 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimal Antenna Tilt Control Policies: A Contextual Linear Bandit Approach
Paper and Code
Jan 06, 2022
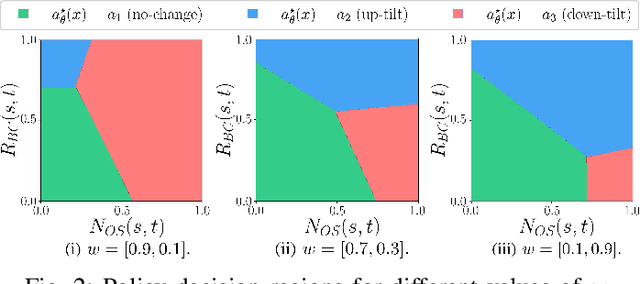
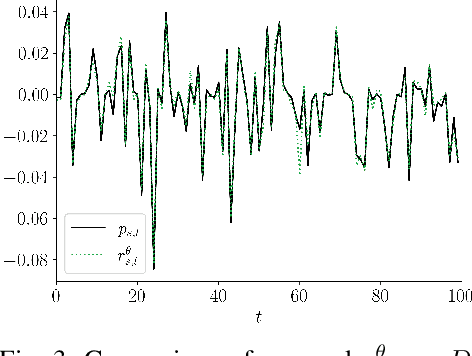
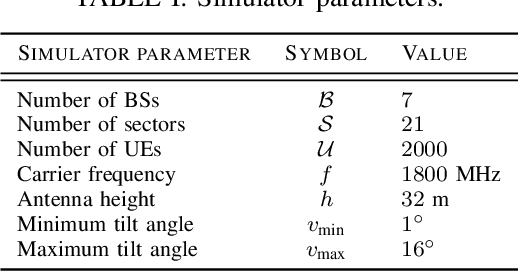
Controlling antenna tilts in cellular networks is imperative to reach an efficient trade-off between network coverage and capacity. In this paper, we devise algorithms learning optimal tilt control policies from existing data (in the so-called passive learning setting) or from data actively generated by the algorithms (the active learning setting). We formalize the design of such algorithms as a Best Policy Identification (BPI) problem in Contextual Linear Multi-Arm Bandits (CL-MAB). An arm represents an antenna tilt update; the context captures current network conditions; the reward corresponds to an improvement of performance, mixing coverage and capacity; and the objective is to identify, with a given level of confidence, an approximately optimal policy (a function mapping the context to an arm with maximal reward). For CL-MAB in both active and passive learning settings, we derive information-theoretical lower bounds on the number of samples required by any algorithm returning an approximately optimal policy with a given level of certainty, and devise algorithms achieving these fundamental limits. We apply our algorithms to the Remote Electrical Tilt (RET) optimization problem in cellular networks, and show that they can produce optimal tilt update policy using much fewer data samples than naive or existing rule-based learning algorithms.