 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatroid Semi-Bandits in Sublinear Time
May 28, 2024We study the matroid semi-bandits problem, where at each round the learner plays a subset of $K$ arms from a feasible set, and the goal is to maximize the expected cumulative linear rewards. Existing algorithms have per-round time complexity at least $\Omega(K)$, which becomes expensive when $K$ is large. To address this computational issue, we propose FasterCUCB whose sampling rule takes time sublinear in $K$ for common classes of matroids: $O(D\text{ polylog}(K)\text{ polylog}(T))$ for uniform matroids, partition matroids, and graphical matroids, and $O(D\sqrt{K}\text{ polylog}(T))$ for transversal matroids. Here, $D$ is the maximum number of elements in any feasible subset of arms, and $T$ is the horizon. Our technique is based on dynamic maintenance of an approximate maximum-weight basis over inner-product weights. Although the introduction of an approximate maximum-weight basis presents a challenge in regret analysis, we can still guarantee an upper bound on regret as tight as CUCB in the sense that it matches the gap-dependent lower bound by Kveton et al. (2014a) asymptotically.
Fast and Examination-agnostic Reciprocal Recommendation in Matching Markets
Jun 15, 2023In matching markets such as job posting and online dating platforms, the recommender system plays a critical role in the success of the platform. Unlike standard recommender systems that suggest items to users, reciprocal recommender systems (RRSs) that suggest other users must take into account the mutual interests of users. In addition, ensuring that recommendation opportunities do not disproportionately favor popular users is essential for the total number of matches and for fairness among users. Existing recommendation methods in matching markets, however, face computational challenges on large-scale platforms and depend on specific examination functions in the position-based model (PBM). In this paper, we introduce the reciprocal recommendation method based on the matching with transferable utility (TU matching) model in the context of ranking recommendations in matching markets and propose a fast and examination-model-free algorithm. Furthermore, we evaluate our approach on experiments with synthetic data and real-world data from an online dating platform in Japan. Our method performs better than or as well as existing methods in terms of the total number of matches and works well even in a large-scale dataset for which one existing method does not work.
Safe Collaborative Filtering
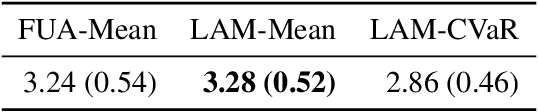
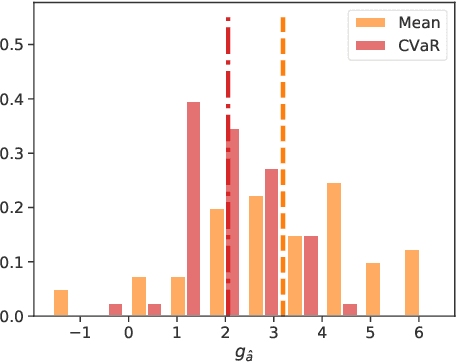
Jun 08, 2023Excellent tail performance is crucial for modern machine learning tasks, such as algorithmic fairness, class imbalance, and risk-sensitive decision making, as it ensures the effective handling of challenging samples within a dataset. Tail performance is also a vital determinant of success for personalised recommender systems to reduce the risk of losing users with low satisfaction. This study introduces a "safe" collaborative filtering method that prioritises recommendation quality for less-satisfied users rather than focusing on the average performance. Our approach minimises the conditional value at risk (CVaR), which represents the average risk over the tails of users' loss. To overcome computational challenges for web-scale recommender systems, we develop a robust yet practical algorithm that extends the most scalable method, implicit alternating least squares (iALS). Empirical evaluation on real-world datasets demonstrates the excellent tail performance of our approach while maintaining competitive computational efficiency.
