 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShift Before You Learn: Enabling Low-Rank Representations in Reinforcement Learning
Sep 05, 2025Low-rank structure is a common implicit assumption in many modern reinforcement learning (RL) algorithms. For instance, reward-free and goal-conditioned RL methods often presume that the successor measure admits a low-rank representation. In this work, we challenge this assumption by first remarking that the successor measure itself is not low-rank. Instead, we demonstrate that a low-rank structure naturally emerges in the shifted successor measure, which captures the system dynamics after bypassing a few initial transitions. We provide finite-sample performance guarantees for the entry-wise estimation of a low-rank approximation of the shifted successor measure from sampled entries. Our analysis reveals that both the approximation and estimation errors are primarily governed by the so-called spectral recoverability of the corresponding matrix. To bound this parameter, we derive a new class of functional inequalities for Markov chains that we call Type II Poincar\'e inequalities and from which we can quantify the amount of shift needed for effective low-rank approximation and estimation. This analysis shows in particular that the required shift depends on decay of the high-order singular values of the shifted successor measure and is hence typically small in practice. Additionally, we establish a connection between the necessary shift and the local mixing properties of the underlying dynamical system, which provides a natural way of selecting the shift. Finally, we validate our theoretical findings with experiments, and demonstrate that shifting the successor measure indeed leads to improved performance in goal-conditioned RL.
Model-free Low-Rank Reinforcement Learning via Leveraged Entry-wise Matrix Estimation
Oct 30, 2024We consider the problem of learning an $\varepsilon$-optimal policy in controlled dynamical systems with low-rank latent structure. For this problem, we present LoRa-PI (Low-Rank Policy Iteration), a model-free learning algorithm alternating between policy improvement and policy evaluation steps. In the latter, the algorithm estimates the low-rank matrix corresponding to the (state, action) value function of the current policy using the following two-phase procedure. The entries of the matrix are first sampled uniformly at random to estimate, via a spectral method, the leverage scores of its rows and columns. These scores are then used to extract a few important rows and columns whose entries are further sampled. The algorithm exploits these new samples to complete the matrix estimation using a CUR-like method. For this leveraged matrix estimation procedure, we establish entry-wise guarantees that remarkably, do not depend on the coherence of the matrix but only on its spikiness. These guarantees imply that LoRa-PI learns an $\varepsilon$-optimal policy using $\widetilde{O}({S+A\over \mathrm{poly}(1-\gamma)\varepsilon^2})$ samples where $S$ (resp. $A$) denotes the number of states (resp. actions) and $\gamma$ the discount factor. Our algorithm achieves this order-optimal (in $S$, $A$ and $\varepsilon$) sample complexity under milder conditions than those assumed in previously proposed approaches.
Low-Rank Bandits via Tight Two-to-Infinity Singular Subspace Recovery
Feb 24, 2024We study contextual bandits with low-rank structure where, in each round, if the (context, arm) pair $(i,j)\in [m]\times [n]$ is selected, the learner observes a noisy sample of the $(i,j)$-th entry of an unknown low-rank reward matrix. Successive contexts are generated randomly in an i.i.d. manner and are revealed to the learner. For such bandits, we present efficient algorithms for policy evaluation, best policy identification and regret minimization. For policy evaluation and best policy identification, we show that our algorithms are nearly minimax optimal. For instance, the number of samples required to return an $\varepsilon$-optimal policy with probability at least $1-\delta$ typically scales as ${m+n\over \varepsilon^2}\log(1/\delta)$. Our regret minimization algorithm enjoys minimax guarantees scaling as $r^{7/4}(m+n)^{3/4}\sqrt{T}$, which improves over existing algorithms. All the proposed algorithms consist of two phases: they first leverage spectral methods to estimate the left and right singular subspaces of the low-rank reward matrix. We show that these estimates enjoy tight error guarantees in the two-to-infinity norm. This in turn allows us to reformulate our problems as a misspecified linear bandit problem with dimension roughly $r(m+n)$ and misspecification controlled by the subspace recovery error, as well as to design the second phase of our algorithms efficiently.
