policy that maximizes the cumulative reward, also known as return. However, as applications broaden, it becomes increasingly crucial to train agents that not only maximize the returns, but align the actual return with a specified target return, giving control over the agent's performance. Decision Transformer (DT) optimizes a policy that generates actions conditioned on the target return through supervised learning and is equipped with a mechanism to control the agent using the target return. Despite being designed to align the actual return with the target return, we have empirically identified a discrepancy between the actual return and the target return in DT. In this paper, we propose Return-Aligned Decision Transformer (RADT), designed to effectively align the actual return with the target return. Our model decouples returns from the conventional input sequence, which typically consists of returns, states, and actions, to enhance the relationships between returns and states, as well as returns and actions. Extensive experiments show that RADT reduces the discrepancies between the actual return and the target return of DT-based methods.
DiffG-RL: Leveraging Difference between State and Common Sense
Nov 29, 2022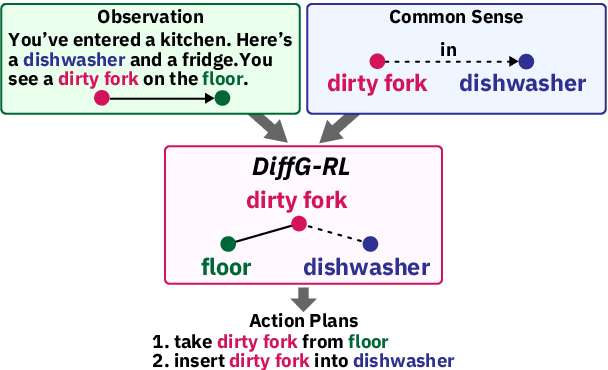
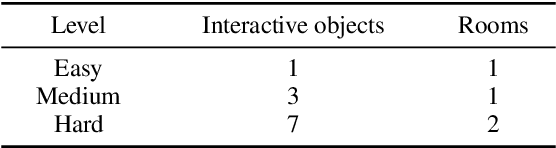
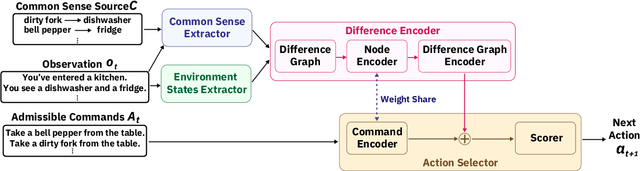
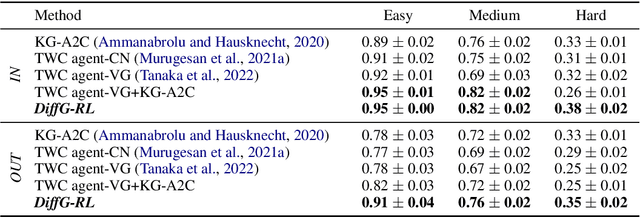
Taking into account background knowledge as the context has always been an important part of solving tasks that involve natural language. One representative example of such tasks is text-based games, where players need to make decisions based on both description text previously shown in the game, and their own background knowledge about the language and common sense. In this work, we investigate not simply giving common sense, as can be seen in prior research, but also its effective usage. We assume that a part of the environment states different from common sense should constitute one of the grounds for action selection. We propose a novel agent, DiffG-RL, which constructs a Difference Graph that organizes the environment states and common sense by means of interactive objects with a dedicated graph encoder. DiffG-RL also contains a framework for extracting the appropriate amount and representation of common sense from the source to support the construction of the graph. We validate DiffG-RL in experiments with text-based games that require common sense and show that it outperforms baselines by 17% of scores. The code is available at https://github.com/ibm/diffg-rl