Curse of "Low" Dimensionality in Recommender Systems
May 23, 2023Beyond accuracy, there are a variety of aspects to the quality of recommender systems, such as diversity, fairness, and robustness. We argue that many of the prevalent problems in recommender systems are partly due to low-dimensionality of user and item embeddings, particularly when dot-product models, such as matrix factorization, are used. In this study, we showcase empirical evidence suggesting the necessity of sufficient dimensionality for user/item embeddings to achieve diverse, fair, and robust recommendation. We then present theoretical analyses of the expressive power of dot-product models. Our theoretical results demonstrate that the number of possible rankings expressible under dot-product models is exponentially bounded by the dimension of item factors. We empirically found that the low-dimensionality contributes to a popularity bias, widening the gap between the rank positions of popular and long-tail items; we also give a theoretical justification for this phenomenon.
A Critical Reexamination of Intra-List Distance and Dispersion
May 23, 2023Diversification of recommendation results is a promising approach for coping with the uncertainty associated with users' information needs. Of particular importance in diversified recommendation is to define and optimize an appropriate diversity objective. In this study, we revisit the most popular diversity objective called intra-list distance (ILD), defined as the average pairwise distance between selected items, and a similar but lesser known objective called dispersion, which is the minimum pairwise distance. Owing to their simplicity and flexibility, ILD and dispersion have been used in a plethora of diversified recommendation research. Nevertheless, we do not actually know what kind of items are preferred by them. We present a critical reexamination of ILD and dispersion from theoretical and experimental perspectives. Our theoretical results reveal that these objectives have potential drawbacks: ILD may select duplicate items that are very close to each other, whereas dispersion may overlook distant item pairs. As a competitor to ILD and dispersion, we design a diversity objective called Gaussian ILD, which can interpolate between ILD and dispersion by tuning the bandwidth parameter. We verify our theoretical results by experimental results using real-world data and confirm the extreme behavior of ILD and dispersion in practice.
Computational Complexity of Normalizing Constants for the Product of Determinantal Point Processes
Nov 28, 2021
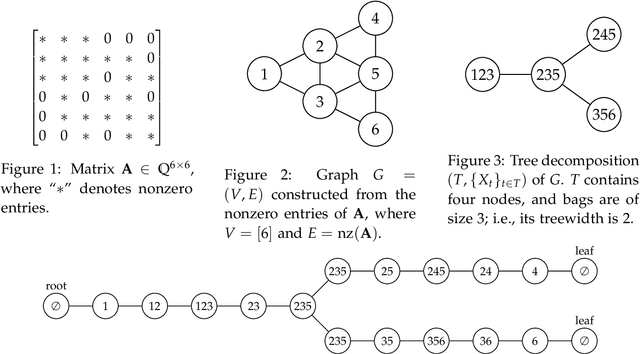
We consider the product of determinantal point processes (DPPs), a point process whose probability mass is proportional to the product of principal minors of multiple matrices, as a natural, promising generalization of DPPs. We study the computational complexity of computing its normalizing constant, which is among the most essential probabilistic inference tasks. Our complexity-theoretic results (almost) rule out the existence of efficient algorithms for this task unless the input matrices are forced to have favorable structures. In particular, we prove the following: (1) Computing $\sum_S\det({\bf A}_{S,S})^p$ exactly for every (fixed) positive even integer $p$ is UP-hard and Mod$_3$P-hard, which gives a negative answer to an open question posed by Kulesza and Taskar. (2) $\sum_S\det({\bf A}_{S,S})\det({\bf B}_{S,S})\det({\bf C}_{S,S})$ is NP-hard to approximate within a factor of $2^{O(|I|^{1-\epsilon})}$ or $2^{O(n^{1/\epsilon})}$ for any $\epsilon>0$, where $|I|$ is the input size and $n$ is the order of the input matrix. This result is stronger than the #P-hardness for the case of two matrices derived by Gillenwater. (3) There exists a $k^{O(k)}n^{O(1)}$-time algorithm for computing $\sum_S\det({\bf A}_{S,S})\det({\bf B}_{S,S})$, where $k$ is the maximum rank of $\bf A$ and $\bf B$ or the treewidth of the graph formed by nonzero entries of $\bf A$ and $\bf B$. Such parameterized algorithms are said to be fixed-parameter tractable. These results can be extended to the fixed-size case. Further, we present two applications of fixed-parameter tractable algorithms given a matrix $\bf A$ of treewidth $w$: (4) We can compute a $2^{\frac{n}{2p-1}}$-approximation to $\sum_S\det({\bf A}_{S,S})^p$ for any fractional number $p>1$ in $w^{O(wp)}n^{O(1)}$ time. (5) We can find a $2^{\sqrt n}$-approximation to unconstrained MAP inference in $w^{O(w\sqrt n)}n^{O(1)}$ time.