Spectral Entry-wise Matrix Estimation for Low-Rank Reinforcement Learning
Oct 10, 2023We study matrix estimation problems arising in reinforcement learning (RL) with low-rank structure. In low-rank bandits, the matrix to be recovered specifies the expected arm rewards, and for low-rank Markov Decision Processes (MDPs), it may for example characterize the transition kernel of the MDP. In both cases, each entry of the matrix carries important information, and we seek estimation methods with low entry-wise error. Importantly, these methods further need to accommodate for inherent correlations in the available data (e.g. for MDPs, the data consists of system trajectories). We investigate the performance of simple spectral-based matrix estimation approaches: we show that they efficiently recover the singular subspaces of the matrix and exhibit nearly-minimal entry-wise error. These new results on low-rank matrix estimation make it possible to devise reinforcement learning algorithms that fully exploit the underlying low-rank structure. We provide two examples of such algorithms: a regret minimization algorithm for low-rank bandit problems, and a best policy identification algorithm for reward-free RL in low-rank MDPs. Both algorithms yield state-of-the-art performance guarantees.
Tight bounds for maximum $\ell_1$-margin classifiers
Dec 07, 2022Popular iterative algorithms such as boosting methods and coordinate descent on linear models converge to the maximum $\ell_1$-margin classifier, a.k.a. sparse hard-margin SVM, in high dimensional regimes where the data is linearly separable. Previous works consistently show that many estimators relying on the $\ell_1$-norm achieve improved statistical rates for hard sparse ground truths. We show that surprisingly, this adaptivity does not apply to the maximum $\ell_1$-margin classifier for a standard discriminative setting. In particular, for the noiseless setting, we prove tight upper and lower bounds for the prediction error that match existing rates of order $\frac{\|\wgt\|_1^{2/3}}{n^{1/3}}$ for general ground truths. To complete the picture, we show that when interpolating noisy observations, the error vanishes at a rate of order $\frac{1}{\sqrt{\log(d/n)}}$. We are therefore first to show benign overfitting for the maximum $\ell_1$-margin classifier.
Fast rates for noisy interpolation require rethinking the effects of inductive bias
Mar 07, 2022
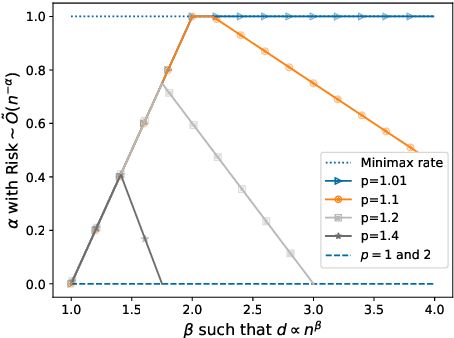
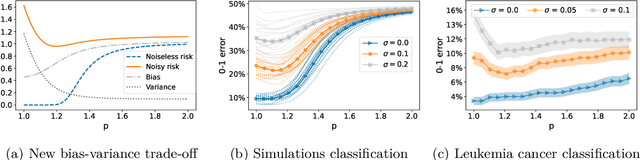

Good generalization performance on high-dimensional data crucially hinges on a simple structure of the ground truth and a corresponding strong inductive bias of the estimator. Even though this intuition is valid for regularized models, in this paper we caution against a strong inductive bias for interpolation in the presence of noise: Our results suggest that, while a stronger inductive bias encourages a simpler structure that is more aligned with the ground truth, it also increases the detrimental effect of noise. Specifically, for both linear regression and classification with a sparse ground truth, we prove that minimum $\ell_p$-norm and maximum $\ell_p$-margin interpolators achieve fast polynomial rates up to order $1/n$ for $p > 1$ compared to a logarithmic rate for $p = 1$. Finally, we provide experimental evidence that this trade-off may also play a crucial role in understanding non-linear interpolating models used in practice.