Some Inapproximability Results of MAP Inference and Exponentiated Determinantal Point Processes
Sep 02, 2021

We study the computational complexity of two hard problems on determinantal point processes (DPPs). One is maximum a posteriori (MAP) inference, i.e., to find a principal submatrix having the maximum determinant. The other is probabilistic inference on exponentiated DPPs (E-DPPs), which can sharpen or weaken the diversity preference of DPPs with an exponent parameter $p$. We prove the following complexity-theoretic hardness results that explain the difficulty in approximating MAP inference and the normalizing constant for E-DPPs. 1. Unconstrained MAP inference for an $n \times n$ matrix is NP-hard to approximate within a factor of $2^{\beta n}$, where $\beta = 10^{-10^{13}} $. This result improves upon a $(\frac{9}{8}-\epsilon)$-factor inapproximability given by Kulesza and Taskar (2012). 2. Log-determinant maximization is NP-hard to approximate within a factor of $\frac{5}{4}$ for the unconstrained case and within a factor of $1+10^{-10^{13}}$ for the size-constrained monotone case. 3. The normalizing constant for E-DPPs of any (fixed) constant exponent $p \geq \beta^{-1} = 10^{10^{13}}$ is NP-hard to approximate within a factor of $2^{\beta pn}$. This gives a(nother) negative answer to open questions posed by Kulesza and Taskar (2012); Ohsaka and Matsuoka (2020).
Spanning Tree Constrained Determinantal Point Processes are Hard to (Approximately) Evaluate
Feb 25, 2021
We consider determinantal point processes (DPPs) constrained by spanning trees. Given a graph $G=(V,E)$ and a positive semi-definite matrix $\mathbf{A}$ indexed by $E$, a spanning-tree DPP defines a distribution such that we draw $S\subseteq E$ with probability proportional to $\det(\mathbf{A}_S)$ only if $S$ induces a spanning tree. We prove $\sharp\textsf{P}$-hardness of computing the normalizing constant for spanning-tree DPPs and provide an approximation-preserving reduction from the mixed discriminant, for which FPRAS is not known. We show similar results for DPPs constrained by forests.
Predictive Optimization with Zero-Shot Domain Adaptation
Jan 15, 2021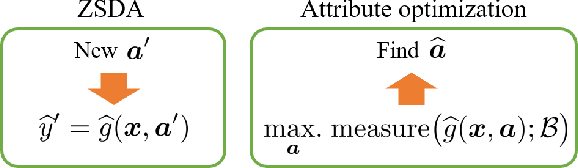

Prediction in a new domain without any training sample, called zero-shot domain adaptation (ZSDA), is an important task in domain adaptation. While prediction in a new domain has gained much attention in recent years, in this paper, we investigate another potential of ZSDA. Specifically, instead of predicting responses in a new domain, we find a description of a new domain given a prediction. The task is regarded as predictive optimization, but existing predictive optimization methods have not been extended to handling multiple domains. We propose a simple framework for predictive optimization with ZSDA and analyze the condition in which the optimization problem becomes convex optimization. We also discuss how to handle the interaction of characteristics of a domain in predictive optimization. Through numerical experiments, we demonstrate the potential usefulness of our proposed framework.